Als PDF, PPTX herunterladen



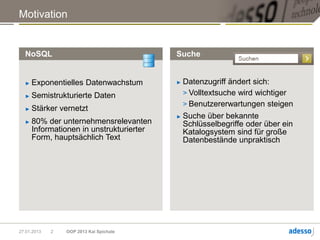



![Abfragetypen
Abfrage Beispiel
Termsuche +dog –snoopy
(MUST, MUST_NOT, SHOULD)
Phrasensuche „foo bar“
Wildcard fo*a?
Fuzzy fobar~
Range [A TO Z]
27.01.2013 8 OOP 2013 Kai Spichale](https://image.slidesharecdn.com/oop2013nosqlsearch-130128030914-phpapp02/85/OOP-2013-NoSQL-Suche-9-320.jpg)


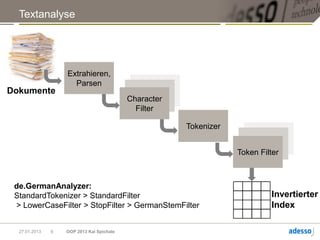
![MongoDB
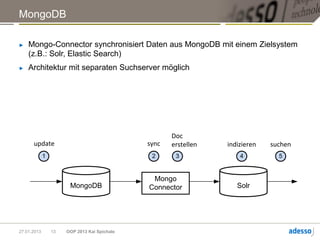
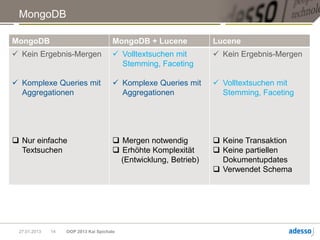
► Ad-hoc-Abfragen für Dokumente oder einzelne Felder
db.things.find({firstname:"John"})
► Abfragen mit serverseitig ausgeführten JavaScript-Funktionen
► Aggregationen, MapReduce
► Einfache Textsuchen
> Mit Multikeys können Werte eines Arrays indiziert werden
{ article : “some long text",
_keywords : [ “some" , “long" , “text“]
}
27.01.2013 12 OOP 2013 Kai Spichale](https://image.slidesharecdn.com/oop2013nosqlsearch-130128030914-phpapp02/85/OOP-2013-NoSQL-Suche-13-320.jpg)
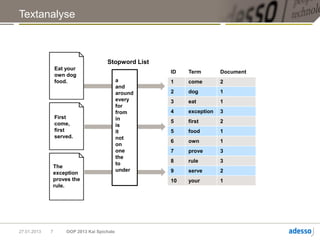
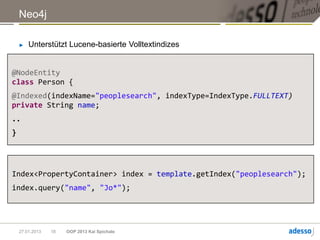
![Neo4j
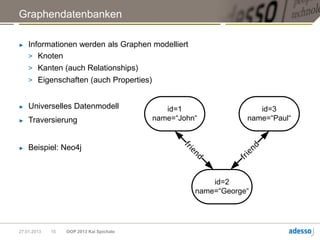
► Traversierung:
> Tiefensuche, Breitensuche
> Gremlin, Cypher
START person=node:peoplesearch(name=‘John’)
MATCH person<-[:friends]->afriend RETURN afriend
Ergebnis = George
27.01.2013 16 OOP 2013 Kai Spichale](https://image.slidesharecdn.com/oop2013nosqlsearch-130128030914-phpapp02/85/OOP-2013-NoSQL-Suche-17-320.jpg)


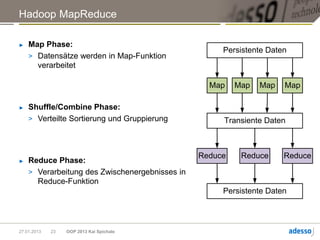
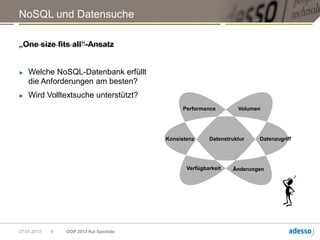
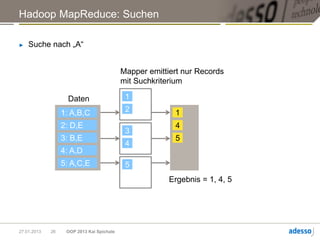
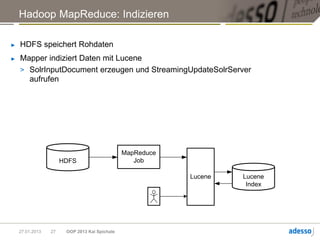
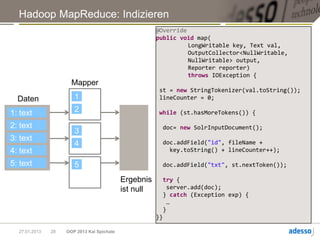
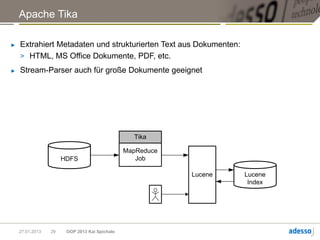
![Hadoop MapReduce
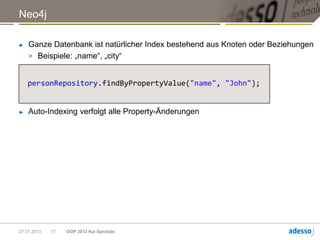
► Allgemeine Funktionsweise eines MapReduce-Jobs
map(k, v) -> [(K1,V1), (K2,V2), ... ]
Mapper
Daten Shuffle Reducer Ergebnis
reduce(Kn, [Vi, Vj, …]) ->
(Km, R)
27.01.2013 24 OOP 2013 Kai Spichale](https://image.slidesharecdn.com/oop2013nosqlsearch-130128030914-phpapp02/85/OOP-2013-NoSQL-Suche-25-320.jpg)

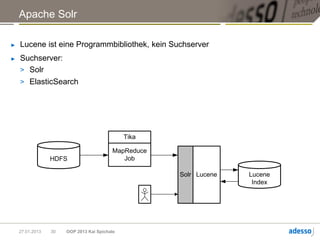
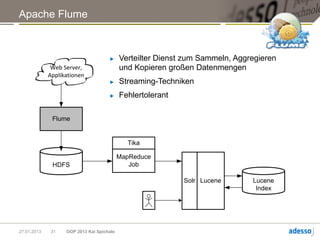
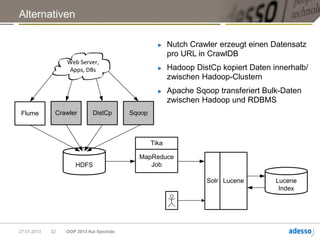
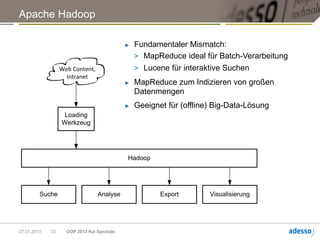


Das Dokument von Kai Spichale behandelt die Datensuche mit NoSQL-Technologien und die zunehmende Bedeutung von Volltextsuchen in Verbindung mit exponentiellem Datenwachstum. Es bietet einen Überblick über verschiedene NoSQL-Datenbanken wie MongoDB, Neo4j, Apache Cassandra und Hadoop sowie deren Architekturen und Anwendungsfälle für die Verarbeitung semistrukturierter Daten. Zudem wird die Integration von Suchtechnologien wie Apache Lucene thematisiert, um die Sucheffizienz in großen Datensätzen zu verbessern.










































