




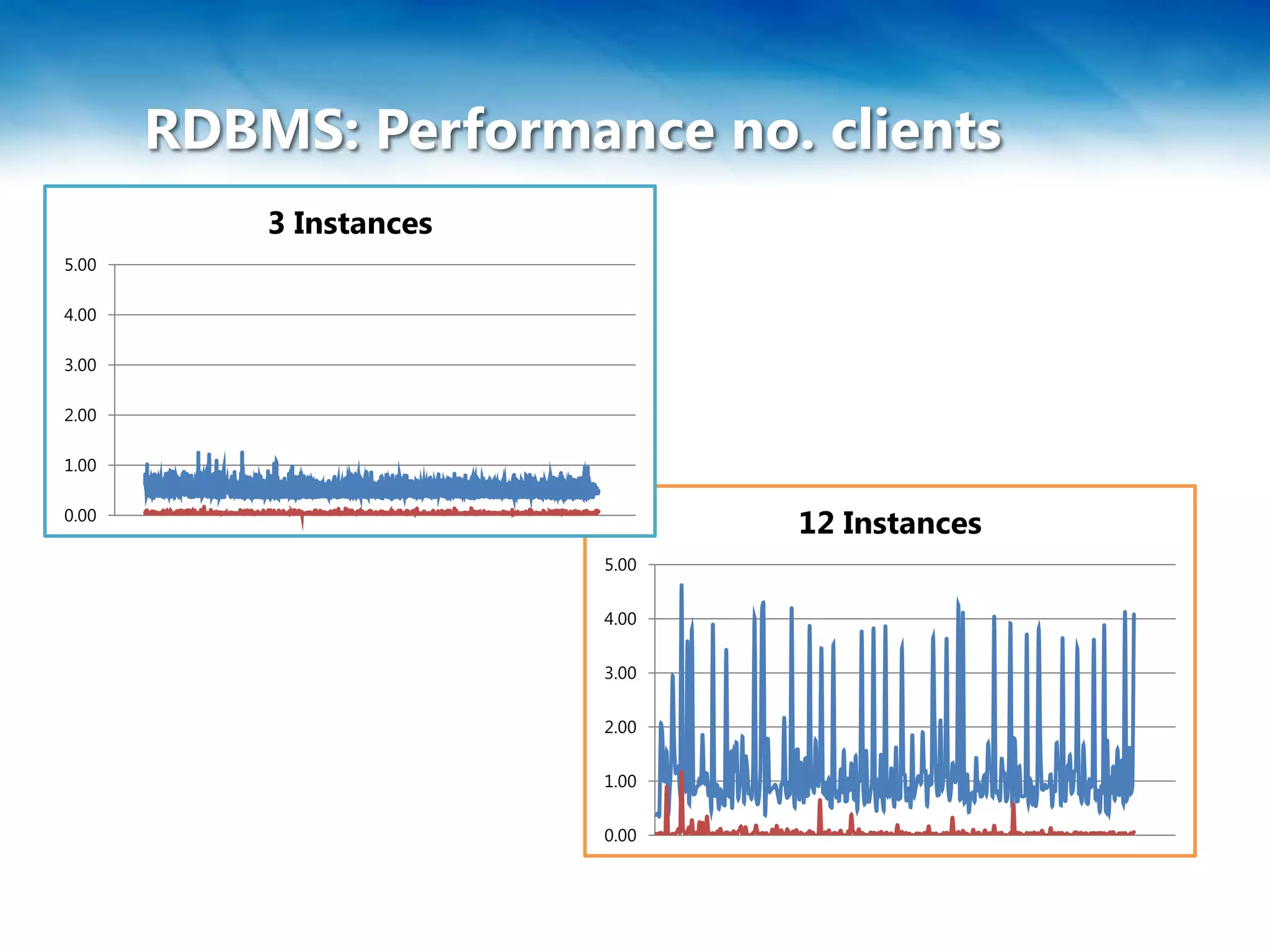
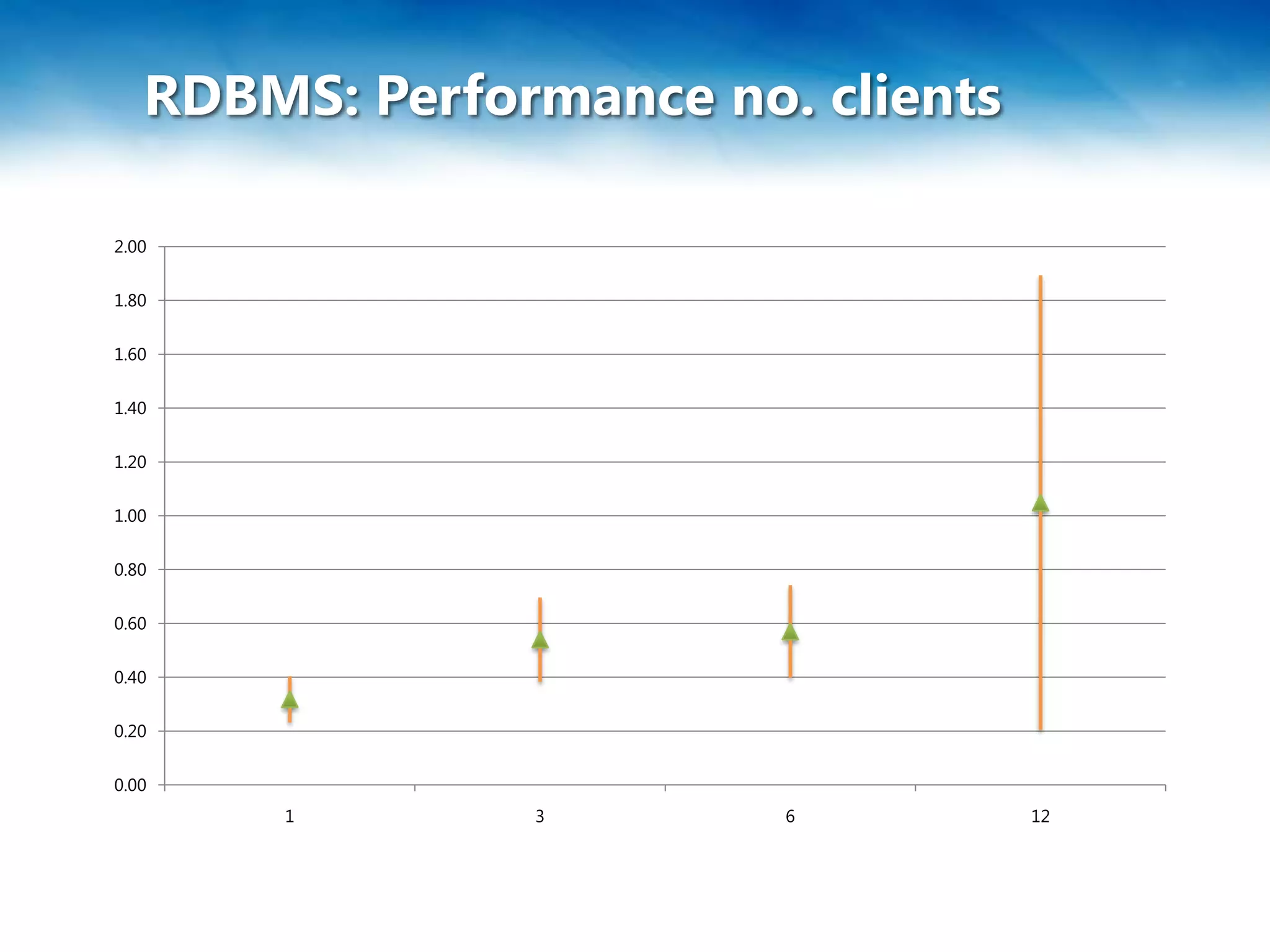


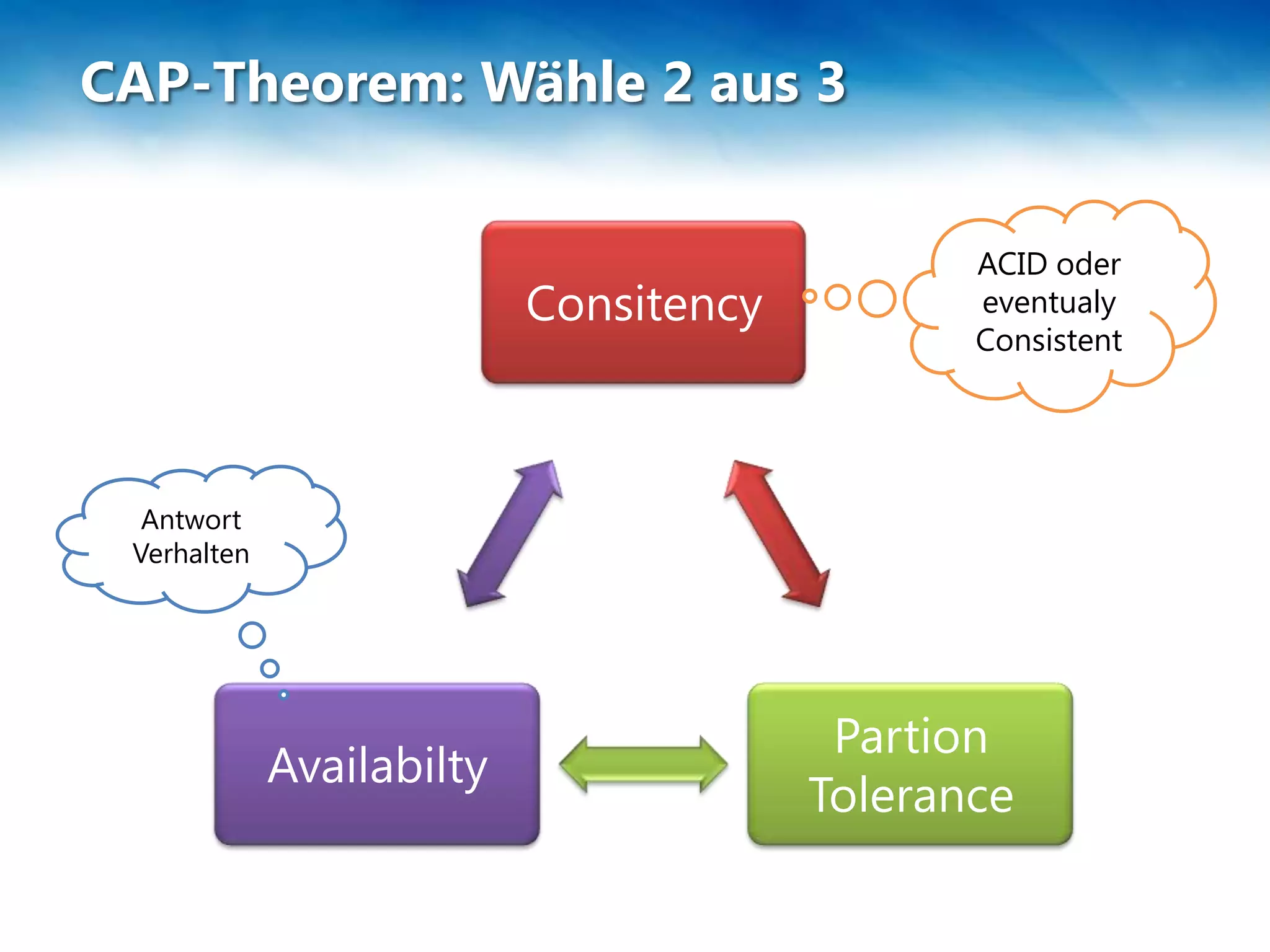



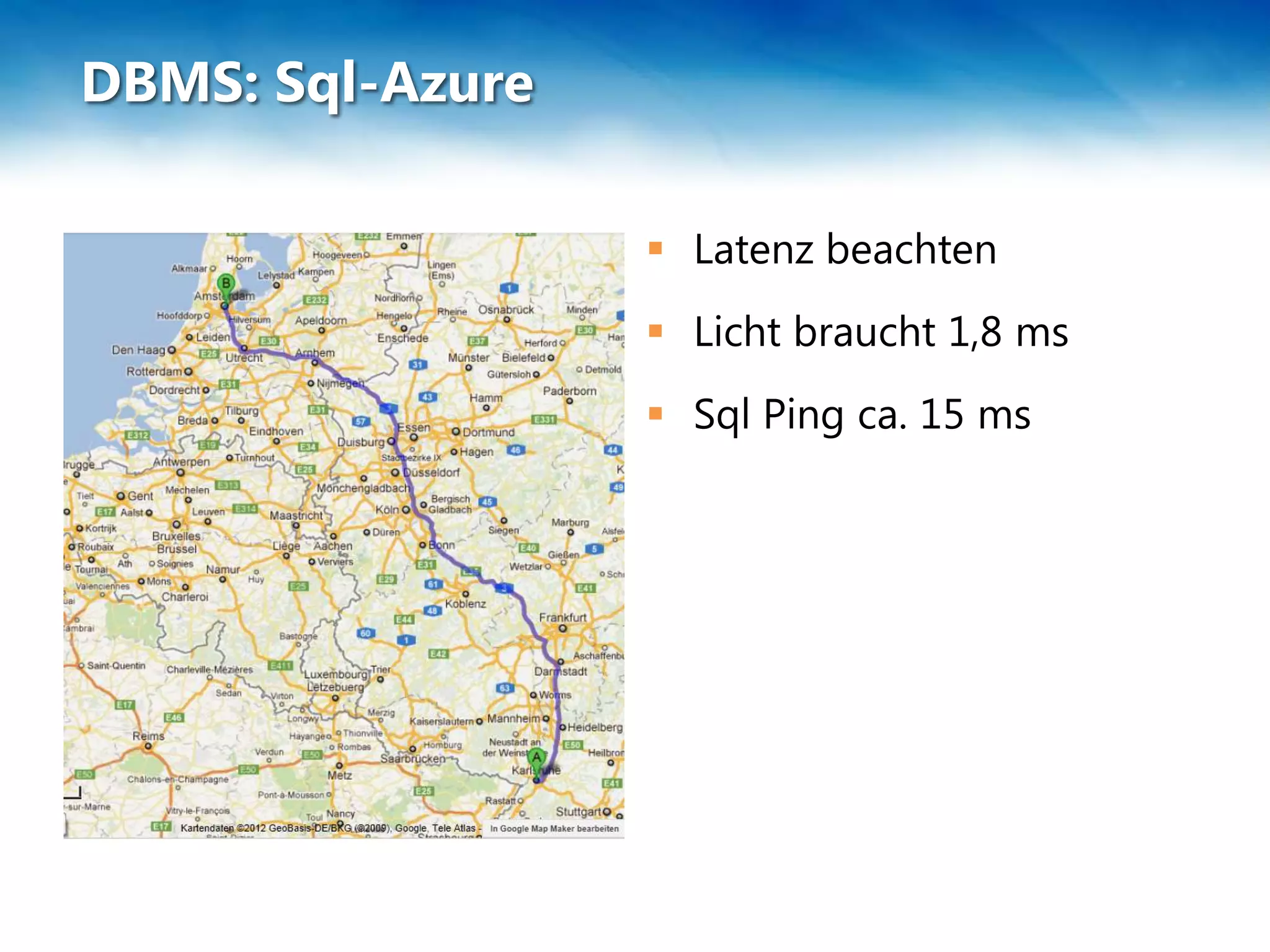
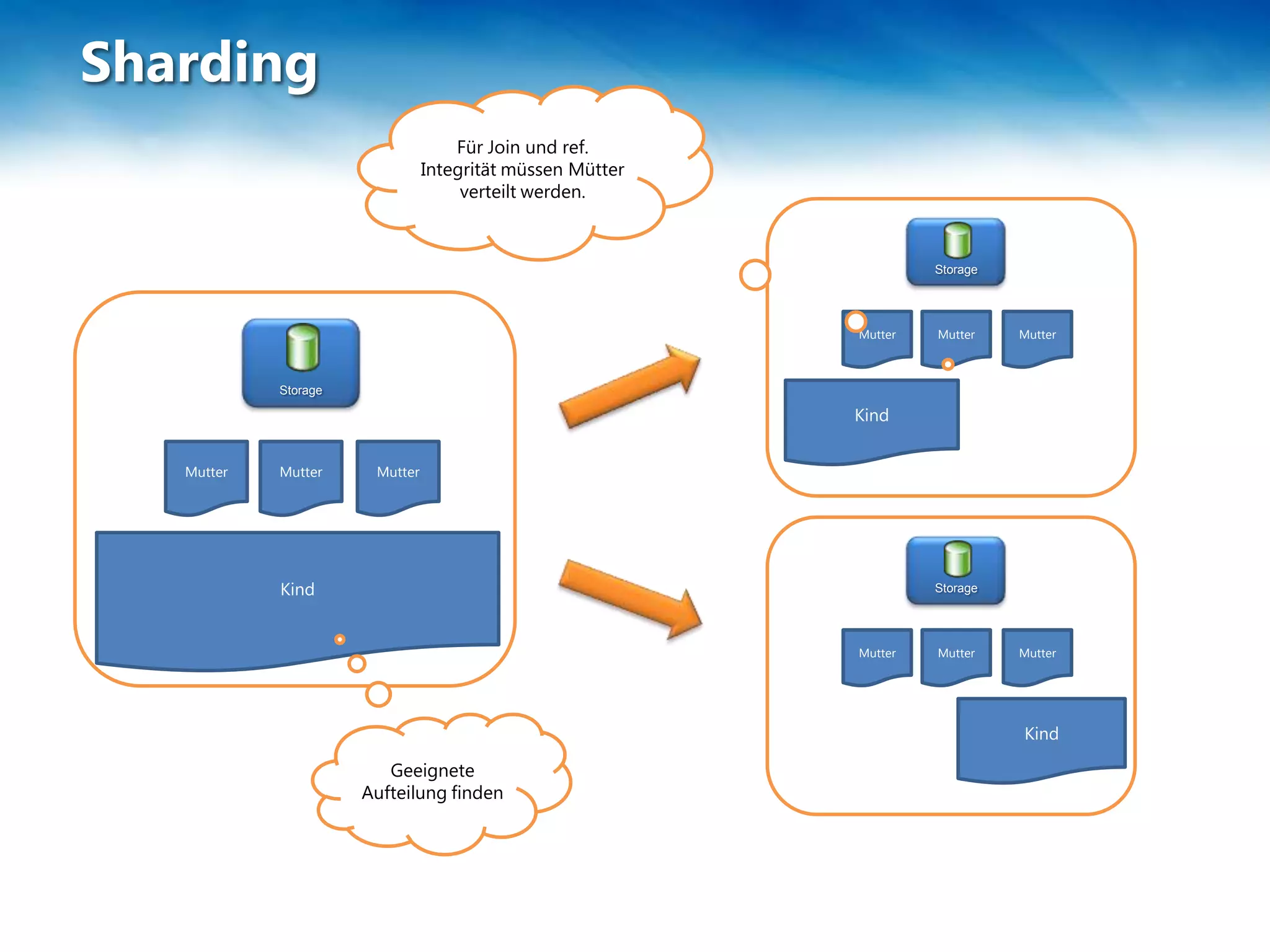













Das Dokument behandelt die Skalierung und Leistung von NoSQL-Datenbanken, insbesondere RavenDB, sowie die Herausforderungen und Strategien im Umgang mit großen Datenmengen. Es wird das CAP-Theorem erläutert, das die Eigenschaften Konsistenz, Verfügbarkeit und Partitionstoleranz in verteilten Systemen beschreibt, und es werden verschiedene Methoden wie Sharding und Federation zur Datenverteilung vorgestellt. Zudem werden spezifische Einschränkungen und Vorteile von SQL Azure und Azure Table Storage besprochen.

























































