Die vorliegende Studie untersucht anthropomorphe Interfaceagenten und Sprachinteraktion in multimodalen Systemen im Rahmen des multimo3d-Projekts. Durch Simulationsexperimente wird die Beziehung zwischen Avatar-Ansprache und hedonistischer Nutzerbewertung sowie die Effektivität der Sprachinteraktion in einem Prototyp untersucht. Die Ergebnisse zeigen teils unerwartete Befunde zur Nutzereinschätzung des Avatars und zur Leistungsfähigkeit der Sprachmodalität, was weiteren Forschungsbedarf im Bereich multimodaler Schnittstellen aufzeigt.





![Einleitung
6
3 Einleitung
Die meisten Menschen unterscheiden heute noch klar zwischen den Robotern aus der
Science-Fiction-Welt und den Maschinen in ihrem täglichen Leben. In Filmen wie „Krieg
der Sterne“, „Raumschiff Enterprise“ und „2001: Odyssee im Weltraum“ sehen wir
intelligente Maschinen, die Namen wie C3PO, R2D2, Commander Data und HAL tragen.
Aber unsere Rasenmäher, Autos oder Textverarbeitungssysteme können ihnen nicht
entfernt das Wasser reichen. Die Science-Fiction-Konstrukte und die Maschinen, mit
denen wir leben, gehören zwei völlig verschiedenen Welten an. Die Fantasiemaschinen
verfügen über Sprachvermögen und Technologie, äußern Gefühle, Wünsche, Ängste, sie
lieben und sind stolz. Für unsere realen Maschinen gilt das - noch - nicht. Aber wie wird
das in hundert Jahren sein?
Die Grenze zwischen Fantasie und Realität wird schon sehr bald innerhalb der nächsten
Jahre fallen, auch wenn das so schwer vorstellbar ist wie vor zehn Jahren die tägliche
Benutzung des World Wide Web. Wir stehen kurz vor der „Roboterrevolution“. Das jahr-
hundertealte Projekt der Menschheit, künstliche Wesen zu schaffen, fängt an, Früchte zu
tragen. Maschinen fällen Urteile, die die Menschen in den letzten 200 Jahren seit der in-
dustriellen Revolution auf Trab gehalten haben. Aber diese Roboter sind nicht einfach
Roboter - es sind künstliche Lebewesen. Unsere Beziehung zu diesen Maschinen wird sich
sehr von unseren Verhältnissen zu allen vorangehenden unterscheiden. [BROOKS02]
Die Forschung befasst sich deshalb verstärkt mit der multimodalen Schnittstelle
zwischen Mensch und Computer. Ist es vom Benutzer gewünscht, dass der Computer wie
ein Mensch reagiert? Wollen wir mit dem Computer wie mit einem Menschen
kommunizieren? Was heißt überhaupt Kommunikation mit dem Computer - welche Kanäle
spielen dabei eine Rolle?
Diese Arbeit beschäftigt sich speziell mit Spracheingabe und anthropomorphen
Interfaceagenten als Teile einer multimodalen Benutzungsschnittstelle. Andere
Publikationen, die im Rahmen des im empirischen Teil vorgestellten mUltimo3D-Projektes
am Heinrich-Hertz-Institut angefertigt wurden, beschäftigen sich des Weiteren mit der
Haptik [BRIEST02], der Blickinteraktion [BAUMGARTEN02] und mit der Integration
aller Modalitäten [SEIFERT02].](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-6-320.jpg)
![Theorien / Konzepte
7
4 Theorien / Konzepte
Im Folgenden werden einige psychologische Grundlagen und bestehende Forschungs-
ergebnisse zu den Themen Multimodalität als Oberkategorie, anthropomorphe Interface-
agenten und Sprachinteraktion als Teilgebiete und zum Thema adaptive Dialogsysteme als
relevante Aspekte der Gestaltung einer intelligenten Benutzungsschnittstelle zwischen
Mensch und Computer vorgestellt und diskutiert. Diese Betrachtung bietet einen groben
Überblick über ein stark umforschtes, aber noch relativ diffiziles Gebiet der künstlichen
Intelligenz. Theoriegeleitete Hypothesen für die Empirie im zweiten Teil sind deshalb nur
bedingt zu erwarten.
4.1 Multimodalität – eine Einführung am Beispiel der
Embassi-Anwendungen (Elektronische Multimodale
Bedien- und Service- ASSIstenz)
Multimodale Systeme können natürliche Eingabeformen wie Sprache, Gestik, Blick-
bewegungen etc. mit multimodalen Ausgabemöglichkeiten kombinieren. Sie ermöglichen
es dem Nutzer, abhängig von der jeweiligen Intention, die passende Modalität für die
Interaktion mit dem vorhandenen technischen System zu nutzen. [OVIATT99]
Die nachfolgende Abbildung 1 stellt die technischen Komponenten eines multimodalen
Interfaces dar.
Abbildung 1 - Multimodales Interface
!"#$%&'()*+(
,-.%/0'1(23+'+(
Ausgabe von(4565(
2'781(9.%:;<(
Ausgabe von
Vibration, Kraft
='$;#8.;'."+$()*+(
23+'+1(,-.%/0'(
='$;#8.;'."+$()*+(
9'#8;<1(>;?;<(
='$;#8.;'."+$()*+(
.%:81(!;&.%8;*+(
!"";8;)'#(#+8'.:%/'((
!;#"'$$'#(#+8'.:%/'(
%%-8;#/0'#(#+8'.:%/'(
&$:%<8*.;#/0'#(
#+8'.:%/'(](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-7-320.jpg)
![Theorien / Konzepte
8
Das System sollte in der Lage sein, aus dem Strom von Äußerungen mit Hilfe von
Spracherkennung, Gestenanalyse etc. das abstrakte Ziel des Nutzers zu rekonstruieren.
Ein wichtiges Szenario im Bereich Privathaushalt des Embassi-Projektes [EMBASSI01]
ist das „Wohnzimmerszenario“. Es soll eine Medienauswahl auf der Grundlage eines
Nutzerkonzepts realisiert werden. Der Nutzer äußert etwa „Ich will Nachrichten sehen /
den Film aufnehmen.“ und das erwartete Resultat wird durch das System komplett bis zur
Programmierung des Videorekorders realisiert. Innerhalb des Projektes wurden natürlich-
sprachliche In- und Outputmodalitäten entwickelt. Dabei werden Spracheingabe, eine
Vielzahl grafischer Navigations- und Hinweiswerkzeuge sowie Sprachsynthese und an-
thropomorphe Interfaceagenten auf der Ausgabeseite verwendet.
Die Vorteile multimodaler Interaktion liegen in einer flexibleren Handhabung tech-
nischer Systeme und in der gleichzeitigen Entlastung des Benutzers durch die Verteilung
der Informationsübertragung auf mehrere Sinne [HEDICKE02].
Konkret können Fehler in der Aufgabenbearbeitung bis zu 50% während multimodaler
Interaktion reduziert werden. Die Flexibilität von multimodalen Systemen zahlt sich
besonders in wechselnden Umgebungen oder bei Einschränkungen auf Grund von Behin-
derungen aus. In einer im Rahmen des Anwendungsbereiches „Öffentliche Terminal-
systeme“ des Embassi-Projektes mit 90 Personen durchgeführten Studie zur Ermittlung des
Unterstützungsbedarfs behinderter und nicht-behinderter Personen bei der Bedienung von
Automaten [ENGE00] stellte sich heraus, dass Sehbehinderte Sprachausgabe vor der
Ausgabe in Braille-Schrift oder in taktiler Form präferierten.
Mit dem Embassi-Anwendungsbereich Kraftfahrzeug sind spezielle Einschränkungen
verbunden, die sich durch die Fahrsituation ergeben. So soll etwa der Fahrer seine Augen
möglichst nicht von dem Verkehrsgeschehen abwenden und seine Hände am Steuerrad
behalten. Aus diesem Grund sind konventionelle Nutzerschnittstellen (Displays, Knöpfe,
Schieberegler etc.) in diesem Kontext nicht sonderlich geeignet. Daher müssen insbe-
sondere Sprachein- und -ausgabe eingesetzt werden.
Ein Mythos der Multimodalität [OVIATT99] besagt, dass Sprache die primäre
Modalität ist, sofern sie im multimodalen System enthalten ist..Im Folgenden wird deshalb
näher auf diese Modalität und ihre Bersonderheiten in der Mensch-Maschine-Kom-
munikation eingegangen.](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-8-320.jpg)
![Theorien / Konzepte
9
4.2 Sprachinteraktion zwischen Mensch und Maschine
In diesem Kapitel wird auf die einzelnen Bestandteile der Sprachinteraktion als
wichtiges Teilgebiet der in Kapitel 4.1 dargestellten multimodalen Interaktion zwischen
Mensch und Maschine eingegangen. Abbildung 2 zeigt die die Gliederung der Bestandteile
in einer Baumstruktur nach [VARY98].
Abbildung 2 - Sprachinteraktion zwischen Mensch und Maschine nach Vary et al. ,1998
4.2.1 Sprachkodierung
Die Sprachkodierung ist eine unerlässliche technische Voraussetzung für Sprach-
erkennung und Sprechererkennung. Das durch ein Mikrofon auf den Computer übertragene
akustische Signal wird durch Auswertung der durch die Lautfolge der Sprache ausgelösten
Luftdruckschwankungen mittels eines Analog/Digital-Wandlers in elektrische Impulse um-
gewandelt. [SUSEN99] Die entstandenen Frequenzbereiche müssen zur weiteren Daten-
bearbeitung beschnitten werden, um die Übermittlung, besonders im Telekom-
munikationsbereich, zu gewährleisten.
4.2.2 Spracherkennung
In der Spracherkennungskomponente wird versucht, die eingehende Sprachsequenz
meistens bis auf Wort- oder Phonemebene zu zerlegen. Ein Phonem ist die kleinste
eigenständige Einheit im akustischen System einer Sprache. Dann versucht man anhand
,-.%/0;+8'.%<8;*+(
4';#/0'+(>'+#/0("+"(
>%#/0;+'(
,-.%/0%"#$%&'(
(,-.%/0#)+80'#'*(
,-.%/0<*";'."+$(
,-.%/0'.<'++"+$( ,-.'/0'.'.<'++"+$(
,-.%/0)'.#8'0'+(
+;%$*$#)#8'?'(](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-9-320.jpg)
![Theorien / Konzepte
10
von vorher erhaltenen Sprachdaten das wahrscheinlichste Wort zu ermitteln. Eine Hilfe
dabei ist das Wissen der Menschen über die Häufigkeit beziehungsweise die
Auftretenswahrscheinlichkeit von Wörtern, Phonemen und anderen Einheiten sowie über
das mögliche und wahrscheinliche Aufeinanderfolgen dieser Einheiten beziehungsweise
die Übergangswahrscheinlichkeiten. Mit welchen Verfahren ist dies zu bewerkstelligen ?
Die etablierten psycholinguistischen Verfahren zur Anwendung dieser Wahrschein-
lichkeiten sind Hidden-Markov-Modelle und die in Kapitel 4.3.6 näher beschriebenen
dynamischen Bayessche Netze (DBN).
Hidden-Markov-Modelle (HMM) sind ein stochastischer Ansatz zur ASR (Automatic
Speech Recognition), der die ursprünglichen Methoden der dynamischen Programmierung
weiterentwickelt. HMM nutzen Informationen über die statistische Wahrscheinlichkeit
einzelner Phoneme und bestimmen das Ergebnis aus ganzen Sequenzen, was die Ge-
nauigkeit der Erkennung des einzelnen Phonems drastisch erhöht. Da die zugrunde-
liegenden Tabellen nicht fest verankert sind, können sie relativ leicht trainiert werden
[PICONE90].
Die Anwendung dynamischer Bayesscher Netze auf die Spracherkennung erweitert das
zugrundeliegende Konzept um die Anwendung zweier Wahrscheinlichkeitsparameter für
die Worterkennung. Zusätzlich zur normalen Bewertung phonetischer Sequenzen wird der
artikulatorische Ablauf zur Bestimmung herangezogen. Diese Adaption an unterschied-
liche Ausspracheformen ist auch mit klassischen HMM möglich, verursacht dort aber eine
wesentlich höhere Komplexität auf Grund der zusätzlichen, versteckten Knoten und der
daraus resultierenden Abfolgemöglichkeiten. Die Modellierung des artikulatorischen Kon-
textes in dynamischen Bayesschen Netzen hingegen hat nur eine Verdopplung des
Suchraumes zu Folge.
Im Vergleich zu herkömmlichen BN-Modellen erhöht sich die Erkennungsrate um 12
bis 29%. Die direkte Bedeutung der zusätzlichen Kontextinformation ist nicht klar abzu-
leiten. In einigen Fällen zeigt sich aber eine starke Korrelation mit der Aussprache der
Vokale [ZWEIG99].
4.2.3 Sprachverstehen
Hier verwendet man oft eine syntaktische und eine semantische Analyse, um den
strukturellen Aufbau der erkannten Wortkette (Satzbau) zu erhalten und daraus die Bedeu-
tung der einzelnen Wörter zu erkennen. Hierzu benötigt man ein Lexikon und eine](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-10-320.jpg)
![Theorien / Konzepte
11
Grammatik. Das Lexikon besteht in der Regel aus komplexen Strukturen, um alle
relevanten syntaktischen Charakteristiken eines Wortes zu beschreiben, zum Beispiel, ob
es sich um Singular oder Plural handelt oder welcher Tempus benutzt wird. Die
Grammatik besteht aus Regeln für Satz- und Phrasenstrukturen und gibt an, wie die Wörter
miteinander kombiniert werden können und welcher Schluss sich aus der jeweiligen
Kombination ziehen lässt [TUR02].
4.2.4 Sprachsynthese / Sprachausgabe
Die Konstruktion der auszugebenden Wortkette besteht aus zwei Punkten:
• Welche Information soll ausgegeben werden?
• Wie soll die Information strukturiert sein?
Dazu kann man einfache vorgefertigte Muster verwenden oder komplexe Methoden, die
natürliche Sprachgenerierungstechniken verwenden, wie zum Beispiel Text-To-Speech-
Systeme. [VARY98] Sie erlauben es, fließende Sprache mit unbegrenztem Vokabular
lediglich aus einem Satz sprachlicher Regeln über die Produktion von Phonemen zu
synthetisieren.
Die Sprachausgabe besteht aus symbolischer Verarbeitung, der Prosodiengenerierung
(Sprachmelodie) und der Signalgenerierung. In der symbolischen Verarbeitung wird zu-
nächst die Wortkette in Einheiten zerlegt und anschließend normalisiert, das heißt umge-
wandelt in eine Form, die später gesprochen werden kann. In der morphologischen
Analyse wird dann jedes Wort in Stamm und Endung zerlegt. In der grammatikalischen
Analyse werden Daten für die Betonung und der Satzfokus ermittelt. In der phonetischen
Zerlegung wird der Übergang von der Rechtsschrift zur Lautschrift durchgeführt. Die
Prosodiegenerierung erzeugt die individuelle Intensität, Grundfrequenz und Segmentdauer
eines einzelnen Abschnitts und die Signalgenerierung beinhaltet lediglich einen
Synthetisator, welcher die eingehenden Daten in eine akustische Ausgabe verwandelt.
4.2.5 Sprechererkennung
Hiermit wird die Identifikation oder Verifikation eines bestimmten Sprechers vorge-
nommen. Bestehende Sprachmuster der betreffenden Person werden nach sprachlichen
Charakteristika beschrieben, abgespeichert und eingehende Sprachsignale hinsichtlich ihrer
Charakteristika damit verglichen [RABINER95].](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-11-320.jpg)
![Theorien / Konzepte
12
4.2.6 Menschliche Sprachwahrnehmung versus maschinelle
Spracherkennung
Zunächst stellt sich die Frage, welches die grundlegenden Wahrnehmungseinheiten
sind: Phoneme, Wörter oder sonstige Einheiten wie zum Beispiel Silben. Gegen Wörter als
kleinste relevante Einheiten spricht, dass Menschen auch unbekannte Wörter und Neo-
logismen korrekt erkennen können. Es ist ebenfalls unwahrscheinlich, dass die Sprach-
wahrnehmung ausschließlich auf Phonemen beruht, da keine 1 : 1 Übereinstimmung
zwischen akustischen Signalen und erkannten Phonemen besteht: je nach Kontext wird
dasselbe Sprachsignal unterschiedlich interpretiert. Außerdem werden auch solche Pho-
neme als spontan richtig erkannt, die zum Beispiel wegen eines Störgeräusches gar nicht
hörbar waren, die sich aber aus dem vorausgehenden Kontext ergeben. Dies deutet darauf
hin, dass bei der Sprachwahrnehmung nicht isolierte Phoneme aneinandergereiht werden,
sondern dass von Anfang an auch höhere Verarbeitungsstufen beteiligt sind (Wort-
erkennung, syntaktische Analyse, semantische Analyse), die parallel ablaufen und deren
Ergebnisse berücksichtigt werden können.
Bei der Sprachwahrnehmung sind also bottom-up und top-down-Prozesse kombiniert.
Für die maschinelle Spracherkennung ergibt sich somit: Bezüglich der Wahrnehmungs-
einheiten kommen diejenigen Systeme den menschlichen Prozessen am nächsten, die auf
mehreren Ebenen arbeiten und sich nicht zum Beispiel auf den Mustervergleich ganzer
Wörter oder die Erkennung anhand akustischer Signale von Phonemen beschränken
[GREENBERG98].
4.2.7 Problemfelder der Spracherkennung
Es gibt einige Besonderheiten gesprochener Sprache, die bei der Gestaltung der
benutzerzentrierten Sprachinteraktion beachtet werden müssen. Der alineare Ablauf (Stot-
tern, Selbstkorrektur), Bestätigungsanfragen („Sind Sie sicher“) oder Feedback („Jaja,
kann ich verstehen“), prosodische und nicht-verbale Modulation der Sprache und Beein-
flussung wechselseitiger Kommunikation durch Unterbrechungen sind einige davon. Wie
in Abbildung 3 verdeutlicht, kommt es dadurch zu einer Störungen im
Kommunikationsprozess und eventuellen Fehlinterpretationen der Aussagen des
Kommunikationspartners. Im Folgenden wird auf einige dieser Phänomene und mögliche
Lösungsansätze in der maschinellen Spracherkennung näher eingegangen.](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-12-320.jpg)
![Theorien / Konzepte
13
Abbildung 3 - Kommunikation / technnisches Modell
4.2.7.1 Linguistische Unterschiede
Identische Phoneme können unterschiedlich akustisch realisiert werden. Daher funk-
tionieren Spracherkennungssysteme dann am besten, wenn sie von jedem Benutzer selbst
trainiert werden. Ist dies nicht möglich oder nicht erwünscht (sprecherunabhängige
Spracherkennung), so sollte das System von möglichst vielen Sprechern trainiert werden.
Als Muster wird dann ein Mittelwert gespeichert. Manche Systeme passen sich zusätzlich
während der Bedienung an den jeweiligen Benutzer an.
4.2.7.2 Individuelle Sprecherfaktoren
Die Form des Vokaltraktes, Alter, Geschlecht, regionale Zuordnung beeinflussen die
akustisch-phonetischen Parameter ebenso wie Müdigkeit und mentale Verfassung. Auch
muss auf Satzbau und Betonung der einzelnen Worte geachtet werden [DESHMUKH02].
Für Einzelplatzsysteme kann ein sprecherspezifisches Training des Sprachmodells die
Sicherheit so weit erhöhen, dass praktisch keine Fehler mehr auftreten. Weitere positive
Faktoren sind hier die Konstanz der Umgebung und die hohe Qualität der Eingangssignale
in Abhängigkeit des verwendeten Mikrophons. Dedizierte Headsets verbessern die
Erkennung so stark, dass sie bei den ersten Breitenanwendungen der bestimmende Faktor
für die Sicherheit waren. Auch bei Systemen, die auf einzelne Sprecher trainiert sind,
müssen aber weitere Faktoren, wie emotionaler Zustand und Hintergrundgeräusche,
berücksichtigt werden. Insbesondere im öffentlichen Bereich sind jedoch weder
sprecherabhängige Sprachmodelle noch aufwändige Headsets realisierbar. Verschärfende
Faktoren sind die stark variierenden Modulationen und die typisch gravierenderen
Nebengeräusche [YOON]. Auf diese unterschiedlichen Übertragungskanäle bezieht sich
der nächste Abschnitt.
Verstehen
Übersetzung
Empfangen
Störung
Idee
Übersetzung
Senden
Sender Empfänger](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-13-320.jpg)
![Theorien / Konzepte
14
4.2.7.3 Unterschiedliche Übertragungskanäle
Diese Einflüsse wirken sich primär auf die erste Stufe der Spracherkennung, die
Identifikation einzelner Phoneme aus. Dabei wirken im wesentlichen drei Faktoren:
• Statische Hintergrundgeräusche (Rauschen, Umgebung) können Teile des Sprach-
signals überdecken
• Akustische Einzelereignisse, die nicht der Sprache zuzuordnen sind
• Begrenzung und Verfälschung der eingehenden Audiodaten durch den Über-
tragungskanal (Grenzfrequenzen insbesondere bei Mobiltelefonen, Artefakte bei
psychoakustischer Kompression)
Diesen Faktoren wird mit unterschiedlichen Verfahren begegnet. Zur Kompensation
statischer Störfaktoren werden Spracherkennungssysteme manchmal mit Störvermin-
derungssystemen kombiniert. [FELLBAUM91] J. Droppo et. al. [DROPPO02] haben ein
Verfahren entwickelt, das die Isolation der Nutzinformation deutlich verbessert.
Verfälschende Einzelereignisse beeinträchtigen meist nur die Erkennung einzelner
Phoneme. Die Heranziehung linguistischer Kontextinformationen in den in Kapitel 4.2.2
erläuterten hierarchischen HMM und dynamischen Bayesschen Netzen kann diese Fehler
deutlich minimieren.
Die dritte Störform ist stark applikationsabhängig und wird durch entsprechende
Kalibrierung der Aufnahmetechnik oder spezifische Modellierung des Übertragungskanals
ausgeglichen [BLOMBERG94].
4.2.7.4 Unflüssige Sprechweise:
Unflüssigkeiten wie Selbstkorrektur, Fehlstarts, spontane Wiederholungen und Füll-
silben beziehungsweise -wörter stellen eine große Hürde für sprachgesteuerte Systeme dar.
Es wird bisher noch nach zuverlässigen Möglichkeiten gesucht, sie anhand von
prosodischen, syntaktischen oder semantischen Mustern zu erkennen. Tabelle 1
verdeutlicht, wie oft solche Fehler im Mensch-Mensch-Dialog im Gegensatz zum Mensch-
Maschine-Dialog vorkommen.](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-14-320.jpg)
![Theorien / Konzepte
15
Mensch-Mensch-Dialog
2-Personen-Telefonat 8,83
3-Personen-Telefonat 6,25
2-Personen-Gespräch 5,50
Monolog 3,60
Mensch-Maschine-Dialog
Unbeschränkter Dialog 1,74-2,14
Strukturierter Dialog 0,78-1,70
Tabelle 1 - Fehlerhäufigkeiten pro 100 Wörter
4.2.7.5 Lange Sätze = Fehler?
Komplizierte und lange Satzkonstruktionen sind sehr fehleranfällig. Sätze mit ein bis
sechs Wörtern bergen 0,66 Fehler und Sätze mit sieben bis 18 Wörtern 2,81 Fehler. Man
könnte mit der Frage schon eine kurze Antwort implizieren und damit die Fehler um 30 bis
40 Prozent reduzieren. Forschung im Auftrag von Telefongesellschaften hat dies gezeigt.
Systeme können durch die Art und Weise, in der Anfragen an den Benutzer gestellt
werden, beeinflussen, in welcher Weise er antworten wird (offene, kurze Antworten
werden unterstützt). [OVIATT95]
4.2.7.6 Hyperartikulation
Hyperartikulation ist der Versuch des Benutzers, betont deutlich zu sprechen, um dem
System die Spracherkennung zu erleichtern [FISCHER99]. Sie tritt meistens auf, nachdem
das System signalisiert hat, dass es eine Eingabe nicht verstanden hat. Dadurch werden
weitere Fehler provoziert (Spiral Errors) und die Frustrationsgefahr steigt [KARAT99]. In
der Praxis führt das oft dazu, dass ein Benutzer die Arbeit abbricht.
Bekannte Kompensationsverfahren sind die Anpassung der Frequenzebene, die breite
Modellierung der Vokale in den Referenzdaten und die Nutzung spezieller Erkennungs-
modelle bei Hyperartikulation [OVIATT89], [SOLTAU98].
Versuche haben gezeigt, dass Hyperartikulation meist eine direkte Erhöhung der
Sprechfrequenz und Variation der Sprachmelodie zur Folge hat. Dies kann zum einen
durch entsprechende Anpassung der Eingangsfilter an Tonhöhe und Lautstärke ausge-
glichen werden. Zum anderen erleichtert es vor allem die Erkennung von Hyper-
artikulation, da sich die üblichen Frequenzmuster stark verändern.](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-15-320.jpg)
![Theorien / Konzepte
16
Die gleichen Versuche haben auch eine deutliche Veränderung im Zeitverhalten der
Sprecher ergeben. Im Durchschnitt stieg die Dauer einer Sprachprobe bei Hyperarti-
kulation um 20% an. Diese Erhöhung tritt jedoch nicht gleichmäßig auf, sondern wird
besonders bei stimmhaften Konsonanten und Zischlauten sichtbar.
Mittels Erkennung von Hyperartikulation, Modellierung der veränderten Sprachform
und Einbeziehung spezifischer Basisdaten kann der jeweils wahrscheinlichste Fall ermittelt
und verfolgt werden. Allein diese Maßnahmen erhöhen die Erkennungsrate um zwei bis
fünf Prozent [SOLTAU00].
4.2.8 Verbesserung der Spracherkennung durch Multimodalität
und eingegrenztes Vokabular
Die Anwendung der Spracherkennung bestimmt, welche Störfaktoren einzubeziehen
sind und mit welchen Methoden die Erkennungsrate erhöht werden kann. Sind die oben
erläuterten Verfahren nicht ausreichend, sind korrigierende Benutzereingriffe über andere
Eingabemodi erforderlich. Es ist nämlich sehr natürlich, nach einer fehlgeschlagenen
Eingabe das Medium zu wechseln und zwar dreimal mehr als sonst. Benutzer erfassen
recht schnell, welche Eingabemethode am einfachsten ist. Walker [WALKER89] und
Cohen [COHEN89] schlagen deshalb vor, die Anwendung natürlicher Sprache mit
grafischen Interfaces zu kombinieren. Gerade im Zusammenspiel mit anderen Ein- und
Ausgabekanälen kann durch zusätzliche kontextabhängige Eingrenzung des Vokabulars
die Spracherkennung deutlich verbessert werden. Dazu müssen verschiedene Formen der
Sprachgestaltung abgewogen werden. Grundsätzlich kann zwischen freien, natürlichen und
künstlichen, restriktiven Sprachen unterschieden werden. Letztere erfordern eine
Einlernphase beim Benutzer oder sehr klare und eindeutige Benutzerführung durch andere
Interfaceelemente [TENNANT83]. Trotzdem zeigen sich domänenspezifische künstliche
Sprachen als deutlich robuster und effizienter, wobei Variationen und Redundanz in
Vokabular und Syntax sogar die Nutzerakzeptanz erhöhen können. Es bleibt also offen, ob
der Nutzer die natürliche oder künstliche Sprachen präferiert. Es kommt anscheinend auf
die Qualität der Erkennung, den Kontext der Anwendung und die noch vorhandenen
Modalitäten an.](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-16-320.jpg)
![Theorien / Konzepte
17
4.3 Die Gestaltung der intelligenten Benutzungsschnittstelle
durch adaptive Dialogsysteme
Im letzten Abschnitt wurde Sprachinteraktion als wichtiger Teil eines multimodalen
Interfaces behandelt. Wie bereits erwähnt, dient Multimodalität dazu, die für das Ziel des
Nutzers passende Interaktionsform zu wählen. Im Gegensatz zu einer funktionsbasierten
Interaktion, bei der das Vokabular durch das System definiert wird, führt eine zielbasierte
Interaktion in natürlicher Weise zu einer konversationalen Schnittstelle, da es für das
System in bestimmten Fällen notwendig werden kann, für die präzise Bestimmung des
Ziels fehlende Informationen beim Nutzer nachzufragen. Um konversationale Interaktion
zu unterstützen, bedient sich das System auch non-verbaler Interaktionstechniken (z. B.
Gestik, Mimik), die zum Beispiel durch anthropomorphe Interfaceagenten, auf die im
Kapitel 4.4 näher eingegangen wird, realisiert werden können. In diesem Kapitel geht es
zunächst um die Konzepte, die der adaptiven Dialoggestaltung zwischen Mensch und
Maschine zugrunde liegen.
4.3.1 Die vier Seiten einer Nachricht
Menschen nehmen nicht nur das gesprochene Wort, sondern viele Ebenen eines
Dialoges wahr. Dazu gehören beispielsweise der Tonfall, die Schnelligkeit des Sprechens,
Pausen, Lachen, Seufzen und nonverbale Kommunikation wie Körperhaltung oder Aus-
drucksbewegungen. „Man kann nicht nicht kommunizieren“, wie schon Paul Watzlawik
treffend bemerkte. Schulz von Thun [SCHULZ00] formulierte die in Abbildung 4
dargestellten vier Seiten einer Nachricht: Sachinhalt („Worüber möchte ich informieren“),
Selbstoffenbarung („Was ich von mir selbst kundgebe“), Beziehungsaspekt („Was ich von
dir halte und wie wir zueinander stehen.“).
Abbildung 4 - Kommunikation nach Schulz von Thun
,'+"'.( ,%/0.;/08( -?-:.+$'.(
,%/0;+0%$8(
6'4;'0"+$(
!--'$$(
,'$*::'+/
&%0."+$(](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-17-320.jpg)
![Theorien / Konzepte
18
Die Forschung in der künstlichen Intelligenz hat sich lange Zeit nur mit dem Erkennen
des Sachinhaltes befasst. Erst neuere Projekte - wie zum Beispiel adaptive Dialogsysteme
und intelligente Benutzeroberflächen - richten ihr Augenmerk auch auf die anderen Ebenen
der Kommunikation.
4.3.2 Benutzermodellierung
Es gibt zwei Arten von Modellen, die bei der Mensch-Computer-Kommunikation eine
Rolle spielen:
Mentales Modell/ Benutzermodell: Dieses Modell bildet der Benutzer bewußt oder
unbewußt über den Aufgabenbereich und das Computersystem.
Systemmodell/ Anwendungsmodell: Das ist ein Modell über den Anwendungsbereich
seitens eines Computersystems.
Die Voraussetzung mentaler Modelle ist das gemeinsame Wissen beider Kom-
munikationspartner. Die Aufgabe des Interfaces ist es, das mentale Modell des Benutzers
wiederzugeben und sich auf den Benutzer einzustellen.
Die Entwicklung von intelligenten Benutzungsschnittstellen erfordert also eine explizite
Modellierung des Benutzers (user modelling). Das bedeutet, das System sollte die Fähig-
keiten (abilities), die Ziele (goals), das Wissen (knowledge beziehungsweise beliefs) sowie
den emotionalen Zustand des Benutzers erkennen und in geeigneter Weise modellieren.
[RICH89] Üblicherweise spricht man beim Wissen eher von „beliefs“ als von „know-
ledge“, da der Begriff impliziert, dass die Ansichten des Benutzer auch durchaus falsch
sein können.
Das Erkennen des emotionalen Zustandes ist wichtig, um beispielsweise zu erkennen,
wann der Benutzer gelangweilt, über- oder unterfordert oder schlicht gestresst ist. Das Ziel
einer intelligenten Benutzeroberfläche soll es sein, sich den aktuellen Bedürfnissen des
Nutzers optimal anzupassen, also zum Beispiel im richtigen Moment Hilfestellungen
anzubieten. Ebenso sollte es je nach Vorwissen des Benutzers knappe oder ausführliche
Anweisungen geben und somit der Mensch-Mensch-Kommunikation näher kommen.
4.3.3 Überblick zu bestehenden Belief-Desire-Intention-
Verfahren für die Benutzermodellierung
Bestehende BDI-Verfahren (Belief, Desire, Intention) modellieren den Nutzer auf den
bereits oben genannten Ebenen. Die erste Ebene „Belief“ repräsentiert das vermutliche](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-18-320.jpg)
![Theorien / Konzepte
19
Wissen des Anwenders bezüglich der Problemdomäne. Üblicherweise teilt der Nutzer sein
Wissen nicht direkt mit, es muss indirekt aus der Interaktion geschlossen werden.
[KOBSA90]. Basierend auf sinnvollen Vorgaben für verschiedene Stereotypen, auf die im
Kapitel 4.3.5 näher eingegangen wird, kann dieses Bild im Laufe der Interaktion weiter
verfeinert werden.
Die konzeptionelle Trennung der beiden Elemente „Desire“ und „Intention“ trägt der
Tatsache Rechnung, dass der Nutzer zwar genaue Vorstellungen über das gewünschte
Vorgehen haben kann, diese aber nicht zwingend für sein tatsächliches Ziel sinnvoll sind.
Im günstigsten Fall erweitert die Interaktion die Wissensbasis des Nutzers und unterstützt
ihn bei der Annäherung seiner kurzfristigen Absichten an seine realen Ziele. Horvitz und
Paek [HORVITZ01] gehen speziell auf die gezielte Beeinflussung des Nutzers ein und
analysieren die akustische Charakteristik aufgenommener Sprache in Hinblick auf
Zustimmung, Ablehnung und Reflektion.
Für die Pflege des Nutzermodells gibt es verschiedene Techniken, die auch kombiniert
werden können. Das gebräuchlichste Verfahren ist das ständige Abgleichen des internen
Modells auf Grund der direkten Handlungen und Eingaben. Dies hat den Vorteil, dass
Fehlschlüsse des Systems nur begrenzte Auswirkungen haben, es kann abstraktere Ziele
aber nur schwer abbilden.
Ein anderes Verfahren, das Allen et al. verfolgten [ALLEN80], schließt hingegen
unwahrscheinliche Modellierungen aus und verbessert so die Interpretation der Nutzer-
absichten. Rich leitet ein abstraktes Persönlichkeitsprofil aus den Aktionen des Nutzers ab.
Dies bietet zwar ein stabileres Modell, hat aber gleichzeitig auch den Nachteil, kaum
dynamisch auf offensichtliche Fehlbeurteilungen reagieren zu können. [RICH89]
4.3.4 Berücksichtigung des Arbeitsgedächtnisses in der
Dialoggestaltung
Wie oben erwähnt,müssen nicht nur die Ebenen „Belief“, „Desire“ und „Intention“
sondern auch die je nach Situation vorhanden Ressourcen des Dialogpartners bei der
Gestaltung der Schnittstelle berücksichtigt werden. Wie kann eine Überlastung des
Dialogpartners zustande kommen? Die Kapazität des menschlichen Arbeitsgedächtnisses
ist begrenzt.](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-19-320.jpg)
![Theorien / Konzepte
20
Extern gewonnene Informationen werden in „drei Stufen“ verarbeitet [ATKINSON68]:
• Aufnahme in das Arbeitsgedächtnis („Kurzzeitgedächtnis“)
• Abgleich mit langfristig gespeicherten Strukturen
• Integration in die langfristig gespeicherten Strukturen
Das Arbeitsgedächtnis ist der aktive Teil des menschlichen Gedächtnisses
[EYSENCK94] und limitiert auf durchschnittlich 7 ± 2 voneinander unabhängige seman-
tische Einheiten (chunks). Diese magische Zahl hat sich bis heute gehalten, wird aber
differenziert betrachtet. [SHIFFRIN94]
Diese Limitierung muss bei der Dialoggestaltung beachtet werden, um eine
Informationsüberflutung zu vermeiden. Belastung oder Nebenbeschäftigungen können
diese Kapazität noch weiter einschränken. Mit anderen Worten: ein Benutzer, der eine
komplizierte Aufgabe lösen muss oder ein Dialogpartner, der sich einer schwierigen
Situation gegenüber sieht, ist weniger aufnahmefähig als üblich. Das System muss diesen
Umstand erkennen und sich dem anpassen, zum Beispiel, indem es langsamer
kommuniziert, einfachere Satzkonstruktionen benutzt, knappere Anweisungen gibt, mehr
Pausen macht oder Ähnliches.
Es können viele Aspekte des Sprechens auf die Arbeitsgedächtnisbelastung des
Dialogpartners hindeuten. In einer explorativen Studie von Schäfer und Weyrath 1996
[SCHÄFER96] wurde als Domäne eine Feuerwehrnotrufzentrale (FNZ) gewählt. Elf
Mitarbeiter der FNZ, die regelmäßig Notrufe entgegennehmen, dienten dabei als
Versuchspersonen, da sie besonders viel Erfahrung im Umgang mit solchen Ressourcen-
beschränkungen haben. Notrufe werden nämlich meist in großer Eile geführt. Die
wenigsten Anrufer bereiten sich auf das Gespräch vor. Daher ist mit einem hohen Grad an
Spontansprache zu rechnen. Da die Anrufer zusätzlich durch die Vorfälle, die um sie
herum passieren, abgelenkt sind, können selbst einfache Fragen hohe Anforderungen an
das Arbeitsgedächtnis des Anrufers stellen. Aufregung, Ablenkung, Geschwindigkeit und
Qualität der Antwort zeigten sich hier als Ursachen und Folgen von Arbeitsge-
dächtnisbelastung.
Ein wichtiger Aspekt der ressourcenadaptiven Dialogführung zwischen Mensch und
System ist also die richtige Auswahl von Äußerungen und damit verbunden die richtige
Einschätzung der Anforderungen, die die Äußerung an das Arbeitsgedächtnis des
Dialogpartners stellt. Aber oft ist es nicht möglich, sich ein vollständiges Bild über die](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-20-320.jpg)
![Theorien / Konzepte
21
Situation zu machen, in der sich der Dialogpartner befindet. Neue Informationen, die von
der getroffenen Einschätzung abweichen, führen zu einer Veränderung des Bildes über die
Arbeitsgedächtnisbelastung des Dialogpartners. Die Einschätzungen und Schluss-
folgerungen, die das Dialogsystem dazu ziehen muss, sind also unsicher und
zeitveränderlich. Eine Technik der Benutzermodellierung sollte also idealer Weise mit
unsicherem und zeitveränderlichem Wissen umgehen und auf dieser Basis Schluss-
folgerungen ziehen können. Wie wird das nun realisiert? Welche Prinzipien aus der
Mensch-zu-Mensch-Kommunikation machen sie sich zunutze? Im Folgenden werden die
Ansätze der Stereotypen und der Bayesschen Netze vorgestellt.
4.3.5 Stereotypen
Menschen neigen dazu, Gesprächspartner auf Grund weniger Wahrnehmungen und
Informationen zu kategorisieren. Stereotypen dienen hier als soziale Schemata. Eine ähn-
liche Technik kann man sich auch für künstlich intelligente Dialogsysteme zu Nutze
machen. [RICH89]
Es geht dabei um die leichtere Identifikation von häufig vorkommenden Eigenschaften
und die Übernahme gewohnheitsmäßiger Handlungen der Nutzer. Ein Stereotyp ist eine
Sammlung von Eigenschaften, die unter einem gemeinsamen Namen zusammengefasst
sind.
Stereotypen lassen sich hierarchisch in einer Baumstruktur ordnen. Die Wurzel des
Baumes der allgemeinste Stereotyp, über den relativ wenig bekannt ist. Jeder Knoten des
Baumes kann eine beliebige Anzahl von Kindknoten haben. Die Kindknoten erben die
Eigenschaften des Elternknotens, können sie jedoch erweitern und verfeinern. Die
Kindknoten bilden dadurch Unterklassen der übergeordneten Stereotypen.
Beispielsweise könnte man den allgemeinsten Stereotypen „Mensch“ in die Kindknoten
„männlich“ und „weiblich“ unterteilen. Den Männern schreiben wir die Eigenschaften
„guckt gern Fußball“ und „trinkt gern Bier“ zu. Frauen hingegen „gehen gern ins Ballet“
und „trinken gern Wein“.
Auf Grund seiner Wahrnehmungen über den Dialogpartner kann das System denjenigen
Stereotypen ermitteln, auf den diese Wahrnehmungen am besten zutreffen. Alle Eigen-
schaften dieses Stereotypen werden dem Partner zugeschrieben. Wenn das System
beispielsweise erfährt, dass der Dialogpartner gern Fußball sieht, kann es die Schluss-](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-21-320.jpg)
![Theorien / Konzepte
22
folgerung ziehen, dass es sich um einen Mann handelt und er dann wohl auch gern Bier
trinkt.
Selbstverständlich muss das System mit jeder neu gewonnenen Information seine
bisherige Kategorisierung des Partners neu bewerten und gegebenenfalls einen anderen
Stereotypen als Modell wählen, so wie wir bei unseren Gesprächspartnern immer neue
Informationen sammeln und gegebenenfalls unsere Meinung revidieren.
Dabei können auch Konflikte auftreten - beispielsweise könnte man an eine Person
geraten, die gern Fußball schaut und gern Wein trinkt beziehungsweise nicht gern Bier
trinkt.
Solche Konflikte müssen vom System aufgelöst werden. Üblicherweise wird zu jeder
dem Nutzer zugeschriebenen Eigenschaft ein Confidence-Wert ermittelt und gespeichert,
der angibt, wie sicher sich das System ist, dass diese Eigenschaft tatsächlich zutrifft. Auf
diese Weise lassen sich mit relativ wenigen Informationen brauchbare Schlussfolgerungen
über das Gegenüber ziehen. Genau diese Eigenschaft ist der größte Vorteil dieses An-
satzes. Ein Nachteil ist, dass die Kategorisierung unter Umständen von außen schlecht
nachvollziehbar ist.
Ein bekanntes Beispiel ist das stereotypbasierte Bibliotheksauskunftssystem Grundy
von [RICH79, RICH89]. Grundy ist ein Dialogsystem, das ein Beratungsgespräch in einer
Bibliothek simuliert. Grundy übernimmt dabei die Rolle eines Bibliothekars, der dem Be-
nutzer bei der Auswahl seiner Lektüre behilflich ist. Um zu entscheiden, welche Bücher
der Benutzer gerne liest, verwendet Grundy stereotypisches Wissen über den Benutzer, das
im Laufe eines Dialogs zu einem individuellen Benutzermodell verfeinert wird.
Der dargestellte Stereotypenansatz könnte auch gut in der sprachcomputerbasierten
Anrufbeantwortung und -weiterleitung etwa bei der Pannenhilfe genutzt werden. Wenn
zum Beispiel jemand laut atmet oder stöhnt (Bedingung a) und schnell oder abgehackt
spricht (Bedingung b) ist zu schlussfolgern, dass eine schnelle Handlung beziehungsweise
Weiterleitung des Anrufes an die entsprechende Stelle UND die Beruhigung des Anrufers
erforderlich ist. Der Sprachcomputer könnte die Eckdaten erfragen (wie bei anderen
Anliegen auch) UND etwas Beruhigendes antworten („Es wird so schnell wie möglich
jemand bei Ihnen sein. Bitte bleiben Sie ruhig!“), damit sich der Anrufer verstanden und
betreut fühlt. Natürlich sind hierbei wie oben bereits erwähnt Fehlinterpretationen möglich.](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-22-320.jpg)
![Theorien / Konzepte
23
Deshalb wäre es zum Beispiel ethisch bedenklich, einen Sprachcomputer in der Feuer-
wehrnotrufzentrale einzusetzen.
4.3.6 Bayessche Netze
Eine weitere Technik der Benutzernodellierung, die schon im den Kapiteln 4.2 und 4.3
kurz vorgestellt wurde, sind die Bayesschen Netze. Sie beruhen auf dem Satz von Bayes,
der Aussagen über die Wahrscheinlichkeiten voneinander abhängiger Ereignisse trifft.
Bayessche Netze sind gerichtete, azyklische Graphen. Jeder Knoten des Graphen entspricht
einem Ereignis. Eine Kante von A nach B bedeutet, dass Ereignis B (zum Beispiel Alarm)
von Ereignis A (zum Beispiel Einbruch) abhängig ist. Für Ereignisse, die keine
Vorgängerknoten im Netz, das heißt, keine eingehenden Kanten, haben, sind sogenannte a
- priori - Wahrscheinlichkeiten gegeben. Das Ereignis tritt mit einer bestimmten Wahr-
scheinlichkeit ein und ist von allen anderen Ereignissen unabhängig. Für abhängige Ereig-
nisse (solche mit Vorgängerknoten) ist eine Wahrscheinlichkeitsmatrix gegeben, die die
Wahrscheinlichkeit des Eintretens in Abhängigkeit vom Eintreten der Vorgängerereignisse
beschreibt. [CHARNIAK91] In Abbildung 5 sieht man die einzelnen Wahrscheinlichkeiten
für das Auftreten der beiden Ereignisse „Einbruch“ und „Alarm“ in wechselseitiger
Abhängigkeit.
Abbildung 5 - Bayessche Netze / Wahrscheinlichkeiten
Inwiefern ist das nun für die Benutzermodellierung relevant ? Durch die Vorhersage der
Wahrscheinlichkeiten können Annahmen über Benutzereigenschaften formuliert werden,
die für die Interaktion mit dem Anwender nützlich sind. Nach erfolgter Evidenz durch
• Azyklischer, gerichteter Graph
• P(Einbruch|Alarm) = 0,00095
Einbruch Pa priori = 0,001 Alarm
Einbruch Kein
0,010,95Alarm
0,990,05Kein Alarm](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-23-320.jpg)
![Theorien / Konzepte
24
beobachtete Symptome werden die Einschätzungen der Knoten entsprechend der
vorliegenden Situation angepasst. Ein Beispiel dafür ist Dialogsystem PRACMA.
[JAMESON95] Es modelliert bewertungsorientierte Dialoge am Beispiel von
Verkaufsgesprächen. Die Domäne ist der Gebrauchtautomarkt. Dabei wird von einer nicht
ausschließlich kooperativen Dialogsituation ausgegangen: Der Käufer möchte dem
Verkäufer möglichst detaillierte Informationen entlocken und das Auto zu einem möglichst
geringen Preis erwerben. Der Verkäufer möchte negative Fakten über das Auto
verschweigen und das Auto dem Kaufinteressenten möglichst positiv darbieten. PRACMA
kann jeweils eine der Dialogrollen (Käufer/Verkäufer) übernehmen.
In der bisher betrachteten Form sind Bayessche Netze nur für die Modellierung nicht-
zeitabhängigen Wissens geeignet. Eine Erweiterung dieses Konzeptes, die so genannten
dynamischen Bayesschen Netze, erlaubt genau das. [DAGUM92, GHARAMANI98]
Dynamische Bayessche Netze teilen den zu modellierenden Zeitraum in Zeitscheiben
von endlicher Dauer ein, diskretisieren also den kontinuierlichen Zeitverlauf. Es wird nun
zwischen drei Arten von Knoten unterschieden: statische Knoten sind zeitunabhängig und
existieren außerhalb der Zeitscheiben. Somit sind die bisher betrachteten Netze ein Spe-
zialfall der dynamischen Bayesschen Netze, wobei alle Knoten statisch sind. Temporäre
Knoten existieren nur in einer einzigen Zeitscheibe, typischerweise sind das Knoten von
Beobachtungen. Die zu modellierende zeitveränderliche Eigenschaft wird durch dyna-
mische Knoten dargestellt. Das sind Knoten, die in jeder Zeitscheibe existieren und über
die Zeitscheiben hinweg miteinander verknüpft sind. Die Wahrscheinlichkeit der Eigen-
schaft in einer Zeitscheibe ist dadurch immer abhängig von ihrer Wahrscheinlichkeit in der
letzten Zeitscheibe.
Bayessche Netze sind also in der Lage, unsicheres und zeitabhängiges Wissen
darzustellen und daraus Schlüsse zu ziehen. Sie sind durch Computer verhältnismäßig
leicht und effizient berechenbar. Der größte Nachteil ist, dass das Netz als solches – in-
klusive der Wahrscheinlichkeitsmatrizen - von einem Menschen modelliert werden muss.
Die Qualität dieser Modellierung ist wesentlich für die Qualität der Vorhersagen.
Wofür werden nun die Bayesschen Netze in der Mensch-Computer-Kommunikation
noch angewendet ? Wie wir weiter oben gesehen haben, sind sie einerseits wichtig für die
Modellierung der Sprachinteraktion. Des Weiteren funktionieren viele Agenten, auf die im
nächsten Kapitel näher eingegangen wird, auf der Basis von Bayesschen Netzen.](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-24-320.jpg)
![Theorien / Konzepte
25
Das multimodale Präsentationssystem PPP benutzt Bayessche Netze in seiner
Benutzermodellierungskomponente PEDRO um die Verständlichkeit der Präsentation
technischer Anleitungen vorherzusagen. [MULKEN96], Auf diesen Versuch wird später
eingegangen.
Ein weiteres Beispiel ist das Lumiere-Projekt [HORVITZ98]. In diesem Projekt wird
ein Assistent entwickelt, der den Benutzer bei der Benutzung seiner Software unterstützt.
Der Prototyp dieses Assistenten dient als Basis für den Office Assistent im Microsoft
Office Paket.
Abbildung 6 - Agent im Microsoft Office : Karl Klammer
Der MS-Office-Assistent versucht, aus dem Verhalten des Benutzers dessen Absichten
zu schlussfolgern und bei Bedarf Hilfe anzubieten. Beim Benutzer wird dadurch der
Eindruck erweckt, dass der Agent „mitdenkt“. Der Prototyp verwendete dazu die beschrie-
benen Bayesschen Netze. Für die Verkaufsversion wurden die Bayesschen Netze durch
einen zwar einfacheren, aber ähnlichen Algorithmus ersetzt. [ECONO01]
Im Folgenden wird näher auf den Agentenbegriff eingegangen und verschiedene
Studien zur Gestaltung von solchen Agenten als Teil einer intelligenten Benutzungs-
schnittstelle vorgestellt.](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-25-320.jpg)
![Theorien / Konzepte
26
4.4 Interfaceagenten als multimodale Benutzungsschnittstelle
Der Begriff des „Agenten“ ist facettenreich. Speziell ein Software- oder Interfaceagent
bezeichnet in der Regel ein Programm, dessen Funktion als das eigenständige Erledigen
von Aufträgen oder Verfolgen von Zielen in Interaktion mit einer Umwelt beschrieben
werden kann. Interface-Agenten fungieren als Bindeglied in der Mensch-Computer-Inter-
aktion. Dazu müssen Agenten Fähigkeiten der Wahrnehmung, des Handelns und der
Kommunikation miteinander verbinden und, bezogen auf eine zu erfüllende Aufgabe,
situationsangemessen ein- und umsetzen können. Technisches System und Interface-
Agenten verbinden sich dabei zu einem teilautonomen System (siehe Abbildung 7),
welches Anteile seiner Funktion unabhängig von direkter Steuerung durch Benutzer
erbringen kann („indirektes Management“).
Abbildung 7 - Agenten als Bindeglied in der Mensch-Maschine-Kommunikation (Wachsmuth)
Wie sollten solche Agenten beschaffen sein, damit der Benutzer sie akzeptiert und
entsprechend mit ihnen interagiert?
4.4.1 Der Turing – Test und Eliza als Beginn der Forschung zum
Anthropomorphismus in der Mensch-Computer-
Interaktion
Bereits im Jahre 1950 schlug Alan M. Turing [TURING50] seinen viel diskutierten Test
vor. Es ist dabei die Aufgabe der Versuchsperson, die sich in einem seperaten Raum
aufhält, anhand eines textbasierten Frage-Antwort-Spiels festzustellen, bei welchem ihrer
Gesprächspartner es sich um eine Frau handelt. Die Aufgabe der männlichen Versuchs-
person ist es, die Versuchsperson zu täuschen, indem sie vorgibt, eine Frau zu sein. In
einer zweiten Phase wird die weibliche Gesprächspartnerin gegen eine Maschine
ausgetauscht und das Spiel wiederholt. Wenn sich der Fragesteller nun ebenso oft falsch
Interface-
agenten
Technisches
System
Mensch
Teilautonomes System](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-26-320.jpg)
![Theorien / Konzepte
27
entscheidet, wie in der ersten Phase des Tests, kann der Maschine Intelligenz zugesprochen
werden. Im Jahre 1966 entwarf Josef Weizenbaum [WEIZENBAUM66] ein Computer-
programm, das eine therapeutische „Unterhaltung“ lediglich durch Wiederholung von
Schlüsselwörtern führen konnte. Die Personen, die sich mit Eliza unterhielten, stellten eine
emotionale Beziehung zum Computer her und wiesen ihm menschliche Eigenschaften zu.
Weizenbaum formulierte daraus, dass das Vorhandensein von menschlichen Eigenschaften
bei Schnittstellen einen nicht unwesentlichen Einfluss auf das Verhalten des Benutzers hat.
Es geht also darum, die Schnittstelle so anthropomorph wie möglich zu gestalten. Unter
Anthropomorphismus versteht man die Übertragung von menschlichen Eigenschaften auf
Nichtmenschliches. [BROCKHAUS] Im Folgenden werden einige Studien zum
Anthropomorphismus von Mensch-Computer-Schnittstellen in Form von Agenten
vorgestellt.
4.4.2 Agenten als Avatare
Agenten können Avatare sein. In der Mythologie sind Avatare wiedergeborene Wesen,
die auf die Erde herabsteigen, um die bedrohte Weltordnung zu schützen. Als Avatare
bezeichnet man heute virtuelle Figuren, die meist einem Menschen (anthropomorph) oder
einfach einem bestimmten Körper (embodied) nachgebildet sind und sich dabei so
„natürlich“ wie möglich bewegen. Der Begriff ist nicht ganz klar definiert. Avatare können
nämlich auch virtuelle Repräsentanten von real existierenden Personen im 3D- Raum,
meist in einer verteilten Umgebung, sogenannten Communities, sein. Dabei können sie
entweder „eigenständig“ agieren und untereinander in Interaktion treten oder aber vom
Benutzer gesteuert werden [HOFBAUER00, FOLDOC]. Im Weiteren wird die
Verwendung des Begriffes „Avatar“ auf einen anthropomorphen Agenten bezogen.
4.4.3 Erwartungen an Agenten
Das Erscheinungsbild solcher Agenten reicht von einfachen cartoonartigen 2D-Figuren
bis hin zu animierten Agenten, die auf komplexen 3D-Modellen basieren und im Ansatz
kaum noch von Aufnahmen realer Personen (oder anderen realen Lebewesen) zu unter-
scheiden sind. In der Anwendung dienen solche Agenten zum Beispiel als Führer durch
virtuelle Welten oder sie demonstrieren Handlungsabläufe einer Gerätereparatur. Im
Bereich Lernsoftware übernehmen sie die Rolle virtueller Tutoren, erklären Sachverhalte,
erteilen auf Nachfragen Auskunft oder stellen selbst Fragen an den Schüler.](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-27-320.jpg)
![Theorien / Konzepte
28
Die Realisierung animierter Figuren ist nicht nur eine Herausforderung aus Sicht der
Computergrafik und -animation, sondern auch im Hinblick auf die glaubwürdige Ver-
haltensausstattung. Hier werden unter anderem folgende Anforderungen diskutiert: Model-
lierung von Persönlichkeit, Integration von Emotionsmodellen, Koordinierung unterschied-
licher Ausdrucksmittel wie Gesichtsausdrücke, Körpergesten und gesprochene Sprache.
Die Erwartungen an Agenten sind hoch. Durch höheren Unterhaltungswert, verbesserte
Aufmerksamkeit, intelligentes Feedback etc. sollen sie Lernerfolge maximieren. Die
Interaktion zwischen Nutzer und Computer soll mit ihrer Hilfe vereinfacht, verbessert und
intuitiver gestaltet werden. Computerspielen sollen sie zu besserem Unterhaltungswert
verhelfen. Mit den Agenten sollen neue zusätzliche und bessere Möglichkeiten zur
gezielten Beeinflussung des Nutzerverhaltens zur Verfügung stehen. Aber halten
Embodied Conversational Agents bisher was wir uns von ihnen versprechen?
4.4.4 Agentenrepräsentation
King und Ohya [KING96] verglichen Agentenrepräsentationen. Die Autoren fragten
sich, wie die Repräsentation von Agenten die von Nutzern wahrgenommenen Eigen-
schaften beeinflussen. Die 18 Probanden bewerteten die dreidimensionale menschen-
ähnlichste Form signifikant häufiger als „Agenten“ als andere anthropomorphe und nicht-
anthropomorphe Formen. Die Versuchspersonen schätzten die Gruppe der anthropo-
morphen Formen als intelligenter und „agentenhafter“ ein als den Rest der Stimuli. Am
intelligentesten und „agentenhaftesten“ schätzten sie die menschlichen Formen mit
zufälligem Lidschlag ein.
Takeuchi und Naito [TAKEUCHI95]) ließen in ihrer Untersuchung zwei menschliche
Gegner ein Memory-ähnliches Kartenspiel am Computer spielen. Auf dem Display war
einmal ein Gesicht, ein anderes Mal ein dreidimensionaler Pfeil zu sehen. Das Display mit
dem Gesicht erzeugte mehr Augenkontakt als das Display mit dem Pfeil, fanden die
Autoren. Dies lässt darauf schließen, dass das Gesicht mehr Aufmerksamkeit der Pro-
banden auf sich zog. Andererseits lenkte es auch eher von der Hauptaufgabe ab. Die
Probanden empfanden das Display mit dem animierten Gesicht als unterhaltsamer als das
Display mit Pfeil. Andererseits empfanden die Versuchspersonen das Display mit dem
Pfeil als nützlicher, verglichen mit dem Display, auf dem das Gesicht abgebildet war.
Koda und Maes [KODA96] wollten herausfinden, ob es eher vorteilhaft ist, einen
Agenten mit einem Gesicht zu repräsentieren. Sie nutzten ein Poker-Spiel als Test-](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-28-320.jpg)
![Theorien / Konzepte
29
umgebung für ihre Studie. Die zehn Probanden spielten 18 Runden Poker gegen vier
Agenten. Die Probanden versuchten, die Gesichter und Gesichtsausdrücke zu deuten, was
sie von ihrer Aufgabe abhielt. Gesichter wurden als sympathisch - im Gegensatz zu
unsichtbaren Gegnern - und einnehmend im Pokerspiel angesehen. Je realistischer das
menschliche Gesicht, desto eher wurde es als intelligent, sympathisch und komfortabel
angesehen. Koda und Maes empfehlen deshalb, Agenten mit Gesichtern im Entertain-
mentbereich einzusetzen. Auch für Aufgaben, bei denen der Nutzer Engagement zeigen
muss (zum Beispiel bei Bildung und Training), sei ein solcher Agent von Vorteil.
4.4.5 Lerneffekt / Funktionalität
Van Mulken, André und Müller [MULKEN98] führten ein Experiment mit ihrem PPP
(„Personalized, Plan-based Presenter“) genannten System an 28 Versuchspersonen durch.
Bei der Darstellung eines technischen Systems (Flaschenzüge) fanden die Probanden die
Erklärungen leichter verständlich, wenn sie von dem animierten Agenten mit Zeigestock
anstatt nur mit Hilfe eines Zeigestocks gegeben wurden. Auch wurde der animierte Agent
als hilfreicher und unterhaltender angesehen als der Zeigestock. 50% der Probanden
würden eine Präsentation mit einem animierten Agenten bevorzugen, 43% würden dies
von dem zu präsentierenden Material abhängig machen und 7% wünschten sich Prä-
sentationen ohne animierten Agenten.
4.4.6 Interaktion mit Nutzer
Cassell und Vilhjálmsson [CASSELL99] beschäftigten sich damit, wie man das
kommunikative Verhalten von Avataren in grafischen Chats verbessern kann. Ist der
Nutzer damit beschäftigt, Nachrichten einzutippen, ständen die Avatare nur bewegungslos
herum. Dies liefe der natürlichen Kommunikation zuwider, denn hier ist ein beachtlicher
Teil non-verbale Kommunikation im Spiel. Zwar könnten die Nutzer in den neuesten Sys-
temen verschiedene Animationen oder emotionale Zustände aus einem Menü wählen, aber
non-verbale Kommunikation sei oft spontan und der Nutzer zu beschäftigt, um das Ver-
halten seines Avatars zu kontrollieren. Wäre es nicht wünschenswert, wenn Avatare au-
tonom kommunikatives Verhalten zeigen würden, fragten sich Cassell und Vilhjálmsson.
Hier stellt sich die Frage, was der Nutzer bevorzugt: direkte Manipulation oder Autonomie
des Agenten. Sie fragten die 24 Probanden, wie natürlich sie das Verhalten des Avatars
und die Interaktion fanden und stellten fest, dass die Nutzer des autonomen Systems dieses](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-29-320.jpg)
![Theorien / Konzepte
30
als natürlicher beurteilten als die anderen Systeme. Dies konnte man auch in der Inter-
aktion beobachten (höhere Aufmerksamkeit, längere Gespräche).
Die Autoren sehen sich in ihrer Schlussfolgerung unterstützt, dass die Nutzer Kontrolle
und Spaß primär dem Gespräch selbst entnehmen und sich durch die Kontrolle des Ver-
haltens ihres Avatars abgelenkt fühlen.
Dietz & Lang [DIETZ99] beschlossen, ihren Agenten mit selbst-generierten Emotionen
auszustatten. Mit dem Experiment versuchten sie herauszufinden, welchen Einfluss dies
auf die Benutzer hat. Die ca. 80 Probanden berichteten von mehr Gefühlen in der emo-
tionalen Bedingung. Andere signifikante Ergebnisse konnten nicht erzielt werden. Die
Tendenzen stimmen vorsichtig optimistisch.
Cassell und Thórisson [CASSELL98] präsentieren in ihrer Arbeit einen perso-
nifizierten, animierten Agenten mit der Fähigkeit, multimodale Konversation mit einem
Nutzer in Echtzeit durchzuführen. Mit diesem Agenten untersuchten sie zwei menschliche
Eigenschaften, die als besonders nützlich für konversationale Systeme herausgestellt
werden: emotional feedback und envelope feedback. Emotional feedback bezeichnet die
Technik, eine bestimmte Emotion durch einen bestimmten Gesichtsausdruck darzustellen.
Envelope feedback meint non-verbales Verhalten während eines Gesprächs von An-
gesichts zu Angesicht, die der animierte Agent als Antwort auf die kommunikativen
Aktionen des Nutzers generiert. Insgesamt unterstützen die Ergebnisse die Signifikanz von
envelope feedback über emotional feedback und rein inhaltliche Rückmeldungen. Manch-
mal redete der Nutzer zeitgleich mit dem Agenten. Das Ins-Wort-Fallen ist typisch für
Mensch-zu-Mensch Kommunikation. Der Agent hatte aber Probleme mit dem Ins-Wort-
Fallen, was wiederum der Grund für Zögern des Nutzers sein könnte.
4.4.7 Attribution von Persönlichkeitsmerkmalen
Sproull et al. [SPROULL96] haben die Verhaltensunterschiede des Nutzers bezüglich.
eines textuellen Interfaces versus eines Interfaces mit einem realistischen Gesicht und
verbaler Sprachausgabe in einer Studie mit 130 Versuchspersonen untersucht. Als
Anwendungsgebiet wurde die Karriereberatung gewählt. Hierzu wurde eine Modifikation
von J. Weizenbaums „Eliza“ herangezogen. Die Probanden attribuierten Persönlichkeits-
merkmale des Gesichtsinterfaces, die mit dem Aussehen verknüpft werden (soziale
Bewertung, Geselligkeit, intellektuelle Bewertung), anders als die des Textinterfaces. Der
Unterschied bei Persönlichkeitsmerkmalen, die nicht mit dem Aussehen verknüpft werden](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-30-320.jpg)
![Theorien / Konzepte
31
(Potenz, Aktivität, Emotionalität), fiel geringer aus. Bei den Gesichtsinterfaces beschrieben
sich die Probanden weniger entspannt und weniger selbstsicher. Probanden, die mit den
Gesichtsinterfaces arbeiteten, brauchten mehr Zeit zum Beantworten der Fragen der
psychologischen Tests, als die Probanden mit den Textinterfaces. Die Probanden, die das
Gesichtsinterface benutzten, stellten sich selbst positiver bezüglich Altruismus und sozialer
Erwünschtheit dar. Basierend auf der Hypothese, dass Frauen und Männer unterschiedlich
empfänglich für soziale Signale wie Gesichtsausdrücke sind, vermuteten die Autoren, dass
sich Männer und Frauen in ihren Antworten auf das Gesichtsdisplay mehr unterscheiden
werden als in Antworten auf das Textdisplay. Eine Unterscheidung gab es aber zwischen
den Applikationen. Männer reagierten positiver auf das Gesichtsdisplay und Frauen eher
auf das Textdisplay. Das könnte bei den Frauen auf die Unnatürlichkeit der Darstellung
des Gesichtes und bei den Männern auf die Neugier an der Technik zurückzuführen sein.
Was bedeutet Adaptivität für die Persönlichkeit? Moon und Nass [MOON96] haben
dies untersucht. 44 als dominant und 44 als unterwürfig eingeschätzte Probanden wurden
zufällig auf vier Versuchsbedingungen mit Agenten aufgeteilt. Die Autoren sprechen von
drei Ergebnissen.
1. Nutzer mögen Computer mit ihrem Persönlichkeitstyp.
2. Nutzer ziehen adaptive Computer denen vor, die über die Zeit konstant gleich
bleiben.
3. Die bevorzugte Richtung der adaptiven Änderung ist die des Persönlichkeitstyps
des Nutzers.
Reeves & Nass [REEVES96] fanden in der generellen Mensch-Computer (nicht speziell
Agenten-) Interaktion viele sozialpsychologische Aspekte bestätigt. Versuchspersonen, die
nach einer Lehreinheit zu ihrer Meinung über die Leistung des Computers befragt wurden,
formulierten eine positivere Antwort, wenn der Computer selbst die Frage stellte, als wenn
es ein anderer Computer oder eine schriftliche Befragung war. Alle Versuchspersonen
wiesen jedoch die Vermutung von sich, sie könnten ihre Bewertungen aus Höflichkeit
gegenüber dem Computer ändern. Die Versuchspersonen waren davon überzeugt, sie
hätten mehr geleistet, wenn der Computer ihre Leistung positiv bewertete. Unter diesen
Umständen mochten sie den Computer auch lieber und trauten ihm größere Leistungen zu.
Dies gilt unabhängig davon, ob das erfahrene Lob gerechtfertigt war oder nicht. Die
Autoren formulieren daraus, dass Computer oder Agenten so programmiert werden sollten,](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-31-320.jpg)
![Theorien / Konzepte
32
dass sie ihren Benutzern positive Rückmeldungen geben. Auch andere
sozialwissenschaftliche Erkenntnisse bezüglich Selbst- und Fremdurteil und
Persönlichkeitsstruktur aus der Mensch-Mensch-Kommunikation konnten in der Mensch-
Computer-Kommunikation bereits repliziert werden. Man könnte damit zu dem Schluss
kommen: Intelligente Maschinen werden von Menschen wie ihresgleichen behandelt.
[REEVES96, S. 251]
4.4.8 Evaluation der vorgestellten Studien
Die dargestellten Studien unterscheiden sich in der Art der untersuchten Animationen,
in der Art der Maße, mit denen die Effekte gemessen wurden und in der Art der An-
wendungsumgebung. Die Ergebnisse sind nicht immer statistisch signifikant. Dennoch
konnten einige Vermutungen erhärtet werden. So führte der Einsatz von animierten Agen-
ten bei Takeuchi und Naito, aber auch bei van Mulken et al. zu höheren Unterhaltungs-
werten. Und bei Sproull et al. zeigte sich, dass sich die Probanden tatsächlich in Anwe-
senheit eines Gesichtes eher so verhalten, wie es sozial erwartet wird. Für andere Vermu-
tungen konnten noch nicht einmal Hinweise gefunden werden: Zum Beispiel gab es in
Bezug auf den Lernerfolg und das Erinnerungsvermögen keinen Hinweis auf positive
Effekte durch den Einsatz von animierten Agenten. Es kristallisieren sich jedoch drei
wichtige Faktoren heraus, die die Wirkung von animierten Agenten ganz wesentlich mit zu
beeinflussen scheinen [DEHN00]:
• Domäne, Aufgabenstellung
• mögliche Informationsquellen (gibt es neben dem Gesicht noch weitere Quellen
wie etwa gesprochene Sprache oder eine Textausgabe?)
• Persönlichkeit und Eigenschaften des Agenten (sind uns Stimme und Gesicht
sympathisch?).
Diese Einflussfaktoren wurden jedoch in keiner Studie umfassend berücksichtigt. Die
Schwierigkeiten sind sicherlich unter anderem bedingt durch noch zu geringe Erkenntnisse
nicht nur im speziellen Gebiet der animierten Agenten, sondern auch in den involvierten
Wissenschaften. So sind zum Beispiel insbesondere die sozio-emotionalen Funktionen der
nonverbalen Kommunikation wenig erforscht [BENTE00]. Deshalb können in den Studien
nicht einfach die Bedeutung und die Effekte von einzelnen Einflussgrößen gemessen
werden. Diese müssen selbst erst noch bestimmt werden, um dann die erforderlichen
Instrumentarien und relevanten Variablen ermitteln zu können. Bente und Krämer](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-32-320.jpg)
![Theorien / Konzepte
33
[BENTE02] schlagen unter anderem einen „Bottom-Up-Ansatz“ vor. Dieser Ansatz basiert
auf dem in Kapitel 4.3.5 dargestellten Stereotypenprinzip. Verhaltensmuster sollen, ohne
sie bis ins Detail zu verstehen, in Datenbanken abgelegt werden, um bei Bedarf auf diese
„Verhaltenskonserven“ zurückgreifen zu können. Hierbei wird bewusst eine (zu Beginn
deutlich) eingeschränkte Interaktivität und Flexibilität in Kauf genommen. Über mehrere
Zwischenschritte sollen die feinen Regeln der Kommunikation herausgearbeitet werden,
um später dann regelbasierte Agenten implementieren zu können. Bisher mangelnde
Forschungsergebnisse macht auch die Evaluation von animierten Agenten schwierig:
Bisher sind die richtigen Variablen und Methoden um die Effekte der Agenten messen zu
können noch nicht gefunden.
4.4.9 Die Kombination von Agenten und Sprache im
multimodalen Interface
Die Kombination von Automatic Speech Recognition (ASR), Natural Language Pro-
cessing (NLP) und Agententechnologie ermöglicht die Implementation anwendungsspe-
zifischer Programme, die dem Benutzer nicht nur die Steuerung durch Sprache erlauben,
sondern auch aktiv Hilfe anbieten. Eine Weiterentwicklung dieses Systems nutzt
Sprachsynthese zur Ausgabe und ermöglicht den sinnvollen Einsatz in mobilen Systemen,
wie z.B. Fahrzeugen (vgl. Embassi-Projekt), bei denen Interaktion mit einem Bildschirm
nicht möglich oder wünschenswert ist. Durch weitere Kopplung mit Avatar-Techniken
werden in Echtzeit geführte audiovisuelle Dialoge mit natürlichsprachlichen Systemen
realisierbar [XUEDONG]. Der Einsatz von Agenten und Sprache als Teile von
multimodalen Interfaces scheint also sehr sinnvoll für den Benutzer zu sein. Im Folgenden
wird deshalb eine explorative Studie zu Sprachinteraktion und anthropomorphen
Intefaceagenten in einem prototypischen multimodalen System vorgestellt.](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-33-320.jpg)
![Explorative Studie zu Sprachinteraktion und anthropomorphen Interfaceagenten im
Rahmen des mUltimo-3D-Projektes am Heinrich-Hertz-Institut
34
5 Explorative Studie zu Sprachinteraktion und
anthropomorphen Interfaceagenten im Rahmen des
mUltimo-3D-Projektes am Heinrich-Hertz-Institut
In der Studie ging es vor allem um die explorative Untersuchung des Benutzer-
verhaltens auf diesem relativ neuen Forschungsgebiet. Basierend auf den im Theorieteil
vorgestellten Vorerfahrungen wurde speziell die Sprachinteraktion mit dem System und
einem anthropomorphen Interfaceagenten beobachtet und ausgewertet. Am Ende werden
die Ergebnisse vor dem Hintergrund bestehender Forschung diskutiert und weiterer
Forschungsbedarf abgeleitet.
5.1 Projektrahmen
Das Projekt mUltimo-3D ist ein vom Bundesministerium für Bildung und Forschung
(BMBF) finanziertes Projekt. Während einer Laufzeit von zwei Jahren (01/99 bis 12/01)
wurden neue Möglichkeiten der multimodalen Interaktion entwickelt. Ermöglicht wurden
diese neuen Interaktionsformen durch die Verbindung einer Anwendungsschnittstelle mit
einem 3D-Display und Systemen zur Erkennung von Augen- und Blickbewegungen und
Sprache sowie in späteren Versuchen Handgesten. Im Rahmen der Evaluation dieser
Systeme wurden Nutzertests durchgeführt. Ein ausführliches Evaluationskonzept für eine
multimodale Schnittstelle im Rahmen dieses Projektes findet sich bei Katharina Seifert
(2002). Der Schwerpunkt der vorliegenden Untersuchungsauswertung liegt auf der
sprachbasierten Interaktion.
5.2 Systembeschreibung
Die multimodale Bedienschnittstelle des mUltimo-3D-Systems für den Versuch bestand
aus Maus und Tastatur, einer sprecherunabhängigen Spracherkennung und einer Blick-
orterkennung. Die Spracherkennung basierte auf Viavoice Software Developers Kit von
IBM. Ca. 90 Wörter wurden pro Testanwendung relativ gut erkannt. Die Blickort-
erkennung ist eine Eigenentwicklung des Heinrich-Hertz-Instituts für Nachrichtentechnik
GmbH und basiert auf der Cornea-Reflex-Methode [LIU99]. Der Benutzer konnte wählen,
ob er eine Funktion durch Sprache, Tastatur, Maus oder Blick oder über die Kombination
dieser Modalitäten auslöste. Nicht alle Funktionen konnten über die Modalitäten Blick und
Sprache auf Grund ihrer Besonderheiten ausgelöst werden. Es wurden zwei Test-](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-34-320.jpg)
![Explorative Studie zu Sprachinteraktion und anthropomorphen Interfaceagenten im
Rahmen des mUltimo-3D-Projektes am Heinrich-Hertz-Institut
35
anwendungen mit multimodaler Interaktion entwickelt. Der erste Prototyp zur Kon-
struktion von 3D-Körpern heißt CAD-Raum und der zweite zur Suche und Betrachtung
von räumlichen und textuellen Informationen heißt Info-Browser. Der Hauptversuch wurde
mit beiden Testapplikationen im Vergleich durchgeführt. Diese Darstellung konzentriert
sich auf den dreidimensionalen CAD-Raum und den Prototypen eines dreidimensional
dargestellten Avatars.
Abbildung 8 - mUltimo3D
5.2.1 Das 3D-Display
Für die vorliegende Untersuchung wurde ein 3D-Display eingesetzt, das vom Heinrich-
Hertz-Institut entwickelt wurde und eine freie Betrachtung des Objektes ermöglicht. Diese
Displays basieren auf dem Prinzip des Richtungs-Multiplexing, das heißt die unterschied-
lichen perspektivischen Ansichten der Teilbilder sind nur aus bestimmten Richtungen zu
sehen [LIU99].
Sitzt der Betrachter in einer bestimmten Position vor dem Display, verschmelzen diese
beiden getrennten räumlichen Wahrnehmungen zu einem Bild. Das hat den Vorteil, dass
der Nutzer keine Spezialbrille tragen muss, um Dreidimensionalität wahrzunehmen.](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-35-320.jpg)





![Explorative Studie zu Sprachinteraktion und anthropomorphen Interfaceagenten im
Rahmen des mUltimo-3D-Projektes am Heinrich-Hertz-Institut
41
5.3.4 Theoriegeleitete Hypothesen zur Sprachinteraktion
Zu einigen dieser explorativen Fragestellungen wurden aus der bisherigen Forschung
konkrete Hypothesen gebildet:
• Der Mythos der Multimodalität, dass Sprache in einem multimodalen System
die herausragende Interaktionsform sei, wurde schon einige Male wider-
legt.[OVIATT99] Es kommt immer auf die Anwendungsform an. Im
untersuchten System stellte Sprache vor allem eine Zeitersparnis gegenüber der
Mausinteraktion dar und ein besonderes Training und damit Einstellen auf die
Modalität musste nicht erfolgen. Es wird deshalb vermutet, dass Sprache im
Sinne des Mythos die am häufigsten gewählte Interaktionsform ist.
H1 : Sprache > Maus > Blick
H0 : Sprache = Maus = Blick
• Die dargestellten Problemfelder der Spracherkennung (Hyperartikulation,
individuelle Sprecherfaktoren) existierten auch in unserem Versuch. Es wird
deshalb vermutet, dass die Sprachinteraktion über die Zeit abnimmt, weil
Frustrationseffekte durch Fehleingaben einsetzen.
H1 : Sprachbenutzung in Aufgabe 1 > Sprachbenutzung in Aufgabe 3
H0 : Sprachbenutzung in Aufgabe 1 = Sprachbenutzung in Aufgabe 3
• Die Zeitersparnis durch die Spracheingabe gegenüber der Eingabe per Maus und
die Natürlichkeit der Eingabeform könnte Auswirkung auf die Leistung bei der
Aufgabenbearbeitung haben. Es wird deshalb ein positiver Zusammenhang
zwischen Leistung und Sprachinteraktionshäufigkeit vermutet.
H1 : ! (Sprachbenutzung über alle Aufgaben mit Leistung über alle Aufgaben=) > 0
H0 : ! (Sprachbenutzung über alle Aufgaben mit Leistung über alle Aufgaben) = 0
5.3.5 Explorative Fragestellungen zum Avatar
• Wie verhält sich der Benutzer in der Interaktion mit dem Avatar?
• Unter welchen Bedingungen wird die Anwesenheit des Avatars gewünscht?
• Was wünscht sich der Benutzer vom Avatar?
• Wie hedonistisch wird die Interaktion mit dem Avatar empfunden?](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-41-320.jpg)
![Explorative Studie zu Sprachinteraktion und anthropomorphen Interfaceagenten im
Rahmen des mUltimo-3D-Projektes am Heinrich-Hertz-Institut
42
• Wie verhalten sich die allgemeinen Vorstellungen über einen Avatar und die
Ansprache des vorgestellten Avatars zueinander?
• Wie verhalten sich die allgemeinen Vorstellungen über einen Avatar und die
empfundene hedonistische Qualität dieses speziellen Avatars zueinander?
• Lassen sich Unterschiede für den Avatar in Bezug auf Alter und Geschlecht
feststellen?
5.3.6 Theoriegeleitete Hypothesen zum Avatar
• Die erläuterten Studien zur Repräsentation eines Avatars zeigten, dass eine
menschenähnliche Gestalt vom Benutzer ein natürliches Kommunikations-
verhalten verstärkt. Es wird deshalb vermutet, dass der Grossteil der Versuchs-
personen den Avatar personifiziert ansprechen wird.
H1= G 1 (personifiziert ) > G 2 (unpersonifiziert)
H0= G 1 (personifiziert) = G 2 (unpersonifiziert)
Dabei wird speziell aus der Forschung von Sproull et al. [SPROULL96]
vermutet, dass mehr Frauen als Männer den Avatar personifiziert ansprechen,
da Frauen empfänglicher auf soziale Signale wie Gesichtsausdrücke reagieren.
• Die bisherigen Studien belegen ebenfalls, dass ein menschliches Erscheinungs-
bild und Verhalten des Avatars als sympathisch empfunden wird. Es wird
deshalb vermutet, dass positive Einschätzungen zur hedonistischen Qualität des
Avatars überwiegen.
H1= G 3 (hatten Spaß) > G 4 (hatten keinen Spaß)
H0= G 3 (hatten Spaß) = G 4 (hatten keinen Spaß)
Diesbezüglich wird speziell aus der Forschung von [SPROULL96] vermutet,
dass Männer eher Spaß mit dem Avatar haben als Frauen, da sie interessierter
an neuer Technik sind.](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-42-320.jpg)
![Explorative Studie zu Sprachinteraktion und anthropomorphen Interfaceagenten im
Rahmen des mUltimo-3D-Projektes am Heinrich-Hertz-Institut
43
5.3.7 Stichprobe des Logfileexperiments
Teilnehmer der Untersuchung waren 22 Männer und fünf Frauen. Das durchschnitt-
liche Alter war 27 (Minimum 13, Maximum 42 Jahre). Die durchschnittliche Com-
putererfahrung betrug 8,6 Jahre und die durchschnittliche Computernutzung 24 Stunden
pro Woche für Anwenderprogramme wie MS-Word, 3D-Programme, Datenbanken,
WWW, Spielen und Programmieren. Anwendungsprogramme und WWW standen beim
Ranking an erster Stelle. 50 Prozent der Versuchsteilnehmer hatte bereits Erfahrung mit
3D-Anwendungen, wobei die Erfahrung mit Spracherkennungssoftware gering war. 18
Personen hatten keine und eine Person wenig Erfahrung. Von den übrigen acht Versuchs-
teilnehmern werteten sechs ihre Erfahrung als schlecht und zwei als gut. Die meisten
Personen gaben an, durch Ausprobieren am besten zu lernen und vor allem aus Neugier
und Interesse an Wissenschaft und Technik, an dem Versuch teilzunehmen.
Als Kontrollvariablen dienten Subtests aus HAWIE [WECHSLER91] und LPS
[HORN62] zum räumlichen Vorstellungsvermögen und zum Arbeitsgedächtnis. Alle
Teilnehmer erzielten hier durchschnittliche Ergebnisse, ein Zusammenhang mit den
Leistungsdaten konnte nicht nachgewiesen werden.
Mit dem Zeiss Nahprüfgerät wurde sichergestellt, dass alle Versuchsteilnehmer über ein
gutes Stereosehen verfügen, was für die beanspruchte Arbeit mit dem stereoskopischen
Display vorauszusetzen ist.
In der Vorbefragung wurde ebenfalls erfragt, wie sich die Teilnehmer Kommunikation
mit dem Computer vorstellen. Dabei wurden Spracherkennung und Sprachausgabe am
häufigsten angekreuzt, wie aus Grafik 11 ersichtlich ist.](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-43-320.jpg)
![Explorative Studie zu Sprachinteraktion und anthropomorphen Interfaceagenten im
Rahmen des mUltimo-3D-Projektes am Heinrich-Hertz-Institut
44
0 5 10 15 20 25
herkömmlich (Maus / Tastatur)
Sprachausgabe
Spracherkennung
Assistent
Blickinteraktion
Pop up
Tamagochi
Emotions- / Motivationserkennung
Emotionsäußerung
Abbildung 11 - Wunsch Kommunikation mit Computer N=27
5.3.8 Versuchsdurchlauf des Logfileexperimemts
Vor der Einführung in das System wurden der Fragebogen zur Person und die Tests
zum stereoskopischen Sehen vorgelegt und unmittelbar ausgewertet. Außerdem wurden die
Tests zum räumlichen Vorstellungsvermögen und zum Arbeitsgedächtnis durchgeführt und
ausgewertet. Nach der Kalibrierung des Systems erfolgte eine Einführung in den CAD-
Raum mit einer Übungsaufgabe. Sie diente dazu, sich mit der Applikation vertraut zu
machen; dabei konnten auch Fragen an den Versuchsleiter gestellt werden, um mehr
Sicherheit im Umgang mit dem System zu erlangen. In der Übungsaufgabe zur Kon-
struktion modellierten die Probanden eine nur aus drei Grundobjekten bestehende Hantel,
um die Manipulationsmöglichkeiten auszuprobieren und zu üben. Diese Einführungsphase
dauerte ungefähr 45 Minuten. Für die folgenden drei Konstruktionsaufgaben (siehe
Abbildung 12) hatten die Versuchsteilnehmer jeweils maximal zehn Minuten Zeit, die zur
vollständigen Bearbeitung nicht ausreichten, um Deckeneffekte zu vermeiden. Im
Anschluss an jede Aufgabe sollte auf der SEA-Skala [EILERS86] die Höhe der
Beanspruchung durch die Aufgabe selbst eingeschätzt werden und am Ende des Versuches
wurde das semantische Differential zur Einschätzung der hedonistischen und
pragmatischen Qualität sowie der Attraktivität der Applikation vorgelegt
[HASSENZAHL00]. Des weiteren sollte der Aufgabenschwierigkeitsgrad der einzelnen
Aufgaben selbst eingeschätzt und in eine Rangreihe gebracht werden. In einer](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-44-320.jpg)


![Explorative Studie zu Sprachinteraktion und anthropomorphen Interfaceagenten im
Rahmen des mUltimo-3D-Projektes am Heinrich-Hertz-Institut
47
5.4 Auswertung
In diesem Teil der Arbeit wird genauer auf die Art der Untersuchungsmethoden, das
Datenniveau und die daraus folgenden Ergebnisse eingegangen. Weitere Auswertungen
der Daten mit den im Versuchsdurchlauf des Logfileexperimentes genannten
Messinstrumenten finden sich bei Seifert [SEIFERT02] und Baumgarten
[BAUMGARTEN02].
5.4.1 Die Untersuchungsmethoden und das Datenniveau
In der Untersuchung wurden quantitative und qualitative Daten genutzt, um aus ihnen
neue Ideen und Hypothesen explorativ abzuleiten. Das theoretische Vorverständnis auf
dem Gebiet der Multimodalität ist noch nicht soweit elaboriert und fokussiert, dass sich
viele operationale und statistische Hypothesen formulieren lassen, die einer Signifikanz-
prüfung unterzogen werden könnten. Es ging in der Untersuchung vorrangig darum, den
Umgang mit neuer Technik zu testen und darüber Daten zu sammeln und diese ent-
sprechend aufzubereiten. Auf die Problematiken der vorliegenden Daten wird in der
methodischen Kritik zur Untersuchung noch genauer eingegangen.
Das Simulationsexperiment wurde im eingeschränkten Stil der Wizard-of-Oz-
Experimente durchgeführt. Bei diesen Experimenten geht es darum, Funktionen noch nicht
fertig gestellter Systeme zu untersuchen. Simulation ist billiger und schneller als
Abänderung eines Prototypen, man hat unbeschränktere Möglichkeiten und erkannte
Probleme können leichter isoliert werden. Wizard-of-Oz-Eperimente simulieren ein
natürlichsprachliches System, indem sie einen Menschen zur Interpretation der
Kommandos der Versuchsteilnehmer benutzen. In einem typischen Experiment erteilt der
Versuchsteilnehmer ein Kommando auf einen Bildschirm, das an einem anderen Ort von
dem Wizard interpretiert und im Sinne eines realen Systems beantwortet wird. Im
Simulationsexperiment wurde den Versuchspersonen vermittelt, dass der Computer
beziehungsweise der Avatar auf Spracheingabe reagiere, was aber tatsächlich nicht der
Fall, sondern erst in der Weiterentwicklung vorgesehen war. Die Interaktion mit dem
System erfolgte daher einseitig.
Die aufgezeichneten Videodaten aus dem Simulationsexperiment wurden per Hand
ausgewertet, indem die Antworten der Versuchspersonen zunächst wörtlich nieder-
geschrieben wurden. Die Menge der Informationen wurde durch selbst aufgestellte](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-47-320.jpg)





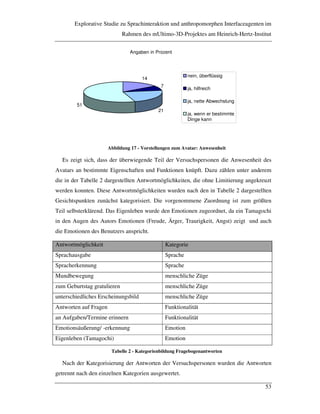






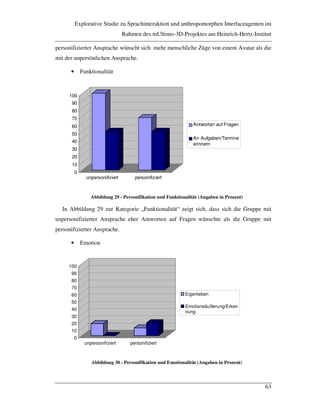








![Explorative Studie zu Sprachinteraktion und anthropomorphen Interfaceagenten im
Rahmen des mUltimo-3D-Projektes am Heinrich-Hertz-Institut
73
In der Benutzung von Sprache über die Zeit ist eine signifikante Abnahme der
Sprachinteraktion in der dritten Aufgabe zu verzeichnen. Das bestätigt die Hypothese, dass
die Interaktion mit Sprache über die Zeit abnimmt, weil die Versuchsteilnehmer müde
werden oder frustriert über Fehleingaben oder nicht erkannte Befehle sind. Letzteres kann
dazu führen, dass andere Modalitäten präferiert werden, um die Aufgaben zu erledigen, so
dass in manchen Fällen gar keine Aussage darüber möglich ist, ob der Proband vielleicht
gern weiter mit Spracheingabe gearbeitet hätte, wenn die Technik dies ermöglicht hätte.
Die erste Hypothese, dass Sprache die herausragende Modalität gegenüber Maus und
Blick ist, hat sich nicht bestätigt. Im Vergleich zwischen den einzelnen Modalitäten liegt
die Sprachinteraktion im Mittelfeld zwischen Blick (am wenigsten) und Maus (am
häufigsten). Das verwundert nicht, insofern, als die Besonderheiten der Modalität Blick
ihre Funktionalität per se einschränkten und sie schon deshalb seltener benutzbar war.
Außerdem musste sie durch Maus oder Sprache unterstützt werden. Dass die
Mausinteraktion der Sprachinteraktion überlegen ist, liegt wohl in der starken Gewöhnung
begründet. Das scheint durch die Shortcutfunktion (ersparte den Griff zur Maus
beziehungsweise zwei Mausklicks) und die Natürlichkeit der Sprache als Modalität nicht
aufgewogen zu werden. Hinzu kommt, dass die Modalität nicht so natürlich war, da das
System nur einzelne Wörter und Synonyme erkannte und deshalb die Interaktion nicht im
natürlichen Fluss erfolgen konnte.
Es konnte kein Zusammenhang zwischen der Sprachinteraktionshäufigkeit mit der
Leistung in den Aufgaben festgestellt werden. Das bedeutet, dass die durch die Shortcut-
Funktion eingesparte Zeit und die Modalität Sprache allein nicht wie in der Hypothese
erwartet, zu einer Erhöhung der Leistung führte. Dagegen gab es einen Effekt, wenn alle
Modalitäten zusammen benutzt wurden. [SEIFERT02]
Die Interviewergebnisse zeigen, dass der Grossteil der Nutzer die Sprachinteraktion als
hilfreich empfand, was die anderen Ergebnisse stützt. Etwas weniger, aber immer noch die
Mehrheit, fand die Qualität der Spracherkennung gut, was bedeuten kann, dass sie sich
durch gelegentliche Fehleingaben nicht von der Nutzung von Sprache haben abhalten
lassen. Die Reaktionszeit zwischen Erkennung und Signal wurde von der Mehrheit als zu
langsam empfunden. Wenn dies schneller gegangen wäre, hätten vielleicht noch mehr
Probanden öfter die Sprache benutzt. Verzögerungen zwischen Signalsendung und
Antwort durch den Empfänger sind auch in der Mensch-zu-Mensch-Kommunikation](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-73-320.jpg)

![Explorative Studie zu Sprachinteraktion und anthropomorphen Interfaceagenten im
Rahmen des mUltimo-3D-Projektes am Heinrich-Hertz-Institut
75
dem embodied Agent lag das wohl zum einen an der Art der Darstellung, aber auch an der
Neuheit der Applikation. Genauere Aspekte wurden hierbei nicht erfragt.
Kaum zu interpretieren sind die Gruppenunterschiede im Spaßfaktor in Bezug auf die
angekreuzten Vorstellungen zum Avatar, da hier aus der in Abschnitt 5.5.2.2 diskutierten
methodischen Problematik heraus keine signifikanten Ergebnisse vorliegen. Deshalb sind
dies hier lediglich Tendenzen, die einer weiteren Überprüfung in einer größeren Stichprobe
unterzogen werden müssten.
Der unterschiedliche Spaßfaktor berührte offensichtlich nicht den Wunsch nach
Spracherkennung und -ausgabe. Der war sogar bei weniger oder keinem Spaß nach
Sprachausgabe höher, vielleicht, um eine Rückmeldung über die Spracheingabe zu
bekommen. Es scheint keinen nennenswerten Unterschied zwischen den beiden Gruppen
in Bezug auf den Wunsch nach menschlichen Zügen zu geben. Die scheinen für die
hedonistische Qualität nicht so entscheidend zu sein. Dasselbe gilt für die Funktionalität,
da diese per se ja wenig mit dem Spaßfaktor zu tun hat. Dagegen scheint eine größere
Anzahl von Versuchspersonen, die Spaß an der Kommunikation mit dem Avatar hatten,
Emotionserkennung und -äußerung von ihrem Avatar zu wünschen, als die Personen, die
wenig oder keinen Spaß hatten. Dadurch wird die Kommunikation vielleicht noch
lebendiger und anregender empfunden. Die Probanden, die keinen oder weniger Spaß an
der Kommunikation mit dem Avatar hatten, scheinen auch kein weiteres Interesse an
lebendigerer Darstellung zu haben.
Es haben signifikant mehr Versuchspersonen den Avatar personifiziert als unper-
sonifiziert angesprochen. Damit hat sich Hypothese bestätigt, dass die personifizierte Form
der Ansprache überwiegt. Das mag an der anthropomorphen Form des Agenten liegen. Sie
sahen ihn dadurch offensichtlich mehr als menschenähnlichen Interaktionspartner.
Wirklich zu interpretieren wäre dieser Unterschied aber eher noch im Vergleich mit einer
anderen Darstellungsform. Bente und Krämer [BENTE02] schlagen zwar vor, wie in
unserem Experiment geschehen, nur das Aussehen und die Darstellung des Avatars als
unabhängige Variable zu betrachten, aber man könnte den Gruppenunterschied in der
Ansprache mit der Ansprache einer weniger anthropomorphen Applikation validieren.
Die Interpretation der Gruppenunterschiede zwischen personifizierter und unper-
sonifizierter Ansprache in Bezug auf die angekreuzten Vorstellungen zum Avatar muss
noch vorsichtiger zu verstehen sein als die zum Spaßfaktor, da hier durch die kleine](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-75-320.jpg)


![Explorative Studie zu Sprachinteraktion und anthropomorphen Interfaceagenten im
Rahmen des mUltimo-3D-Projektes am Heinrich-Hertz-Institut
78
beklagen waren. Aber auch wenn die Daten vollständig vorgelegen hätten, müsste eine
noch größere Stichprobe untersucht werden, um die Effektstärke zu erhöhen.
Der Begriff „Spaß“ zur Operationalisierung der hedonistischen Qualität des Avatars ist
vermutlich zu indifferent. Außerdem wurde nach dem Spaß an der Kommunikation mit
dem Avatar gefragt. Die Interaktion mit dem System erfolgte aber einseitig, was einigen
Versuchspersonen nicht verborgen blieb und damit auch Auswirkungen auf die Be-
urteilung der hedonistischen Qualität der Applikation hatte. Des Weiteren ist die Vorgabe
der Antwortmöglichkeiten, Einteilung in die Antwort-Kategorien, ebenso wie die Zu-
ordnung der Teilnehmer in die Anspracheformen subjektiv. Hier erfolgte kein
Expertenrating, sondern eine Einschätzung des Autors.
Die Fragestellung und die Ergebnisse der Untersuchung zum Avatar sind demzufolge
nur sehr explorativ und tendenziell zu sehen. In weiterer Forschung könnten die tendenziell
gezeigten Ergebnisse mit einem richtigen Versuchsdesign und einer sehr viel höheren
Anzahl von Versuchspersonen statistisch bedeutsam werden.
Methodische Kritik am Logfileexperiment
Im Logfileexperiment gab es weniger methodische Probleme, da hier ein
Versuchsdesign existierte und der Versuch sehr viel länger dauerte, was die Datenmenge
und deren Aussagekraft steigerte. Allerdings enthalten Logfiledaten keine Information über
das individuelle Benutzerprofil in Bezug auf zum Beispiel Müdigkeitserscheinungen,
Frustrationsschwelle bei technischen Fehlleistungen und Erfahrung mit beziehungsweise
Ängsten vor Umgang mit einem neuen System.
Durch die lange Zeit, die die Versuchspersonen vor dem System verbrachten (von drei
bis zu fünf Stunden), traten Konzentrations- und Motivationsverluste auf, so dass deshalb
vielleicht weniger mit Sprache interagiert wurde.
Zum anderen könnte durch die Zeitvorgabe eine Art Stresssituation entstanden sein, die
dazu geführt hat, dass die Probanden möglichst schnell sein wollten. Diese Stresssituation
wurde durch die Neuartigkeit der Systeme und die Anwesenheit des Versuchsleiters
[BORTZ95] gefördert. Es ist anzunehmen, dass dadurch zusätzlich weniger Sprache
benutzt wurde, um sich nicht zu blamieren.
Das führt eventuell zu falschen Interpretationen in der Auswertung. Logfiles enthalten
keine Wahrheiten, sondern nur Interpretationshinweise.](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-78-320.jpg)
![Explorative Studie zu Sprachinteraktion und anthropomorphen Interfaceagenten im
Rahmen des mUltimo-3D-Projektes am Heinrich-Hertz-Institut
79
Ein weiteres Problem war die Restriktion der Spracherkennung. Es konnten auch nur
einzelne Begriffe und die am besten ohne Kontextinformation vom System erkannt
werden, was die Teilnehmer in Kommandosprache verfallen ließ. Eine bessere Sprach-
erkennung in fließenden Sätzen wäre deshalb für die nächste Untersuchung wünschens-
wert.
Methodische Besonderheiten für Fragebogen- und Interviewdaten
Für Fragebogendaten gibt es die bekannten Probleme der Verständlichkeit der Items, da
keine mündlichen Erläuterungen erfolgten, der sozialen Erwünschtheit in den Antworten,
der Motivation der Probanden und der Besonderheiten in der Auswertung und
Interpretation.
Beim mündlichen halbstrukturierten Interview in der Nachbefragung gilt zu beachten,
dass zwischen den beiden Personen eine Beziehung entsteht, die sich auf die Beantwortung
der Fragen auswirken könnte. Freie Äußerungen sind schwer quantifizierbar und vor-
gegebene Antwortmöglichkeiten schränken den Informationsgehalt ein.
5.5.3 Integration der Ergebnisse in die Forschung und Ableitung
von Fragestellungen für die Gestaltung einer intelligenten
Benutzungsschnittstelle mit Sprache und Agenten
Die Ergebnisse aus der vorliegenden Untersuchung decken sich zum Teil mit den bisher
noch nicht besonders gut evaluierten Erkenntnissen bezüglich dessen, was Benutzer von
einem Agenten erwarten und wie sie sich in der Interaktion mit ihm verhalten. Die
menschliche Darstellung durch die 3D-animierte Gestalt, Mimik und Bewegung führte
offensichtlich vermehrt zu personifizierter Ansprache und damit zu natürlicher Kom-
munikation wie mit einem menschlichen Gegenüber. Das passt zu den Ergebnissen von
Koda und Maes, die fanden, dass ein menschliches Gesicht als Partner im Spiel versucht
wurde zu deuten und je menschlicher, desto eher wurden ihm menschliche Attribute wie
Intelligenz zugeschrieben. Bei Takeuchi und Naito [TAKEUCHI95] erzeugte ein Gesicht
mehr Augenkontakt und Aufmerksamkeit als eine andere Darstellungsform. Bei Sproull et
al [SPROULL96] zeigten sich weitere Attribute der Mensch-zu-Mensch-Kommunikation
bezüglich Bewertung von Persönlichkeitsmerkmalen und eigener Darstellung in Inter-
aktion mit dem Gesichtsinterface im Gegensatz zum Textinterface. Es lassen sich aus der](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-79-320.jpg)
![Explorative Studie zu Sprachinteraktion und anthropomorphen Interfaceagenten im
Rahmen des mUltimo-3D-Projektes am Heinrich-Hertz-Institut
80
vorliegenden Untersuchung nur Aussagen über das Verhalten der Probanden im Vergleich
mit Untersuchungsergebnissen zur äußeren Erscheinung eines Agenten treffen, da der
Agent aus dem Simulationsexperiment nur eingebildet in Interaktion mit dem Nutzer treten
konnte. Eine reale multimodale Interaktion per Sprache, Blick oder Gestik war nicht
möglich. Es bliebe in einem Folgeexperiment zu zeigen, welche Effekte diese Form der
Interaktion und ob der Benutzer daraus Vorteile hat. Aus den Fragebogendaten ergab sich
tendenziell, dass Benutzer die Anwesenheit des Agenten hauptsächlich an bestimmte
Funktionen wie Antworten auf Fragen oder an Aufgaben / Termine erinnern koppeln. Das
deckt sich mit Erkenntnissen von van Mulken et al [MULKEN98], die zeigten, dass zwar
die Präsentation von Lehrmaterial mit Hilfe eines animierten Agenten gegenüber einer
anderen Applikation bevorzugt wurde, aber dies wurde von vielen auch von der Art des
Lehrmaterials abhängig gemacht. Die Funktionalität wird also vom Benutzer nicht aus den
Augen verloren. Spracherkennung und Sprachausgabe wurden in der vorliegenden
Untersuchung besonders für die Interaktion mit dem Avatar gewünscht. Das spricht dafür,
in weiteren Untersuchungen Spracherkennung und Sprachausgabe zu implementieren und
zu optimieren.
Die Modalität Sprache wurde im Logfileexperiment näher untersucht. Die
Untersuchungsergebnisse haben gezeigt, dass Sprache die am zweithäufigsten benutzte
Modalität war und möglicherweise auf Grund von Frustrationen durch Fehleingaben, der
Restriktion auf Kommandos und der Verzögerung zwischen Erkennung und Feedback über
die Zeit weniger benutzt wurde. Bei einer verbesserten Erkennungsleistung der
Spracheingabe mit den in Kapitel 4.2.7 beschriebenen Methoden und höherer
Verarbeitungsgeschwindigkeit könnte man prüfen, ob die bisher als hilfreich eingeschätzte
akustische Rückmeldung der Erkennung einer Spracheingabe noch notwendig ist und sich
die Benutzung von Sprache erhöht. [SEIFERT02]
Für den Versuch fällt es schwer, eine differenzierte Aussage darüber zu treffen, warum
Sprache überhaupt als Modalität gewählt wurde. Vielleicht war es nur die Shortcut –
Funktion, die die Probanden dazu brachte, Sprache zu benutzen und nicht die
„Natürlichkeit“ der Modalität. Vielleicht war es den Probanden aber auch eher angenehm,
ein eingegrenztes Vokabular zur Verfügung zu haben und dem System Befehle zu erteilen
anstatt im Fluss mit ihm zu reden. Das würde die Annahme von Walker und Cohen](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-80-320.jpg)
![Explorative Studie zu Sprachinteraktion und anthropomorphen Interfaceagenten im
Rahmen des mUltimo-3D-Projektes am Heinrich-Hertz-Institut
81
[COHEN89] stützen, dass restringierte Sprache in multimodalen Interfaces je nach
Anwendungsform durchaus nützlicher sein kann als natürliche Sprache.
Da sich durch Integration verschiedener Modalitäten die Leistung und die Bewertung
des Systems durch den Benutzer generell verbessert, bleibt die Frage, welchen Platz die
Sprachinteraktion dabei einnimmt und wie man sie am „natürlichsten“ mit den anderen
Modalitäten kombinieren kann. Darauf wird im folgenden Ausblick noch näher
eingegangen.
5.5.4 Ausblick
Sicherlich werden komfortable Schnittstellen der Zukunft stark unterstützt einerseits
durch intuitive Eingabehilfsmittel, die den Gebrauch der natürlichen Ausdrucksformen des
Menschen (direkter Zugriff mit den Händen, Sprache, Gestik, Mimik) erlauben, und
andererseits durch intelligente, zum Teil auch personifizierte Helfer-Agenten, die über
Wissen der Anwendung verfügen und mit Hilfe von Expertensystemtechniken assistie-
rende Funktionen übernehmen.
Der noch in Entwicklungsstadium befindliche SMARTKOM demonstriert die Mensch-
Maschine-Schnittstelle der Zukunft. Das System schafft eine dialogische Mensch-Technik-
Interaktion durch koordinierte Analyse und Generierung multipler Modalitäten. Es wertet
sowohl Sprach-, als auch alphanumerische oder Handschrifteneingabe aus, analysiert
Gesten und den Gesichtsausdruck des Benutzers, charakterisiert den emotionalen Zustand
und kann beispielsweise auch Handabdrücke für die biometrische Identifikation
analysieren.
Es gibt aber bislang kaum Lösungsvorschläge dafür, wie die multimodalen Äußerungen
eines Systemnutzers - als zeitlich gesteuerte Perzepte auf getrennten Kanälen registriert - in
ihrem zeitlichen Zusammenhang zu rekonstruieren sind.
Besonders interessant für die weitere Forschung ist eine Integration der Modalitäten
Sprache und Gestik, die in natürlicher Kommunikation oft zusammen auftreten. Ver-
schiedene Befunde aus der psychologischen und phonetischen Forschung haben Hinweise
auf eine rhythmische Organisation des menschlichen Kommunikationsverhaltens erbracht,
und das sowohl im Hinblick auf die Produktion als auch die Rezeption von Äußerungen.
Wenn eine Person spricht, bewegen sich oft viele Teile des Körpers zur gleichen Zeit:
Arme, Finger, der Kopf etc. als so genannte koverbale Gesten. Die Informationen daraus](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-81-320.jpg)
![Explorative Studie zu Sprachinteraktion und anthropomorphen Interfaceagenten im
Rahmen des mUltimo-3D-Projektes am Heinrich-Hertz-Institut
82
werden bisher als Sprach - und Gestenperzepte auf getrennten Kanälen technisch registriert
und müssen für die Steuerung von Anwendungen zusammengeführt und interpretiert
werden. Eine mögliche Fortsetzung betrifft die Frage, wie sich ein rhythmisch gesteuertes
Eingabesystem automatisch auf den individuellen kommunikativen Rhythmus unter-
schiedlicher Benutzer einstimmen lässt. Es ist leicht erkennbar, dass eine derartige Ein-
gabeform für Anwendungssysteme, wie sie heute schon im virtuellen Entwurf eingesetzt
werden, erheblichen Komfortgewinn erbringen könnte. [WACHS98]
Der aktuelle Forschungsstand bezüglich der Effekte von Agenetenrepräsentationen hat
Einfluss auf die weitere Vorgehensweise bei der Entwicklung von Embodied
Conversational Agents. Zur Systematisierung des Forschungsfeldes schlagen Bente und
Krämer [BENTE02] vor, zentrale Variable bei der Gestaltung und Evaluation von
anthropomorphen Interfaceagenten (AIA) zu benennen. Sie unterscheiden, am klassischen
experimentalpsychologischen Vorgehen orientiert, zwischen unabhängigen Variablen
(deren Effekte festgestellt werden sollen) wie Verhalten und Aussehen von AIA,
abhängigen Variablen (auf die sich potentielle Effekte auswirken) wie Einstellung und
Verhalten des Nutzers und moderierenden Variablen (die möglicherweise Einfluss nehmen
auf die Auswirkung der unabhängigen Variable auf die abhängige) wie Situations- und
Nutzermerkmale. „Erst wenn in diesen Bereichen der Evaluationsforschung genauere
Erkenntnisse vorliegen, kann vorhergesagt werden, welche Arten von AIAs unter welchen
Bedingungen auf welche Personengruppen welche Effekte verursachen. Ist ein solches
Wissen verfügbar, so kann insbesondere auch die Realisation sich daran orientieren – da
Wissen über spezifische Wirkungen zur Verfügung gestellt werden kann, das bei der
Implementierung berücksichtigt werden kann.“ [BENTE02].
Die Entwicklung und Erforschung von multimodalen Schnittstellen wie
Sprachinteraktion und AIA scheinen noch im Anfangsstadium zu sein, wobei die
Sprachinteraktion schon besser erforscht und implementiert ist.
Die KI-Forschung ist gefordert, erweiterte Techniken zu entwickeln, die auch das
zeitliche Kommunikationsverhalten des Menschen und die Erwartungen eines Nutzers an
einen Agenten besser berücksichtigen und damit zur Gestaltung von adaptiven
Dialogsystemen beziehungsweise intelligenten Benutzungsschnittstellen beitragen.
Auf die weiteren Fortschritte darf man gespannt sein.](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-82-320.jpg)
![Literaturverzeichnis
83
6 Literaturverzeichnis
[ALLEN80]
Allen, J. F., Perrault, C.R. (1980); Analyzing Intention in Utterances
in: Artificial Intelligence 15
[ATKINSON68]
Atkinson, R.C., Shiffrin, R.M. (1968); Human memory: A proposed system and its control
[BAUMGARTEN02]
Baumgarten, T. (2002); Ableitung eines noninvasiven Indikators von mental workload für
die Implementierung in einem adaptiven multimodalen System; Diplomarbeit; Technische
Universität; Berlin
[BENTE00]
Bente, G., Krämer, N.C. (2000); Psychologische Aspekte bei der Implementierung und
Evaluation von nonverbal agierenden Interface-Agenten
in: Proceedings Mensch und Computer 2001; S. 275-285
[BESNARD]
Besnard, P., Hanks, S. (Hrsg.); Proceedings of the Eleventh Conference on Uncertainty in
Artificial Intelligence; Morgan Kaufmann; San Francisco; S. 296-305
[BLOMBERG94]
Blomberg, M. (1994); A common phone model representation forspeech recognition and
synthesis
in: Proceedings of ICSLP94; Yokohama, 1994; S. 1875-1878
[BORTZ95]
Bortz, J., Döring, N. (1995); Forschungmethoden und Evaluation für Sozialwissenschaftler
(2. Aufl.); Berlin, Heidelberg; Springer
[BRIEST02]
Briest, S. (2002); Vergleich zweier gestischer Dialogsysteme in der Mensch-Maschine-
Interaktion; Diplomarbeit; Technische Universität; Berlin
[BROOKS02]
Brooks, R. (2002); Menschmaschinen; Campus Verlag; Frankfurt Main
[CASSELL98]
Cassell, J., Thórisson, K.R. (1998); The power of a nod and a glance: Envelope vs.
emotional feedback in animated conversational agents
in: Applied Artificial Intelligence
[CASSELL99]
Cassell, J., Vilhjálmsson, H. (1999); Fully embodied conversational agents: Making
communicative behaviors autonomous
in: Autonomous Agents and Multi-Agent Systems, 2; S. 45-64.](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-83-320.jpg)
![Literaturverzeichnis
84
[CHARNIAK91]
Charniak, E. (1991); Bayesian networks without tears; AI Magazine, 12(4); S. 50-63
[COHEN89]
Cohen, P.R., Sullivan, J.W., Dalrymple, M., Gargan, R.A., Moran, D.B., Schlossberg, J.L.,
Pereira, F.C.N., Tyler, S.W. (1989); Synergistic Use of Direct Manipulation and Natural
Language
in: Proceedings of CHI’89; New York; Association for Computing Machinery; S. 227-232
[DAGUM92]
Dagum, P., Galper, A., Horvitz, E. (1992); Dynamic network models for forecasting
in: Proceedings of the Eighth Conference on Uncertainty in Artificial Intelligence; Morgan
Kaufmann; San Meteo S. 41-48
[DEHN00]
Dehn, D., van Mulken, S. (2000); The impact of animated interface agents: a review of
empirical research
in: International Journal of Human-Computer Studies, Vol. 52; 2000; S. 1-22
[DESHMUKH02]
Deshmukh, O., Espy-Wilson, C., Juneja, A. (2002); Acoustic-phonetic Speech Parameters
for Speaker-independent Speech Recognition
in: International Conference on Acoustics, Speech and Signal Processing; ICASSP 2002;
Orlando; Florida
[DIETZ99]
Dietz, R.B., Lang, A. (1999); Affective agents: Effects of agent affect on arousal, attention,
liking and learning
in: Proceedings of international cognitive '99. San Francisco, CA
[DROPPO02]
Droppo, J., Acero, A., Deng, L. (2002); A Nonlinear Observation Model for Removing
Noise from Corrupted Speech Log Mel-Spectral Energies
in: Proceedings International Conference on Spoken Language Processing; Denver;
Colorado; Sep 2002
[ECONO01]
The Economist (2001); Son of paperclip; Print edition , 22. März 2001
[EILERS86]
Eilers, K., Nachreiner, F., Hänecke, K. (1986); Entwicklung und Überprüfung einer Skala
zur Erfassung subjektiv erlebter Anstrengung
in: Zeitschrift für Arbeitswissenschaft, 4(40); S. 215-224
[EMBASSI01]
Elektronische Multimediale Bedien- und Service-Assistenz, White Draft
http://www.embassi.de](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-84-320.jpg)
![Literaturverzeichnis
85
[ENGE00]
Enge, M., Massow, S. (2000); Needs for assistance of visually and physically disabled and
nondisabled persons when using money-/cash dispensers
in: (Hrsg.): de Waard, D.; Weikert, C.; Hoonhout, J.; Remekers, J.; Human-System
Interaction: Education, Research and Application in the 21st Century; Maastricht, NL,
Shaker Verlage; S. 263 – 266
[EYSENCK94]
Eysenck, M.W. (Hrsg.) (1994); The blackwell dictionary of cognitive psychology; Basil
Blackwell Ltd.; Oxford
[FELLBAUM91]
Fellbaum, K. (1991); Elektronische Sprachverarbeitung: Verfahren, Anwendungen,
Wirtschaftlichkeit; München
[FISCHER99]
Fischer, K. (1999); Repeats, Reformulations and Emotional Speech: Evidence for the
Design of Human-Computer Speech Interfaces
in: Proceedings of HCI, Volume 1; S. 560-565
[FOLDOC]
Free On-Line Dictionary of Computing; http://foldoc.doc.ic.ac.uk; Stichwort “Avatar”
[GHARAMANI98]
Ghahramani, Z. (1998); Learning Dynamic Bayesian Networks
in: Giles, C.L., Gori, M. (Hrsg.); Adaptive Processing of Sequences and Data Structures;
Lecture Notes in Artificial Intelligence; Springer-Verlag; Berlin; S. 168-197
ftp://ftp.cs.toronto.edu/pub/zoubin/vietri.ps.gz
[GREENBERG98]
Greenberg, S. (1998); Recognition in a New Key - Towards a Science of Spoken Language
in: ICASSP98, International Conference on Acoustics, Speech and Signal Processing;
Seattle; 1998
[HASSENZAHL00]
Hassenzahl, M., Platz, A., Burmester, M., Lehner, K. (2000); Hedonic and ergonomic
quality aspects determine a software's appeal
in: CHI 2000; S. 201-208
[HEDICKE02]
Hedicke, V. (2002); Multimodalität in Mensch-Maschine-Schnittstellen
in: Timpe, K.P., Jürgensohn, T. & Kolrep, H. (Hrsg.); Mensch-Maschine-Systemtecnik,
Konzepte, Modellierung, Gestaltung, Evaluation; Düsseldorf: Symposion; S. 205-233
[HOFB00]
Hofbauer, W.; Avatare
In: http://www.hfg-offenbach.de/div/daten7/gesiebtes/avatare/index.php
[HORN62]
Horn, W. (1962); Leistungsprüfsystem – (LPS); Göttingen; Hogrefe](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-85-320.jpg)
![Literaturverzeichnis
86
[HORVITZ95]
Horvitz, E., Barry, M. (1995); Display of information for time-critical decision making;
[HORVITZ98]
Horvitz, E., Breese, J., Heckerman, D., Hovel, D.; Rommelse, K. (1998); The lumiere
project: Bayesian user modeling for inferring the goals and needs of software users
in: Proceedings of the fourteenth conference on uncertainty in artificial intelligence;
Wisconsin; S. 256-265
[HORVITZ01]
Horvitz, E., Paek, T. (2001); Harnessing Models of Users' Goals to Mediate Clarification
Dialog in Spoken Language Systems
in: Proceedings of the Eighth Conference on User Modeling, Sonthofen, Germany, July
2001
[JAMESON95]
Jameson, A., Schäfer, R., Simons, J., Weis, T. (1995); Adaptive provision of evaluation-
oriented information: Tasks and techniques
in: Mellish, C. S. (Hrsg.), Proceedings of the Fourteenth International Joint Conference on
Artificial Intelligence; Morgan Kaufmann; San Meteo; S. 1886-1893
[KARAT99]
Karat, C.M., Halverson, C., Horn, D., Karat, J. (1999); Patterns of entry and correction in
large vocabulary continuous speech recognition systems
in: CHI 99 Conference Proceedings; S. 568-575
[KING96]
King, W.J., Ohya, J. (1996); The Representation of Agents: Anthropomorphism, Agency,
and Intelligence
in: Proceedings of the ACM Conference on Human Factors in Computing Systems (CHI),
1996, S. 289-290
[KOBSA90]
Kobsa, A. (1990); User Modeling in Dialog Systems: Potentials and Hazards
[KODA96]
Koda, T., Pattie, M. (1996); Agents with faces: The effect of personification
in: 5th IEEE International Workshop on Robot and Human Communication; Tsukuba;
Japan; November 1996
[BROCKHAUS]
Brockhaus online; www.xipolis.net
[LIU99]
Pastoor, S., Liu, J., Renault, S. (1999); An experimental multimedia system allowing 3D
visualization and eye-controlled interaction without user-worn devices
in: IEEE Transactions in Multimedia, 1(1).](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-86-320.jpg)
![Literaturverzeichnis
87
[MOON96]
Moon, Y., Nass, C.I. (1996); Adaptive agents and personality change: Complementarity
versus similarity as forms of adaptation
in: Bilger, R., Guest, S., Tauber, M.J. (Hrsg.); Human factors in computing systems:
Chi'96 electronic conference proceedings
[MSRSCG]
Microsoft Research, Social Computing Group; http://research.microsoft.com/vwg/
[MULKEN98]
van Mulken, S., André, E., Müller, J. (1998): The Persona Effect: How Substantial Is It?
in: Proceedings of the Human Computer Interaction Conference; Springer; Berlin; 1998; S.
53-66
[OVIATT89]
Oviatt, S.L. (1989); The CHAM model of hyperarticulate adaptation during human-
computer error resolution
in: Proceedings of the International Conference on Spoken Language Processing; Sydney;
Australia; 1998
[OVIATT99]
Oviatt, S.L. (1999); Ten Myths of Multimodal Interaction
in: Communications of the ACM, 42(11); S. 74-81.
[PICONE90]
Picone, J. (1990); Continuous Speech Recognition Using Hidden Markov Models
in: IEEE ASSP Magazine 7/90
[RABINER95]
Rabiner, R.R. (1995); Voice communication betweeen humans and machines - An
introduction.
in: Proceedings of the National Academy of Sciences of the United States of America, Bd.
92; Academy, Colloquium Paper; Washington D.C.; S. 9911-9913
[REEVES96]
Reeves, B., Nass, C. (1996); The media equation: How people treat computers, television
and new media like real people and places
in: CSLI publications & Cambridge university press; 1996
[RICH79]
Rich, E. (1979); User modeling via stereotypes
in: Cognitive Science, 3; S. 329-354
[RICH89]
Rich, E. (1989): Stereotypes and User Modeling
in: A. Kobsa and W. Wahlster, eds.: User Models in Dialog Systems. Heidelberg; Springer](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-87-320.jpg)
![Literaturverzeichnis
88
[SCHÄFER96]
Schäfer, R., Weyrath, T. (1996); Einschätzung von verfügbarer Arbeitsgedächtniskapazität
mit temporalen Bayesschen Netzen
in: Lindner, H.-G. (Hrsg.); 4. GI-Workshop: Adaptivität und Benutzermodellierung in
interaktiven Systemen: Workshop-Beiträge; VEW AG; Dortmund; S. 5.1-5.9
[SCHULZ00]
Schulz von Thun, F. (2000); Miteinander reden. Störungen und Klärungen 1. Allgemeine
Psychologie der Kommunikation; Reinbeck bei Hamburg; Rowohlt Taschenbuch Verlag
Gmbh (Original erschienen: 1981)
[SEIFERT02]
Seifert, K. (2002); Evaluation multimodaler Computer-Systeme in frühen
Entwicklungsphasen; Dissertation; Technische Universität; Berlin
[SHIFFRIN94]
Shiffrin, R.M., Nosofsky, R.M. (1994); Seven plus or minus two: A commentary on
capacity limitations
in: Psychological Review, 101; S. 357-361
[SOLTAU98]
Soltau, H., Waibel A. (1998); On the influence of hyperarticulated speech on the
recogniton performance
in: Proceedings of the International Conference on Spoken Language Processing; Sydney;
Australia; 1998
[SOLTAU00]
Soltau, H., Waibel, A. (2000); Specialized Acoustic Models for Hyperarticulated Speech
in: Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal
Processing; Istanbul; Jun 2000
[SPROULL96]
Sproull, L., Subramani, M., Kiesler, S., Walker, J.H., Waters, K. (1996); When the
interface is a face
in: Human-Computer Interaction, 11, S. 97-124
[SUSEN99]
Susen, A.; Spracherkennung. Kosten, Nutzen, Einsatzmöglichkeiten; VDE
[TAKEUCHI95]
Takeuchi, A., Naito, T.; Situated facial displays: Towards social interaction
in: Proceedings of CHI-95; 1995
[TENNANT83]
Tennant, H.R., Ross, K.M., Thompson, C.W. (1983); Usable natural language interfaces
through menu-based natural language understanding
in: Proceedings of CHI '83: Human Factors in Computing Systems](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-88-320.jpg)
![Literaturverzeichnis
89
[TUR02]
Tur, G., Wright, J., Gorin, A., Riccardi, G., Hakkani-Tür, D. (2002); Improving Spoken
Language Understanding Using Word Confusion Networks
in: Proceedings of International Con-ference on Spoken Language Processing (ICSLP);
2002
[TURING50]
Turing, A. (1650); Computing Machinery and Intelligence
in: Mind, Vol 59, No. 236; S. 433-460
[VARY98]
Vary P., Heute, U. (1998); Hess, W.; Digitale Sprachsignalverarbeitung; Stuttgart;
Teubner; 1998
[WACHS98]
Wachsmuth, I. (1998); Experten- und Agentensystemtechniken fürintuitivere
Benutzungsschnittstellen
in: Mester, J., Perl, J. (Hrsg.) (1998); Informatik im Sport; Köln: Sport und Buch Strauss;
1998; S. 181-191
[WALKER89]
Walker, M., Whittaker, S. (1989); When Natural Language is Better than Menus: A Field
Study; Technical Report, Hewlett Packard Laboratories; Bristol; England
[WECHSLER91]
Wechsler, D. (1991); Hamburg-Wechsler-Intelligenztest für Erwachsene – (HAWIE-R);
Bern, Stuttgart, Toronto; Huber
[WEIZENBAUM66]
Weizenbaum, J. (1966); Eliza: A Computer Program for the Study of Natural Language
Communication between Man and Machine
in: Communications of the ACM, Col 9, No. 1; 1966; S. 36-45
[XUEDONG]
Huang, X. et al; Speech-enabled Agents; http://research.microsoft.com/srg/slu.aspx
[YOON]
Yoon, S., Kim, J.; Evaluation of ASR Sensors;
http://imis.ncat.edu/Evaluation%20of%20ASR%20Sensors.htm
[ZWEIG99]
Zweig, G., Russel, S. (1999); Probabilistic Modeling with Bayesian Networks for
Automatic Speech Recognition
in: International Conference on Speech and Language Processing; 1999](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-89-320.jpg)






![Anhang
96
Chi-Quadrat-Tests
1,080b
1 ,299
,504 1 ,478
1,087 1 ,297
,342 ,239
1,051 1 ,305
38
Chi-Quadrat nach Pearson
Kontinuitätskorrektur a
Likelihood-Quotient
Exakter Test nach Fisher
Zusammenhang
linear-mit-linear
Anzahl der gültigen Fälle
Wert df
Asymptotische
Signifikanz
(2-seitig)
Exakte
Signifikanz
(2-seitig)
Exakte
Signifikanz
(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
0 Zellen (,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeit ist 7,58.b.
Tabelle 41 - Sprachausgabe und Spaß am
Avatar
Ränge
20 19,65 393,00
18 19,33 348,00
38
20 18,00 360,00
18 21,17 381,00
38
spass<=2 (FILTER)
hatten Spass
hatten keinen Spass
Gesamt
hatten Spass
hatten keinen Spass
Gesamt
Spracherkennung
Sprachausgabe
N Mittlerer Rang Rangsumme
Statistik für Testb
177,000 150,000
348,000 360,000
-,139 -1,025
,890 ,305
,942
a
,393
a
Mann-Whitney-U
Wilcoxon-W
Z
Asymptotische
Signifikanz (2-seitig)
Exakte Signifikanz
[2*(1-seitig Sig.)]
Spracherkennung Sprachausgabe
Nicht für Bindungen korrigiert.a.
Gruppenvariable: spass<=2 (FILTER)b.
Tabelle 42 - Sprache und Spaß im Mann-
Whitney-U-Test
Mundbewegung * spass<=2 (FILTER) Kreuztabelle
Anzahl
4 2 6
16 16 32
20 18 38
Mundbewegung
nichts angekreuzt
Mundbewegung
Gesamt
hatten Spass
hatten
keinen Spass
spass<=2 (FILTER)
Gesamt
Chi-Quadrat-Tests
,563b
1 ,453
,093 1 ,761
,574 1 ,449
,663 ,384
,548 1 ,459
38
Chi-Quadrat nach Pearson
Kontinuitätskorrektur a
Likelihood-Quotient
Exakter Test nach Fisher
Zusammenhang
linear-mit-linear
Anzahl der gültigen Fälle
Wert df
Asymptotische
Signifikanz
(2-seitig)
Exakte
Signifikanz
(2-seitig)
Exakte
Signifikanz
(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
2 Zellen (50,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeit ist 2,84.b.
Tabelle 43 - Mundbewegung und Spaß am
Avatar
Erscheinungsbild * spass<=2 (FILTER) Kreuztabelle
Anzahl
6 4 10
14 14 28
20 18 38
Erscheinungsbild
nichts angekreuzt
Erscheinungsbild
Gesamt
hatten Spass
hatten
keinen Spass
spass<=2 (FILTER)
Gesamt
Chi-Quadrat-Tests
,296b
1 ,587
,031 1 ,861
,297 1 ,586
,719 ,432
,288 1 ,592
38
Chi-Quadrat nach Pearson
Kontinuitätskorrektur a
Likelihood-Quotient
Exakter Test nach Fisher
Zusammenhang
linear-mit-linear
Anzahl der gültigen Fälle
Wert df
Asymptotische
Signifikanz
(2-seitig)
Exakte
Signifikanz
(2-seitig)
Exakte
Signifikanz
(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
1 Zellen (25,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeit ist 4,74.b.
Tabelle 44 - Erscheinungsbild und Spaß am
Avatar
Gratulieren * spass<=2 (FILTER) Kreuztabelle
Anzahl
3 6 9
17 12 29
20 18 38
Gratulieren
nichts angekreuzt
Gratulieren
Gesamt
hatten Spass
hatten
keinen Spass
spass<=2 (FILTER)
Gesamt
Chi-Quadrat-Tests
1,762b
1 ,184
,893 1 ,345
1,780 1 ,182
,260 ,173
1,715 1 ,190
38
Chi-Quadrat nach Pearson
Kontinuitätskorrektur a
Likelihood-Quotient
Exakter Test nach Fisher
Zusammenhang
linear-mit-linear
Anzahl der gültigen Fälle
Wert df
Asymptotische
Signifikanz
(2-seitig)
Exakte
Signifikanz
(2-seitig)
Exakte
Signifikanz
(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
2 Zellen (50,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeit ist 4,26.b.
Tabelle 45 - Gratulieren und Spaß am
Avatar
Ränge
20 20,30 406,00
18 18,61 335,00
38
20 17,85 357,00
18 21,33 384,00
38
20 20,20 404,00
18 18,72 337,00
38
spass<=2 (FILTER)
hatten Spass
hatten keinen Spass
Gesamt
hatten Spass
hatten keinen Spass
Gesamt
hatten Spass
hatten keinen Spass
Gesamt
Mundbewegung
Gratulieren
Erscheinungsbild
N Mittlerer Rang Rangsumme](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-96-320.jpg)
![Anhang
97
Statistik für Testb
164,000 147,000 166,000
335,000 357,000 337,000
-,740 -1,310 -,536
,459 ,190 ,592
,654
a
,346
a
,696
a
Mann-Whitney-U
Wilcoxon-W
Z
Asymptotische
Signifikanz (2-seitig)
Exakte Signifikanz
[2*(1-seitig Sig.)]
Mundbewegung Gratulieren Erscheinungsbild
Nicht für Bindungen korrigiert.a.
Gruppenvariable: spass<=2 (FILTER)b.
Tabelle 46 - Menschliche Züge und Spaß im
Mann-Whitney-U-Test
FUNKT_2 * spass<=2 (FILTER) Kreuztabelle
Anzahl
14 14 28
6 4 10
20 18 38
Antworten
nicht angekreuzt
FUNKT_2
Gesamt
hatten Spass
hatten
keinen Spass
spass<=2 (FILTER)
Gesamt
Chi-Quadrat-Tests
,296b
1 ,587
,031 1 ,861
,297 1 ,586
,719 ,432
,288 1 ,592
38
Chi-Quadrat nach Pearson
Kontinuitätskorrektur a
Likelihood-Quotient
Exakter Test nach Fisher
Zusammenhang
linear-mit-linear
Anzahl der gültigen Fälle
Wert df
Asymptotische
Signifikanz
(2-seitig)
Exakte
Signifikanz
(2-seitig)
Exakte
Signifikanz
(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
1 Zellen (25,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeit ist 4,74.b.
Tabelle 47 - Antworten und Spaß am
Avatar
FUNKT_3 * spass<=2 (FILTER) Kreuztabelle
Anzahl
9 10 19
11 8 19
20 18 38
Aufgaben / Termine
nicht angekreuzt
FUNKT_3
Gesamt
hatten Spass
hatten
keinen Spass
spass<=2 (FILTER)
Gesamt
Chi-Quadrat-Tests
,422b
1 ,516
,106 1 ,745
,423 1 ,515
,746 ,373
,411 1 ,521
38
Chi-Quadrat nach Pearson
Kontinuitätskorrektur a
Likelihood-Quotient
Exakter Test nach Fisher
Zusammenhang
linear-mit-linear
Anzahl der gültigen Fälle
Wert df
Asymptotische
Signifikanz
(2-seitig)
Exakte
Signifikanz
(2-seitig)
Exakte
Signifikanz
(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
0 Zellen (,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeit ist 9,00.b.
Tabelle 48 - An Aufgaben/Termine
erinnern und Spaß am Avatar
Ränge
20 18,80 376,00
18 20,28 365,00
38
20 18,55 371,00
18 20,56 370,00
38
spass<=2 (FILTER)
hatten Spass
hatten keinen Spass
Gesamt
hatten Spass
hatten keinen Spass
Gesamt
Antworten
Aufgaben / Termine
N Mittlerer Rang Rangsumme
Statistik für Testb
166,000 161,000
376,000 371,000
-,536 -,641
,592 ,521
,696
a
,593
a
Mann-Whitney-U
Wilcoxon-W
Z
Asymptotische
Signifikanz (2-seitig)
Exakte Signifikanz
[2*(1-seitig Sig.)]
Antworten
Aufgaben /
Termine
Nicht für Bindungen korrigiert.a.
Gruppenvariable: spass<=2 (FILTER)b.
Tabelle 49 - Funktionalität und Spaß im
Mann-Whitney-U-Test
Emotionen * spass<=2 (FILTER) Kreuztabelle
Anzahl
4 1 5
16 17 33
20 18 38
Emotionen
nichts angekreuzt
Emotionen
Gesamt
hatten Spass
hatten
keinen Spass
spass<=2 (FILTER)
Gesamt
Chi-Quadrat-Tests
1,730b
1 ,188
,697 1 ,404
1,852 1 ,173
,344 ,205
1,684 1 ,194
38
Chi-Quadrat nach Pearson
Kontinuitätskorrektur a
Likelihood-Quotient
Exakter Test nach Fisher
Zusammenhang
linear-mit-linear
Anzahl der gültigen Fälle
Wert df
Asymptotische
Signifikanz
(2-seitig)
Exakte
Signifikanz
(2-seitig)
Exakte
Signifikanz
(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
2 Zellen (50,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeit ist 2,37.b.
Tabelle 50 - Emotionsäußerung/-erkennung
und Spaß am Avatar
Eigenleben * spass<=2 (FILTER) Kreuztabelle
Anzahl
3 1 4
17 17 34
20 18 38
Eigenleben
nichts angekreuzt
Eigenleben
Gesamt
hatten Spass
hatten
keinen Spass
spass<=2 (FILTER)
Gesamt](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-97-320.jpg)
![Anhang
98
Chi-Quadrat-Tests
,897b
1 ,344
,175 1 ,676
,941 1 ,332
,606 ,344
,874 1 ,350
38
Chi-Quadrat nach Pearson
Kontinuitätskorrektur a
Likelihood-Quotient
Exakter Test nach Fisher
Zusammenhang
linear-mit-linear
Anzahl der gültigen Fälle
Wert df
Asymptotische
Signifikanz
(2-seitig)
Exakte
Signifikanz
(2-seitig)
Exakte
Signifikanz
(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
2 Zellen (50,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeit ist 1,89.b.
Tabelle 51 - Eigenleben und Spaß am
Avatar
Ränge
20 20,35 407,00
18 18,56 334,00
38
20 20,80 416,00
18 18,06 325,00
38
spass<=2 (FILTER)
hatten Spass
hatten keinen Spass
Gesamt
hatten Spass
hatten keinen Spass
Gesamt
Eigenleben
Emotionen
N Mittlerer Rang Rangsumme
Statistik für Testb
163,000 154,000
334,000 325,000
-,935 -1,298
,350 ,194
,633
a
,460
a
Mann-Whitney-U
Wilcoxon-W
Z
Asymptotische
Signifikanz (2-seitig)
Exakte Signifikanz
[2*(1-seitig Sig.)]
Eigenleben Emotionen
Nicht für Bindungen korrigiert.a.
Gruppenvariable: spass<=2 (FILTER)b.
Tabelle 52 - Emotionen und Spaß im Mann-
Whitney-U-Test
Spracherkennung * ansprach = 2 (FILTER) Kreuztabelle
Anzahl
5 23 28
1 5 6
6 28 34
Spracherkennung
nichts angekreuzt
Spracherkennung
Gesamt
unpersonifiziert personifiziert
ansprach = 2 (FILTER)
Gesamt
Chi-Quadrat-Tests
,005b
1 ,945
,000 1 1,000
,005 1 ,944
1,000 ,719
,005 1 ,945
34
Chi-Quadrat nach Pearson
Kontinuitätskorrektur a
Likelihood-Quotient
Exakter Test nach Fisher
Zusammenhang
linear-mit-linear
Anzahl der gültigen Fälle
Wert df
Asymptotische
Signifikanz
(2-seitig)
Exakte
Signifikanz
(2-seitig)
Exakte
Signifikanz
(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
3 Zellen (75,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeit ist 1,06.b.
Tabelle 53 - Spracherkennung und
Ansprache Avatar
Sprachausgabe * ansprach = 2 (FILTER) Kreuztabelle
Anzahl
5 15 20
1 13 14
6 28 34
Sprachausgabe
nichts angekreuzt
Sprachausgabe
Gesamt
unpersonifiziert personifiziert
ansprach = 2 (FILTER)
Gesamt
Chi-Quadrat-Tests
1,807b
1 ,179
,787 1 ,375
1,990 1 ,158
,364 ,190
1,754 1 ,185
34
Chi-Quadrat nach Pearson
Kontinuitätskorrektur a
Likelihood-Quotient
Exakter Test nach Fisher
Zusammenhang
linear-mit-linear
Anzahl der gültigen Fälle
Wert df
Asymptotische
Signifikanz
(2-seitig)
Exakte
Signifikanz
(2-seitig)
Exakte
Signifikanz
(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
2 Zellen (50,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeit ist 2,47.b.
Tabelle 54 - Sprachausgabe und Ansprache
Avatar
Ränge
6 17,67 106,00
28 17,46 489,00
34
6 21,67 130,00
28 16,61 465,00
34
ansprach = 2 (FILTER)
unpersonifiziert
personifiziert
Gesamt
unpersonifiziert
personifiziert
Gesamt
Spracherkennung
Sprachausgabe
N Mittlerer Rang Rangsumme
Statistik für Testb
83,000 59,000
489,000 465,000
-,068 -1,324
,945 ,185
,982
a
,276
a
Mann-Whitney-U
Wilcoxon-W
Z
Asymptotische
Signifikanz (2-seitig)
Exakte Signifikanz
[2*(1-seitig Sig.)]
Spracherkennung Sprachausgabe
Nicht für Bindungen korrigiert.a.
Gruppenvariable: ansprach = 2 (FILTER)b.
Tabelle 55 -Sprache und Ansprache im
Mann-Whitney-U-Test
Mundbewegung * ansprach = 2 (FILTER) Kreuztabelle
Anzahl
6 6
6 22 28
6 28 34
Mundbewegung
nichts angekreuzt
Mundbewegung
Gesamt
unpersonifiziert personifiziert
ansprach = 2 (FILTER)
Gesamt](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-98-320.jpg)
![Anhang
99
Chi-Quadrat-Tests
1,561b
1 ,211
,435 1 ,510
2,591 1 ,107
,562 ,280
1,515 1 ,218
34
Chi-Quadrat nach Pearson
Kontinuitätskorrektur a
Likelihood-Quotient
Exakter Test nach Fisher
Zusammenhang
linear-mit-linear
Anzahl der gültigen Fälle
Wert df
Asymptotische
Signifikanz
(2-seitig)
Exakte
Signifikanz
(2-seitig)
Exakte
Signifikanz
(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
3 Zellen (75,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeit ist 1,06.b.
Tabelle 56 - Mundbewegung und
Ansprache Avatar
Gratulieren * ansprach = 2 (FILTER) Kreuztabelle
Anzahl
1 8 9
5 20 25
6 28 34
Gratulieren
nichts angekreuzt
Gratulieren
Gesamt
unpersonifiziert personifiziert
ansprach = 2 (FILTER)
Gesamt
Chi-Quadrat-Tests
,360b
1 ,549
,008 1 ,928
,389 1 ,533
1,000 ,487
,349 1 ,555
34
Chi-Quadrat nach Pearson
Kontinuitätskorrektur a
Likelihood-Quotient
Exakter Test nach Fisher
Zusammenhang
linear-mit-linear
Anzahl der gültigen Fälle
Wert df
Asymptotische
Signifikanz
(2-seitig)
Exakte
Signifikanz
(2-seitig)
Exakte
Signifikanz
(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
2 Zellen (50,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeit ist 1,59.b.
Tabelle 57 - Gratulieren und Ansprache
Avatar
Erscheinungsbild * ansprach = 2 (FILTER) Kreuztabelle
Anzahl
1 9 10
5 19 24
6 28 34
Erscheinungsbild
nichts angekreuzt
Erscheinungsbild
Gesamt
unpersonifiziert personifiziert
ansprach = 2 (FILTER)
Gesamt
Chi-Quadrat-Tests
,570b
1 ,450
,068 1 ,794
,623 1 ,430
,644 ,416
,553 1 ,457
34
Chi-Quadrat nach Pearson
Kontinuitätskorrektur a
Likelihood-Quotient
Exakter Test nach Fisher
Zusammenhang
linear-mit-linear
Anzahl der gültigen Fälle
Wert df
Asymptotische
Signifikanz
(2-seitig)
Exakte
Signifikanz
(2-seitig)
Exakte
Signifikanz
(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
2 Zellen (50,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeit ist 1,76.b.
Tabelle 58 - Erscheinungsbild und
Ansprache Avatar
Ränge
6 14,50 87,00
28 18,14 508,00
34
6 15,83 95,00
28 17,86 500,00
34
6 15,33 92,00
28 17,96 503,00
34
ansprach = 2 (FILTER)
unpersonifiziert
personifiziert
Gesamt
unpersonifiziert
personifiziert
Gesamt
unpersonifiziert
personifiziert
Gesamt
Mundbewegung
Gratulieren
Erscheinungsbild
N Mittlerer Rang Rangsumme
Statistik für Testb
66,000 74,000 71,000
87,000 95,000 92,000
-1,231 -,591 -,744
,218 ,555 ,457
,439
a
,676
a
,581
a
Mann-Whitney-U
Wilcoxon-W
Z
Asymptotische
Signifikanz (2-seitig)
Exakte Signifikanz
[2*(1-seitig Sig.)]
Mundbewegung Gratulieren Erscheinungsbild
Nicht für Bindungen korrigiert.a.
Gruppenvariable: ansprach = 2 (FILTER)b.
Tabelle 59 - Menschliche Züge und
Ansprache im Mann-Whitney-U-Test
FUNKT_2 * ansprach = 2 (FILTER) Kreuztabelle
Anzahl
6 19 25
9 9
6 28 34
Antworten
nicht angekreuzt
FUNKT_2
Gesamt
unpersonifiziert personifiziert
ansprach = 2 (FILTER)
Gesamt
Chi-Quadrat-Tests
2,623b
1 ,105
1,231 1 ,267
4,134 1 ,042
,162 ,132
2,546 1 ,111
34
Chi-Quadrat nach Pearson
Kontinuitätskorrektur a
Likelihood-Quotient
Exakter Test nach Fisher
Zusammenhang
linear-mit-linear
Anzahl der gültigen Fälle
Wert df
Asymptotische
Signifikanz
(2-seitig)
Exakte
Signifikanz
(2-seitig)
Exakte
Signifikanz
(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
2 Zellen (50,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeit ist 1,59.b.
Tabelle 60 - Antworten und Ansprache
Avatar
FUNKT_3 * ansprach = 2 (FILTER) Kreuztabelle
Anzahl
3 14 17
3 14 17
6 28 34
Aufgaben / Termine
nicht angekreuzt
FUNKT_3
Gesamt
unpersonifiziert personifiziert
ansprach = 2 (FILTER)
Gesamt
Chi-Quadrat-Tests
,000b
1 1,000
,000 1 1,000
,000 1 1,000
1,000 ,672
,000 1 1,000
34
Chi-Quadrat nach Pearson
Kontinuitätskorrektur a
Likelihood-Quotient
Exakter Test nach Fisher
Zusammenhang
linear-mit-linear
Anzahl der gültigen Fälle
Wert df
Asymptotische
Signifikanz
(2-seitig)
Exakte
Signifikanz
(2-seitig)
Exakte
Signifikanz
(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
2 Zellen (50,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeit ist 3,00.b.
Tabelle 61 - An Aufgaben/Termine
erinnern und Ansprache Avatar](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-99-320.jpg)
![Anhang
100
Ränge
6 22,00 132,00
28 16,54 463,00
34
6 17,50 105,00
28 17,50 490,00
34
ansprach = 2 (FILTER)
unpersonifiziert
personifiziert
Gesamt
unpersonifiziert
personifiziert
Gesamt
Antworten
Aufgaben / Termine
N Mittlerer Rang Rangsumme
Statistik für Testb
57,000 84,000
463,000 490,000
-1,596 ,000
,111 1,000
,238
a
1,000
a
Mann-Whitney-U
Wilcoxon-W
Z
Asymptotische
Signifikanz (2-seitig)
Exakte Signifikanz
[2*(1-seitig Sig.)]
Antworten
Aufgaben /
Termine
Nicht für Bindungen korrigiert.a.
Gruppenvariable: ansprach = 2 (FILTER)b.
Tabelle 62 - Funktionalität und Ansprache
im Mann-Whitney-U-Test
Emotionen * ansprach = 2 (FILTER) Kreuztabelle
Anzahl
5 5
6 23 29
6 28 34
Emotionen
nichts angekreuzt
Emotionen
Gesamt
unpersonifiziert personifiziert
ansprach = 2 (FILTER)
Gesamt
Chi-Quadrat-Tests
1,256b
1 ,262
,236 1 ,627
2,119 1 ,146
,559 ,353
1,219 1 ,270
34
Chi-Quadrat nach Pearson
Kontinuitätskorrektur a
Likelihood-Quotient
Exakter Test nach Fisher
Zusammenhang
linear-mit-linear
Anzahl der gültigen Fälle
Wert df
Asymptotische
Signifikanz
(2-seitig)
Exakte
Signifikanz
(2-seitig)
Exakte
Signifikanz
(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
2 Zellen (50,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeit ist ,88.b.
Tabelle 63 - Emotionserkennung/-äußerung
und Ansprache Avatar
Eigenleben * ansprach = 2 (FILTER) Kreuztabelle
Anzahl
1 3 4
5 25 30
6 28 34
Eigenleben
nichts angekreuzt
Eigenleben
Gesamt
unpersonifiziert personifiziert
ansprach = 2 (FILTER)
Gesamt
Chi-Quadrat-Tests
,169b
1 ,681
,000 1 1,000
,156 1 ,693
,559 ,559
,164 1 ,686
34
Chi-Quadrat nach Pearson
Kontinuitätskorrektur a
Likelihood-Quotient
Exakter Test nach Fisher
Zusammenhang
linear-mit-linear
Anzahl der gültigen Fälle
Wert df
Asymptotische
Signifikanz
(2-seitig)
Exakte
Signifikanz
(2-seitig)
Exakte
Signifikanz
(1-seitig)
Wird nur für eine 2x2-Tabelle berechneta.
2 Zellen (50,0%) haben eine erwartete Häufigkeit kleiner 5. Die minimale erwartete Häufigkeit ist ,71.b.
Tabelle 64 - Eigenleben und Ansprache
Avatar
Ränge
6 18,33 110,00
28 17,32 485,00
34
6 15,00 90,00
28 18,04 505,00
34
ansprach = 2 (FILTER)
unpersonifiziert
personifiziert
Gesamt
unpersonifiziert
personifiziert
Gesamt
Eigenleben
Emotionen
N Mittlerer Rang Rangsumme
Statistik für Testb
79,000 69,000
485,000 90,000
-,405 -1,104
,686 ,270
,843
a
,522
a
Mann-Whitney-U
Wilcoxon-W
Z
Asymptotische
Signifikanz (2-seitig)
Exakte Signifikanz
[2*(1-seitig Sig.)]
Eigenleben Emotionen
Nicht für Bindungen korrigiert.a.
Gruppenvariable: ansprach = 2 (FILTER)b.
Tabelle 65 - Emotionen und Ansprache im
Mann-Whitney-U-Test
Ränge
19 19,92 378,50
20 20,08 401,50
39
19 21,32 405,00
20 18,75 375,00
39
alter_mediansplit
bis einsch. 27
über 27
Gesamt
bis einsch. 27
über 27
Gesamt
Spracherkennung
Sprachausgabe
N Mittlerer Rang Rangsumme
Statistik für Testb
188,500 165,000
378,500 375,000
-,067 -,818
,946 ,414
,967
a
,496
a
Mann-Whitney-U
Wilcoxon-W
Z
Asymptotische
Signifikanz (2-seitig)
Exakte Signifikanz
[2*(1-seitig Sig.)]
Spracherkennung Sprachausgabe
Nicht für Bindungen korrigiert.a.
Gruppenvariable: alter_mediansplitb.
Tabelle 66 - Sprache und Altersgruppen im
Median-Split im Mann-Whitney-U](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-100-320.jpg)
![Anhang
101
Ränge
19 22,13 420,50
20 17,98 359,50
39
19 20,63 392,00
20 19,40 388,00
39
19 19,63 373,00
20 20,35 407,00
39
alter_mediansplit
bis einsch. 27
über 27
Gesamt
bis einsch. 27
über 27
Gesamt
bis einsch. 27
über 27
Gesamt
Mundbewegung
Gratulieren
Erscheinungsbild
N Mittlerer Rang Rangsumme
Statistik für Testb
149,500 178,000 183,000
359,500 388,000 373,000
-1,820 -,462 -,252
,069 ,644 ,801
,258
a
,749
a
,857
a
Mann-Whitney-U
Wilcoxon-W
Z
Asymptotische
Signifikanz (2-seitig)
Exakte Signifikanz
[2*(1-seitig Sig.)]
Mundbewegung Gratulieren Erscheinungsbild
Nicht für Bindungen korrigiert.a.
Gruppenvariable: alter_mediansplitb.
Tabelle 67 - Menschliche Züge und
Altersgruppen im Median-Split im Mann-
Whitney-U
Ränge
19 20,89 397,00
20 19,15 383,00
39
19 23,34 443,50
20 16,83 336,50
39
alter_mediansplit
bis einsch. 27
über 27
Gesamt
bis einsch. 27
über 27
Gesamt
Antworten
Aufgaben / Termine
N Mittlerer Rang Rangsumme
Statistik für Testb
173,000 126,500
383,000 336,500
-,631 -2,060
,528 ,039
,647
a
,074
a
Mann-Whitney-U
Wilcoxon-W
Z
Asymptotische
Signifikanz (2-seitig)
Exakte Signifikanz
[2*(1-seitig Sig.)]
Antworten
Aufgaben /
Termine
Nicht für Bindungen korrigiert.a.
Gruppenvariable: alter_mediansplitb.
Tabelle 68 - Funktionalität und
Altersgruppen im Median-Split im Mann-
Whitney-U
Ränge
19 20,05 381,00
20 19,95 399,00
39
19 20,58 391,00
20 19,45 389,00
39
alter_mediansplit
bis einsch. 27
über 27
Gesamt
bis einsch. 27
über 27
Gesamt
Eigenleben
Emotionen
N Mittlerer Rang Rangsumme
Statistik für Testb
189,000 179,000
399,000 389,000
-,053 -,534
,957 ,594
,989
a
,771
a
Mann-Whitney-U
Wilcoxon-W
Z
Asymptotische
Signifikanz (2-seitig)
Exakte Signifikanz
[2*(1-seitig Sig.)]
Eigenleben Emotionen
Nicht für Bindungen korrigiert.a.
Gruppenvariable: alter_mediansplitb.
Tabelle 69 - Emotionen und Altersgruppen
im Median-Split im Mann-Whitney-U
Ränge
5 15,20
14 21,61
15 20,40
5 19,10
39
5 20,70
14 21,54
15 18,10
5 20,70
39
Altersgruppe
13-20 Jahre
21-28 Jahre
29-36 Jahre
37-43 Jahre
Gesamt
13-20 Jahre
21-28 Jahre
29-36 Jahre
37-43 Jahre
Gesamt
Spracherkennung
Sprachausgabe
N Mittlerer Rang
Statistik für Testa,b
3,106 ,959
3 3
,376 ,811
Chi-Quadrat
df
Asymptotische Signifikanz
Spracherkennung Sprachausgabe
Kruskal-Wallis-Testa.
Gruppenvariable: Altersgruppeb.
Tabelle 70 - Sprache und Altersgruppen 1-4
im Mann-Whitney-U
Ränge
5 24,80
14 21,18
15 18,30
5 17,00
39
5 23,30
14 19,68
15 19,40
5 19,40
39
5 26,20
14 17,29
15 21,00
5 18,40
39
Altersgruppe
13-20 Jahre
21-28 Jahre
29-36 Jahre
37-43 Jahre
Gesamt
13-20 Jahre
21-28 Jahre
29-36 Jahre
37-43 Jahre
Gesamt
13-20 Jahre
21-28 Jahre
29-36 Jahre
37-43 Jahre
Gesamt
Mundbewegung
Gratulieren
Erscheinungsbild
N Mittlerer Rang](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-101-320.jpg)
![Anhang
102
Statistik für Testa,b
4,389 ,911 4,089
3 3 3
,222 ,823 ,252
Chi-Quadrat
df
Asymptotische Signifikanz
Mundbewegung Gratulieren Erscheinungsbild
Kruskal-Wallis-Testa.
Gruppenvariable: Altersgruppeb.
Tabelle 71 - Menschliche Züge und
Altersgruppen 1-4 im Mann-Whitney-U
Ränge
5 21,10
14 20,82
15 18,50
5 21,10
39
5 17,80
14 25,32
15 17,80
5 13,90
39
Altersgruppe
13-20 Jahre
21-28 Jahre
29-36 Jahre
37-43 Jahre
Gesamt
13-20 Jahre
21-28 Jahre
29-36 Jahre
37-43 Jahre
Gesamt
Antworten
Aufgaben / Termine
N Mittlerer Rang
Statistik für Testa,b
,743 6,967
3 3
,863 ,073
Chi-Quadrat
df
Asymptotische Signifikanz
Antworten
Aufgaben /
Termine
Kruskal-Wallis-Testa.
Gruppenvariable: Altersgruppeb.
Tabelle 72 - Funktionalität und
Altersgruppen 1-4 im Mann-Whitney-U
Ränge
5 18,00
14 20,79
15 20,60
5 18,00
39
5 21,40
14 20,29
15 18,80
5 21,40
39
Altersgruppe
13-20 Jahre
21-28 Jahre
29-36 Jahre
37-43 Jahre
Gesamt
13-20 Jahre
21-28 Jahre
29-36 Jahre
37-43 Jahre
Gesamt
Eigenleben
Emotionen
N Mittlerer Rang
Statistik für Testa,b
1,504 ,971
3 3
,681 ,808
Chi-Quadrat
df
Asymptotische Signifikanz
Eigenleben Emotionen
Kruskal-Wallis-Testa.
Gruppenvariable: Altersgruppeb.
Tabelle 73 - Emotionen und Altersgruppen
1-4 im Mann-Whitney-U
Ränge
24 20,56 493,50
15 19,10 286,50
39
24 19,56 469,50
15 20,70 310,50
39
Geschlecht
männlich
weiblich
Gesamt
männlich
weiblich
Gesamt
Spracherkennung
Sprachausgabe
N Mittlerer Rang Rangsumme
Statistik für Testb
166,500 169,500
286,500 469,500
-,623 -,353
,533 ,724
,700
a
,765
a
Mann-Whitney-U
Wilcoxon-W
Z
Asymptotische
Signifikanz (2-seitig)
Exakte Signifikanz
[2*(1-seitig Sig.)]
Spracherkennung Sprachausgabe
Nicht für Bindungen korrigiert.a.
Gruppenvariable: Geschlechtb.
Tabelle 74 - Sprache und Geschlecht im
Mann-Whitney-U
Ränge
24 20,25 486,00
15 19,60 294,00
39
24 18,75 450,00
15 22,00 330,00
39
24 19,38 465,00
15 21,00 315,00
39
Geschlecht
männlich
weiblich
Gesamt
männlich
weiblich
Gesamt
männlich
weiblich
Gesamt
Mundbewegung
Gratulieren
Erscheinungsbild
N Mittlerer Rang Rangsumme
Statistik für Testb
174,000 150,000 165,000
294,000 450,000 465,000
-,277 -1,186 -,555
,782 ,235 ,579
,875
a
,399
a
,679
a
Mann-Whitney-U
Wilcoxon-W
Z
Asymptotische
Signifikanz (2-seitig)
Exakte Signifikanz
[2*(1-seitig Sig.)]
Mundbewegung Gratulieren Erscheinungsbild
Nicht für Bindungen korrigiert.a.
Gruppenvariable: Geschlechtb.
Tabelle 75 – Menschliche Züge und
Geschlecht im Mann-Whitney-U
Ränge
24 21,75 522,00
15 17,20 258,00
39
24 19,75 474,00
15 20,40 306,00
39
Geschlecht
männlich
weiblich
Gesamt
männlich
weiblich
Gesamt
Antworten
Aufgaben / Termine
N Mittlerer Rang Rangsumme](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-102-320.jpg)
![Anhang
103
Statistik für Testb
138,000 174,000
258,000 474,000
-1,603 -,200
,109 ,841
,234
a
,875
a
Mann-Whitney-U
Wilcoxon-W
Z
Asymptotische
Signifikanz (2-seitig)
Exakte Signifikanz
[2*(1-seitig Sig.)]
Antworten
Aufgaben /
Termine
Nicht für Bindungen korrigiert.a.
Gruppenvariable: Geschlechtb.
Tabelle 76 - Funktionalität und Geschlecht
im Mann-Whitney-U
Ränge
24 20,44 490,50
15 19,30 289,50
39
24 19,13 459,00
15 21,40 321,00
39
Geschlecht
männlich
weiblich
Gesamt
männlich
weiblich
Gesamt
Eigenleben
Emotionen
N Mittlerer Rang Rangsumme
Statistik für Testb
169,500 159,000
289,500 459,000
-,577 -1,047
,564 ,295
,765
a
,558
a
Mann-Whitney-U
Wilcoxon-W
Z
Asymptotische
Signifikanz (2-seitig)
Exakte Signifikanz
[2*(1-seitig Sig.)]
Eigenleben Emotionen
Nicht für Bindungen korrigiert.a.
Gruppenvariable: Geschlechtb.
Tabelle 77 - Emotionen und Geschlecht im
Mann-Whitney-U](https://image.slidesharecdn.com/final-180926092635/85/Thesis-Speech-interaction-and-anthropomorphic-interface-agents-in-multimodal-interactive-systems-103-320.jpg)

















