Als ODP, PPTX herunterladen















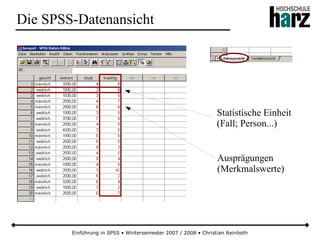
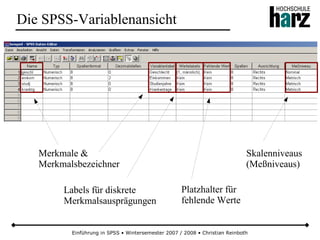

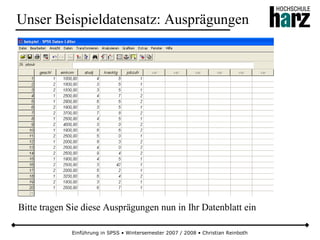


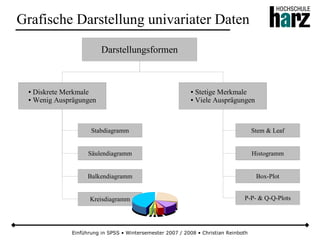
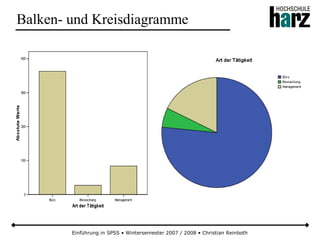
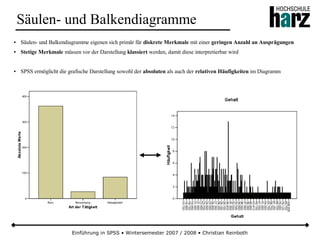


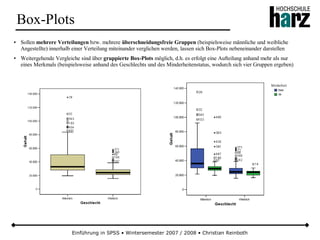

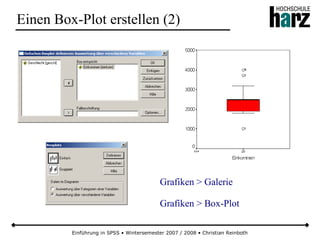
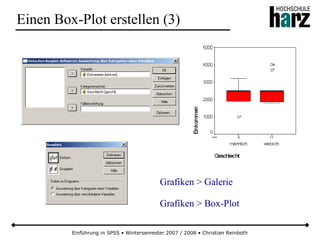
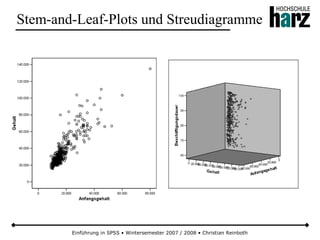


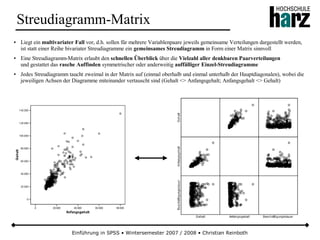
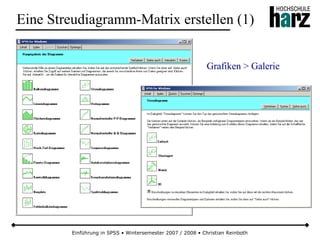
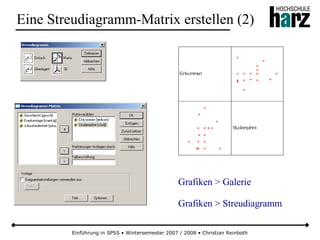
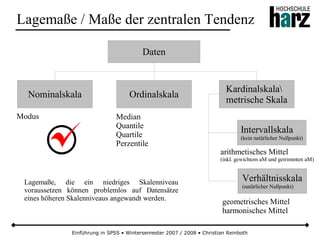
















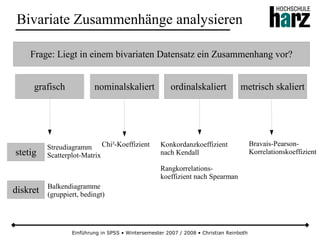
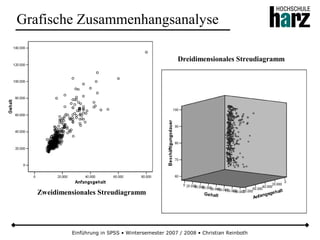
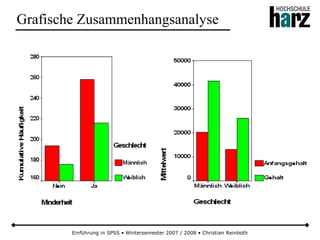


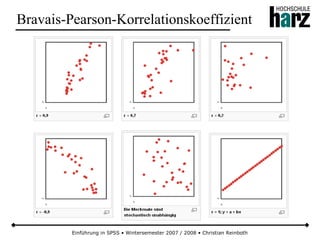







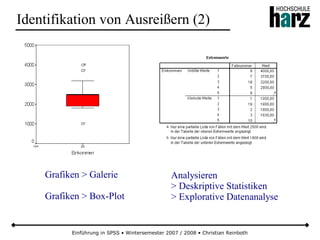
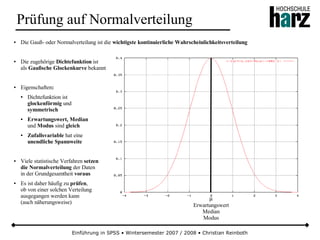
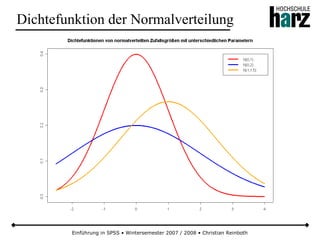
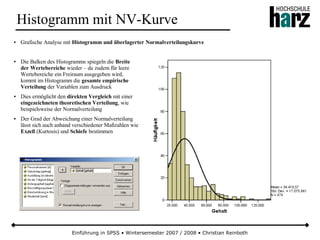








![Einführung in SPSS • Wintersemester 2007 / 2008 • Christian Reinboth
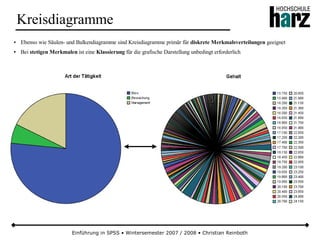
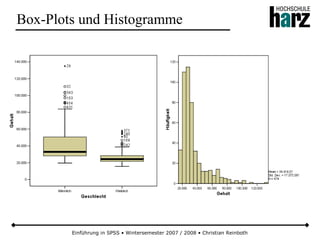
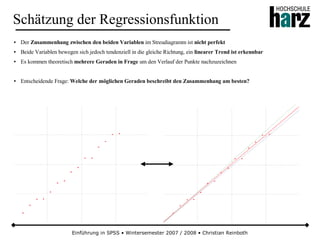
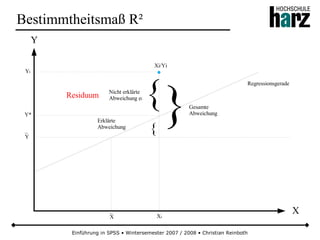
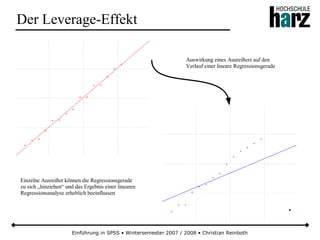
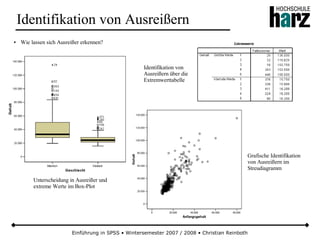
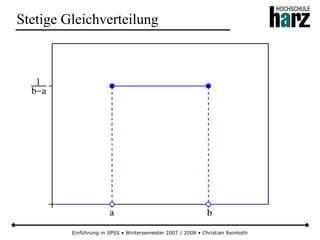
Stetige Gleichverteilung
● Bei der stetigen Gleichverteilung haben alle Realisationen einer Zufallsvariable in einem Intervall [a, b] die gleiche
Wahrscheinlichkeit einzutreffen (Kurzform: X ~ Re (a,b))
● Wegen der rechteckförmigen Dichtefunktion wird die Verteilung auch als Rechteckverteilung bezeichnet
Wahrscheinlichkeitsdichte
Verteilungsfunktion
Erwartungswert
Varianz](https://image.slidesharecdn.com/spsskurs-1233061399380763-2/85/SPSS-Kurs-112-320.jpg)

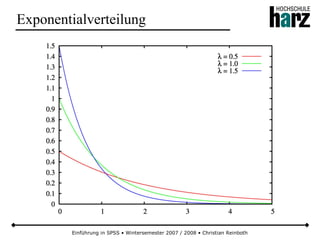
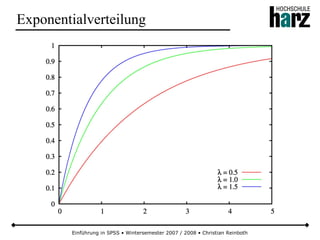
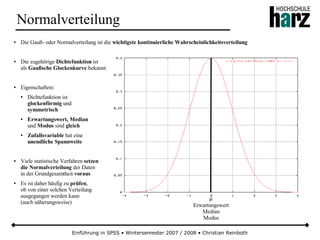


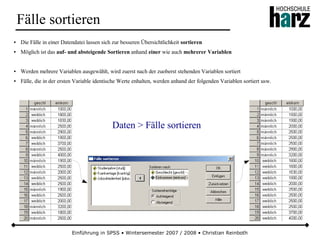
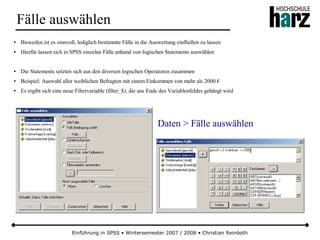


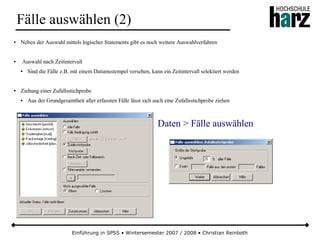

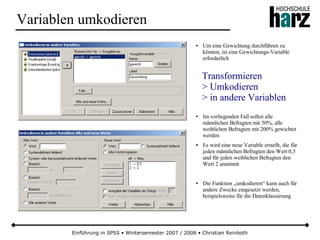
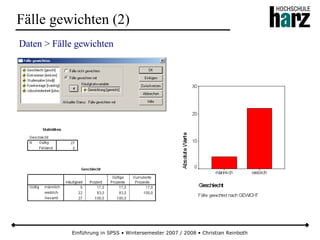








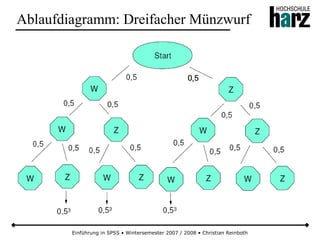


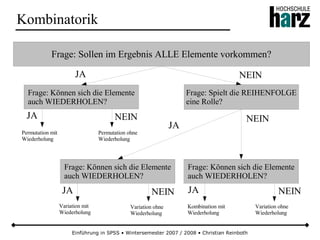





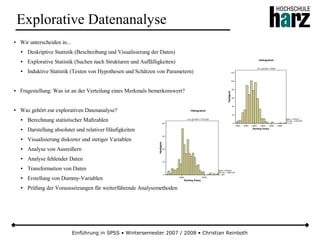
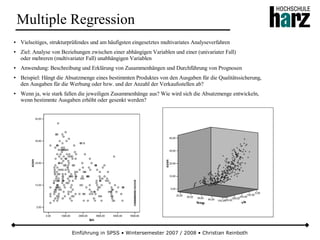
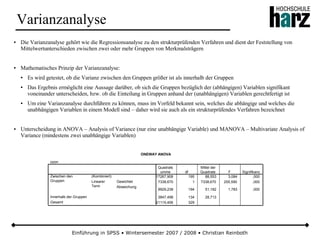
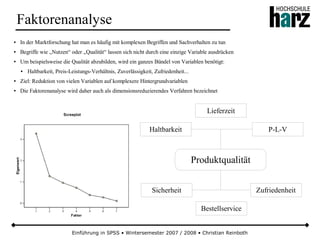





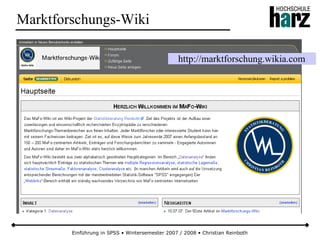



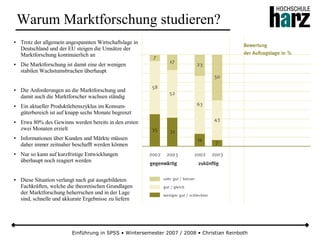
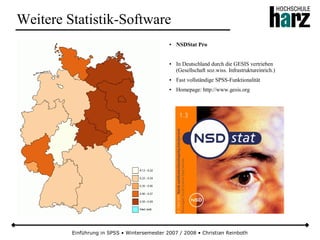
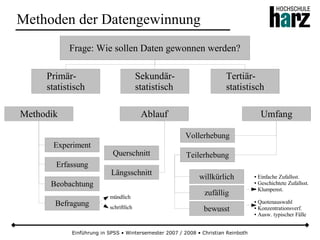
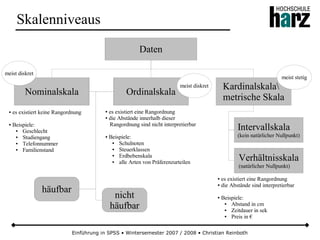
Das Dokument bietet eine umfassende Einführung in die Software SPSS und deren Anwendung im Bereich der Marktforschung, inkl. grundlegender statistischer Konzepte und Methoden der Datenauswertung. Es behandelt Themen wie Datenskalierung, verschiedene statistische Tests sowie grafische Darstellung von Daten. Ferner werden Kursziele, -inhalte und empfohlene Literatur aufgeführt, um Studierenden die Grundlagen für eine erfolgreiche Analyse und Interpretation von Marktforschungsdaten näherzubringen.

































