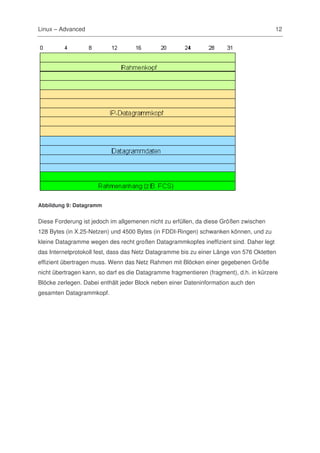
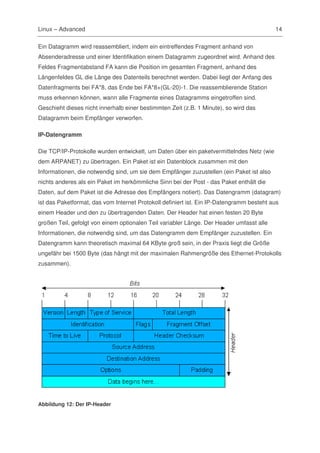
Das Dokument behandelt fortgeschrittene Themen zu Linux-Serverdiensten und Netzwerküberwachung, insbesondere im Zusammenhang mit der Konzeption, Installation und Verwaltung von Serverdiensten wie DHCP, DNS, und NFS. Es werden sowohl theoretische Grundlagen, einschließlich TCP/IP- und OSI-Referenzmodelle, als auch praktische Anleitungen zur Einrichtung und Fehlerbehebung für Schulen gegeben. Zudem wird betont, dass viele beschriebene Werkzeuge und Methoden auch unter Windows anwendbar sind.



































































































![Linux – Advanced 101
4 Netzwerk Monitoring
4.1 ifconfig
Ifconfig dient dazu, eine Schnittstelle für die Netzwerkschicht des Kernels sichtbar zu
machen. Das beinhaltet die Zuweisung einer IP-Adresse und verschiedener anderer
Parameter, sowie die Aktivierung (“bringing up”) der Schnittstelle, damit der Kernel die IP-
Pakete über diese Schnittstelle senden und empfangen kann.
/ # ifconfig
Ifconfig alleine gibt alle Informationen über die aktiven Schnittstellen aus. Allgemein sieht der
Syntax wie folgt aus:
/ # ifconfig interface [address [parameters]]
Das Beispiel unten weist dem Interface lo die IP-Adresse 127.0.0.2 zu.
/ # ifconfig lo 127.0.0.2
Tabelle 13: ifconfig parameter
up Diese Option aktiviert ein Interface für die IP-Schicht des Kernels. Sie wird
impliziert, wenn auf der Kommandozeile eine Adresse angegeben ist. Sie kann
auch dazu benutzt werden, ein Interface zu reaktivieren, wenn es mit der down-
Option temporär deaktiviert wurde.
Diese Option entspricht den Flags UP und RUNNING.
down Diese Option markiert eine Schnittstelle als inaktiv, d.h. unzugänglich für die
Netzwerkschicht. Dadurch wird jeglicher IP-Transport durch die Schnittstelle
unterbunden. Beachten Sie, dass dadurch automatisch alle Routing-Einträge
gelöscht werden, die diese Schnittstelle verwenden.
Netzmaske Diese Option weist der Schnittstelle eine Subnetzmaske zu. Sie kann entweder
Maske als eine 32-Bit-Hexadezimalzahl (mit führender 0x) oder in Dezimaldarstellung
(Beispiel: 255.255.255.0) angegeben werden. Während diese als “dotted quad”
bezeichnete Notation häufiger benutzt wird, ist die hexadezimale Darstellung
oft einfacher zu handhaben. Netzmasken sind grundsätzlich binär und es ist](https://image.slidesharecdn.com/linuxadvanced-110110110633-phpapp02/85/Linux-advanced-102-320.jpg)









![Linux – Advanced 111
aktiv ausgewiesen werden.
-sU UDP-Scans: Diese Methode wird stets dann herangezogen, wenn es um
das Identifizieren der offenen UDP-Ports (siehe RFC 768) eines Systems
geht. Diese Technik basiert darauf, dass ein UDP- Datagramm mit 0 Byte
an Nutzdaten an jeden Port des Zielsystems geschickt wird. Erhalten wir
eine ICMP port unreachable- Nachricht, so ist der Zielport geschlossen.
Andererseits handelt es sich um einen offenen Port.
-sI <Zombie- Idlescan: Diese erweiterte Scan-Technik ermöglicht ein blindes Scannen
Host[:Zielport]> der TCP-Port eines Ziels (dies bedeutet, dass keinerlei Pakete mit der
richtigen IP-Absenderadresse verschickt werden). Stattdessen wird eine
einzigartige Attacke angewandt, die die Berechenbarkeit der IP
Fragmentation ID eines Zombie-Hosts ausnutzt.
nmap greift zudem auf eine sehr mächtige Notation zurück, die eine sehr komfortable
Spezifikation von IP-Adressbereichen zulässt. So kann das Klasse B-Netzwerk 192.168.*.*
mit der Angabe von ’192.168.*.*’ oder ’192.168.0-255.0-255’ oder ’192.168.1-50,51-
255.1,2,3,4,5-255’ gescannt werden. Und selbstverständlich ist auch die verbreitete Netz-
masken-Notation zulässig: ’192.168.0.0/16’. All diese Eingaben führen zum gleichen Ziel.
Tabelle 17: nmap generelle Optionen
-O Diese Option aktiviert das Identifizieren des am Zielsystem eingesetzten
Betriebssystems anhand des TCP/IP-Fingerabdrucks (TCP/IP
fingerprint). Es wird eine Anzahl spezifischer Tests umgesetzt, die das
typische Verhalten der jeweiligen TCP/IP-Implementierungen erkennen
können sollen. Die gegebenen Informationen stellen quasi einen
’Fingerabdruck’ dar, der mit der Datenbank der bekannten
Betriebssystem-Fingerabdrucke (die nmap-os-fingerprints Datei)
verglichen wird.
-v Verbose-Modus: Diese Option ermöglicht eine erweiterte Ausgabe von
Informationen. Eine doppelte Nutzung ergibt einen doppelt so großen
Effekt. Ebenso kann -d einige Male aktiviert werden, falls Sie wirklich vor](https://image.slidesharecdn.com/linuxadvanced-110110110633-phpapp02/85/Linux-advanced-112-320.jpg)
































![[DE] Dr. Ulrich Kampffmeyer - Artikel auf Wikipedia | 2015](https://cdn.slidesharecdn.com/ss_thumbnails/ulrichkampffmeyerartikelaufwikipedia2015-160322133808-thumbnail.jpg?width=640&height=640&fit=bounds)

























































