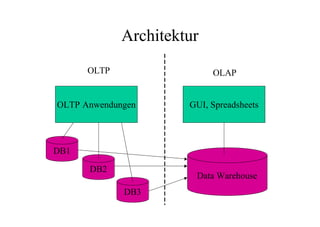
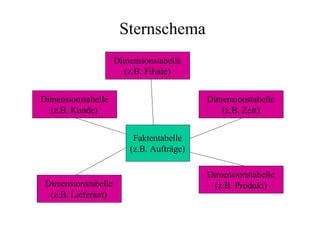
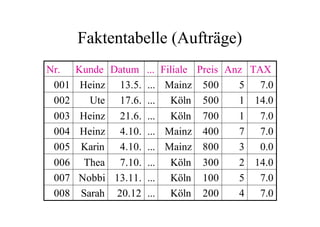
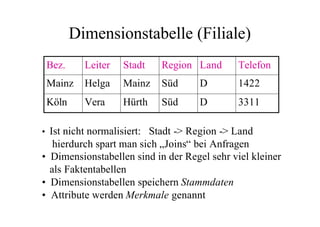
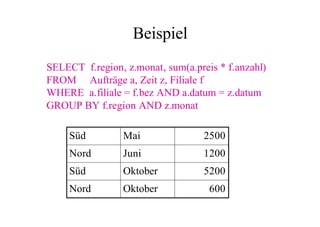
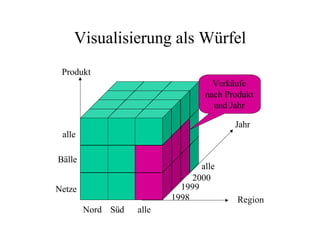
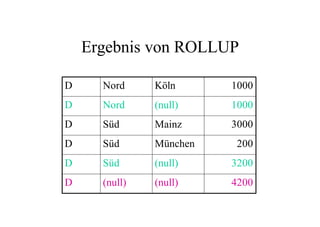
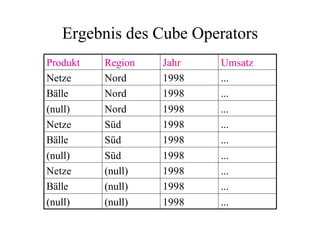
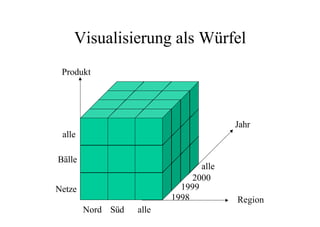
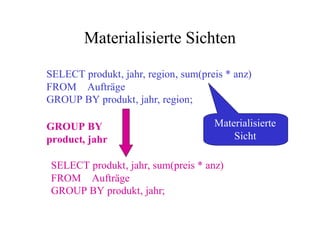
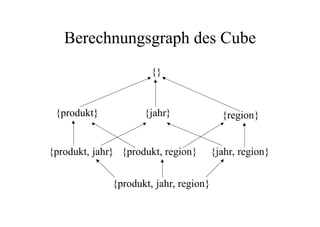
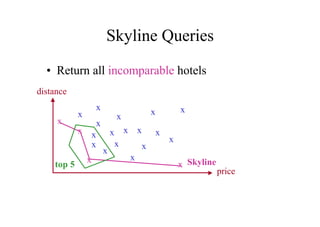
Das Dokument behandelt das Thema Data Warehousing mit einem Fokus auf OLTP (Online Transaction Processing) und OLAP (Online Analytical Processing), deren Unterschiede, Anwendungen und Herausforderungen in der Praxis. Es erläutert die Notwendigkeit eines Data Warehouses zur Unterstützung von OLAP durch die Aggregation und Replikation von OLTP-Daten sowie verschiedene Datenbank- und Datenmodellierungsansätze. Zudem werden Methoden des Data Mining wie Assoziationsregel-Mining und Clustering erwähnt, die zur Analyse und Klassifikation von Daten verwendet werden.