24-mal heruntergeladen



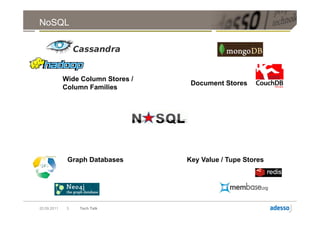




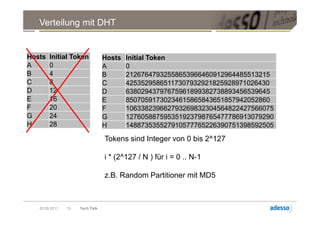
![Verteilung mit DHT
Partitioner( RowKey ) = Token
Hosts Initial Token [28,31] [0,3]
A 0
B 4
C 8 [24,27] [4,7]
D 12
E 16
F 20
G 24
H 28 [20,23] [8,11]
[16,19] [12,15]
20.09.2011 11 Tech Talk](https://image.slidesharecdn.com/techtalkcassandra-110921042054-phpapp01/85/Tech-Talk-Cassandra-11-320.jpg)
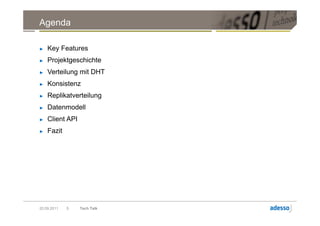
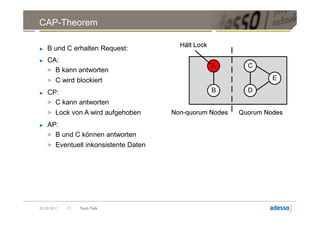
![Verteilung mit DHT
Partitioner( RowKey ) = Token
Hosts Initial Token [28,31] [0,3]
A 0
B 4
C 8 [24,27] [4,7]
D 12
E 16
F 20
G 24
H 28 [20,23] [8,11]
[16,19] [12,15]
Beispiel:
Partitioner( „Cassandra“ ) = 7
20.09.2011 12 Tech Talk](https://image.slidesharecdn.com/techtalkcassandra-110921042054-phpapp01/85/Tech-Talk-Cassandra-12-320.jpg)




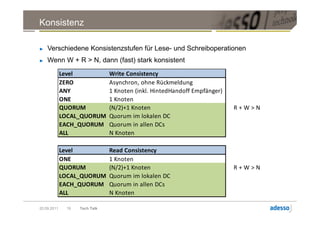




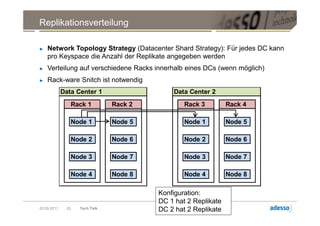
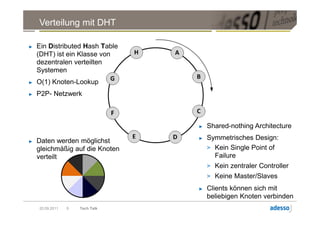
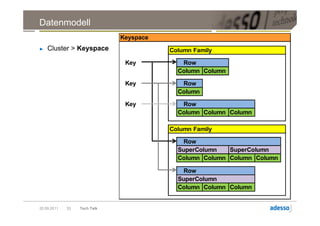
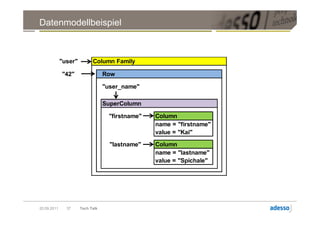
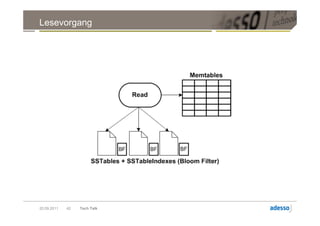
![Datenmodell
► Cluster > Keyspace > Column Family > Row > Column
Column
byte[] name
byte[] value
long timestamp
20.09.2011 27 Tech Talk](https://image.slidesharecdn.com/techtalkcassandra-110921042054-phpapp01/85/Tech-Talk-Cassandra-27-320.jpg)
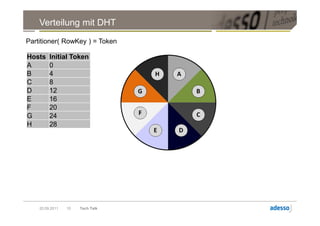
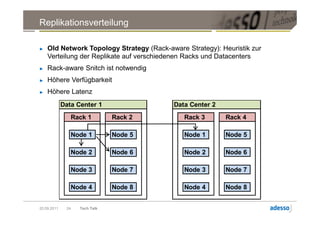
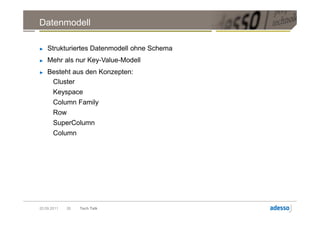
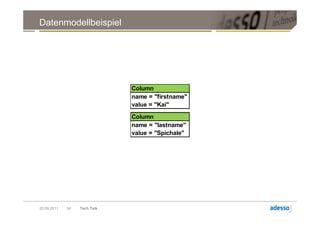
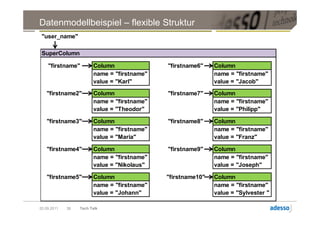
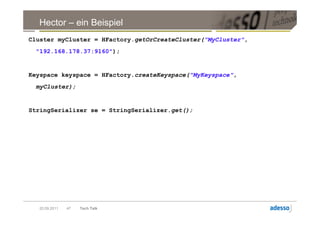
![Datenmodell
► Cluster > Keyspace > Column Family > Row
Row
Key Key Key
Column Column Column
byte[] name byte[] name byte[] name
byte[] value byte[] value byte[] value
long timestamp long timestamp long timestamp
20.09.2011 28 Tech Talk](https://image.slidesharecdn.com/techtalkcassandra-110921042054-phpapp01/85/Tech-Talk-Cassandra-28-320.jpg)
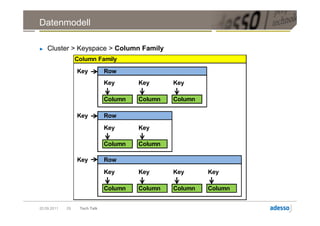
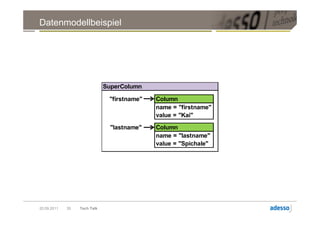
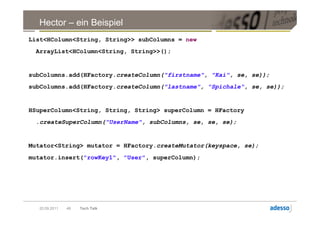
![Datenmodell
► Cluster > Keyspace > Column Family > Row > SuperColumn
SuperColumn
Key Column
byte[] name
byte[] value
long timestamp
Key Column
byte[] name
byte[] value
long timestamp
20.09.2011 31 Tech Talk](https://image.slidesharecdn.com/techtalkcassandra-110921042054-phpapp01/85/Tech-Talk-Cassandra-31-320.jpg)
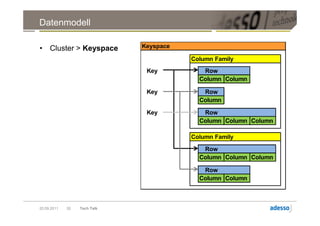
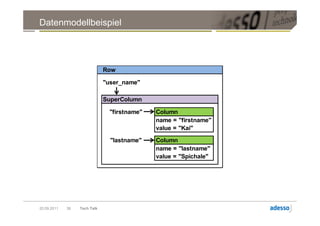
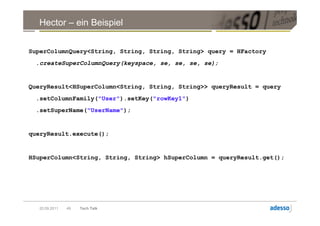
![Datenmodell
► Cluster > Keyspace > Column Family > Row
Row
Key Key
SuperColumn SuperColumn
Key Column Key Column
byte[] name byte[] name
byte[] value byte[] value
long timestamp long timestamp
Key Column
byte[] name
byte[] value
long timestamp
20.09.2011 32 Tech Talk](https://image.slidesharecdn.com/techtalkcassandra-110921042054-phpapp01/85/Tech-Talk-Cassandra-32-320.jpg)
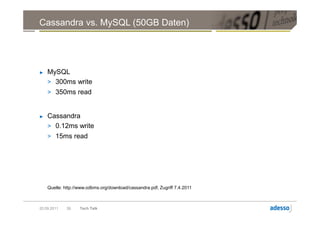
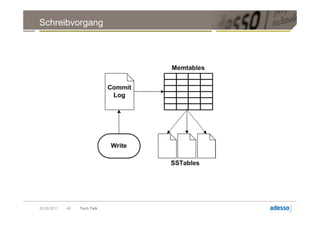







Das Dokument ist eine umfassende Präsentation über Apache Cassandra, eine verteilte, skalierbare und hochverfügbare NoSQL-Datenbank, die ursprünglich bei Facebook entwickelt wurde. Es behandelt wesentliche Konzepte wie Datenverteilung, Konsistenzmodelle, Replikationsstrategien sowie ein schemaloses Datenmodell und vergleicht die Leistung von Cassandra mit traditionellen relationalen Datenbanken wie MySQL. Die Präsentation betont die Vorteile von Cassandra in Bezug auf Verfügbarkeit und Skalierbarkeit, während auch die Herausforderungen im Umgang mit Konsistenz und Datenintegrität diskutiert werden.















































