Downloaden Sie, um offline zu lesen





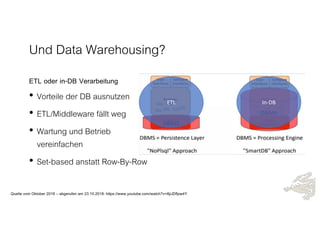

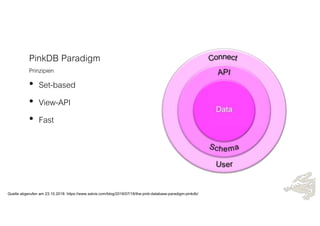
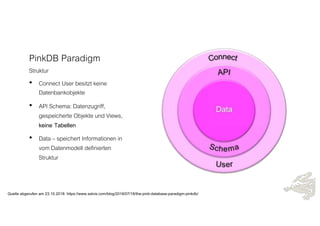
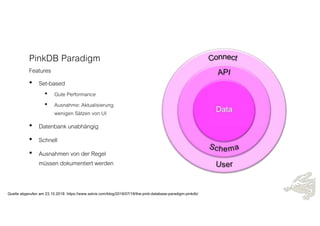
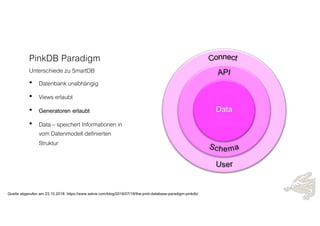
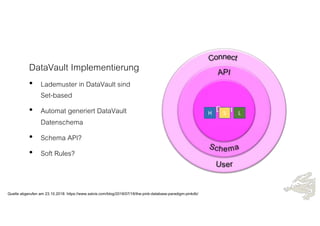
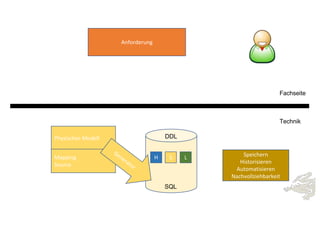
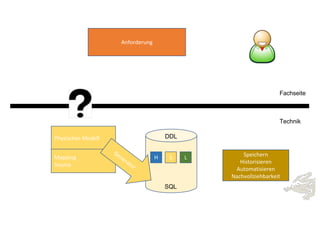
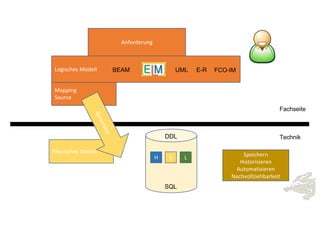
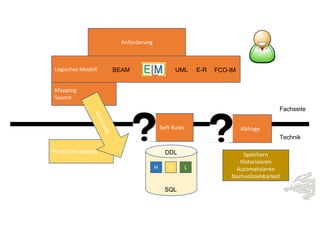
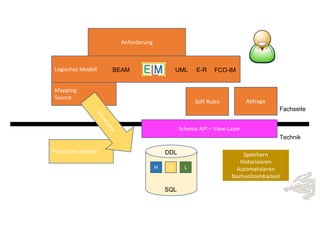
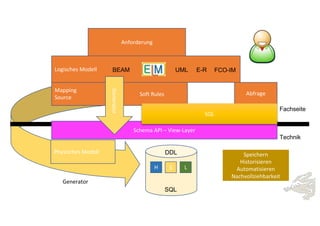
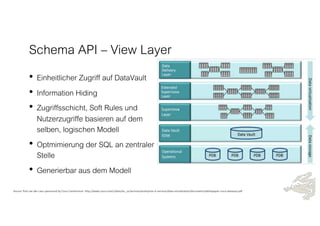



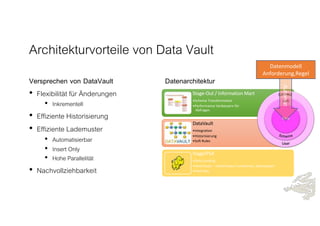



Das Dokument behandelt die Prinzipien von PinkDB und deren Anwendung in einer Data Vault Datenarchitektur, indem es den Fokus auf modelgetriebene Entwicklung und set-basierte Verarbeitung legt. Es hebt die Vorteile von PinkDB wie Flexibilität, Effizienz in der Historisierung und Automatisierung hervor sowie die Notwendigkeit, Middleware und traditionelle ETL-Prozesse zu überdenken. Zentral ist die Vereinfachung der Infrastruktur und die Kostenreduktion durch eine solidere Datenbankarchitektur, die auf SQL und relationale Stärken setzt.













