















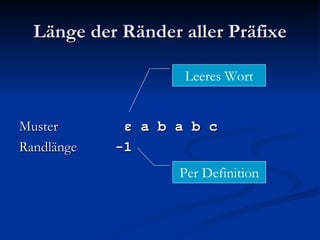









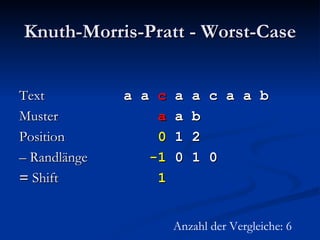
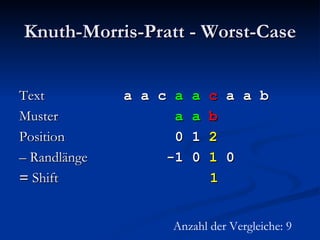






























![Berechnung der Zwischentabelle Index i 0 1 2 3 4 5 6 7 8 Muster P b a b a c b a b a Suffixlänge N(i) 0 2 0 4 0 0 2 0 - N(i):= max{j: j ≥ 0 Λ P[(i – j + 1)..i] ist Suffix von P}](https://image.slidesharecdn.com/boyermoorealgorithmus-2370/85/Boyer-Moore-Algorithmus-62-320.jpg)
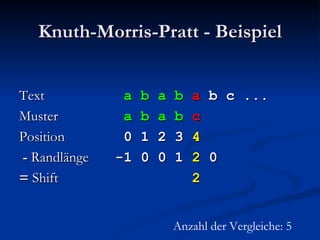
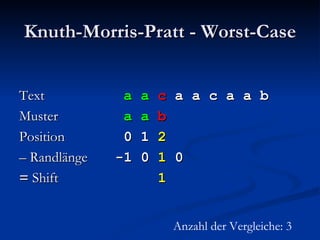
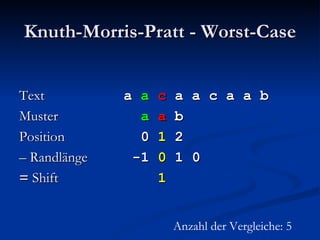
![Berechnung der Zwischentabelle Index i 6 Muster P b a b a c b a b a Suffixlänge N(i) 2 N( 6 ):= max{j: j ≥ 0 Λ P[( 6 – j + 1).. 6 ] ist Suffix von P} = 2](https://image.slidesharecdn.com/boyermoorealgorithmus-2370/85/Boyer-Moore-Algorithmus-63-320.jpg)



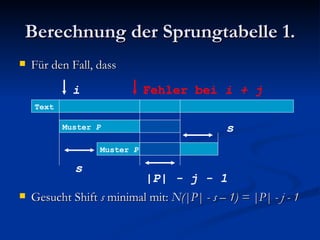
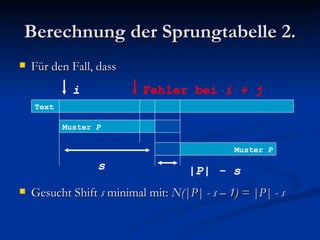






Der Boyer-Moore-Algorithmus ist ein effizienter Textsuchalgorithmus, der beim Suchen nach kurzen Mustern in langen Texten mithilfe von Techniken wie der 'Bad Character'- und 'Good Suffix'-Regel arbeitet. Er übertrifft andere Algorithmen wie die naive Suche und den Knuth-Morris-Pratt-Algorithmus, insbesondere bei größeren Alphabeten und weniger Wiederholungen im Muster. Der Algorithmus hat eine durchschnittliche Laufzeit, die sich bei großen Texten auf bis zu 3(n + m) verringern kann, was ihn für die praktische Anwendung vorteilhaft macht.






















































