Als PDF, PPTX herunterladen









































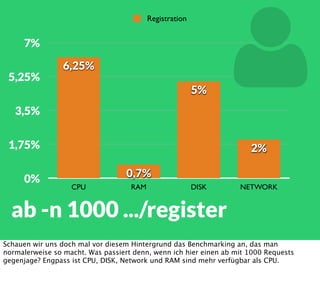

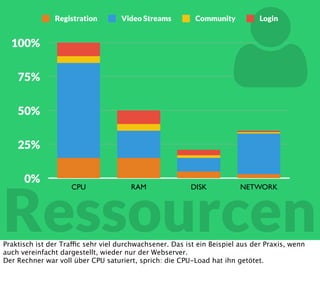



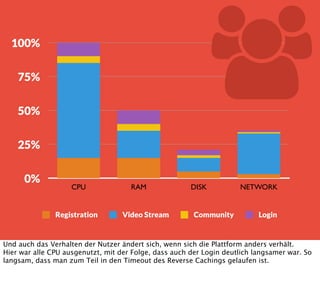



















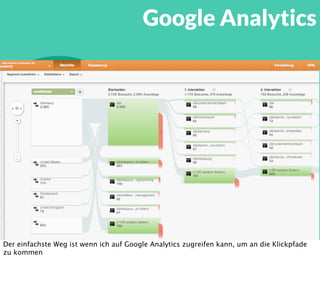









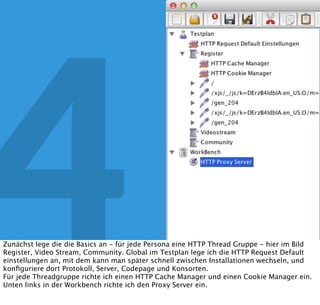

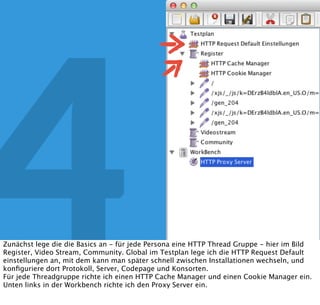
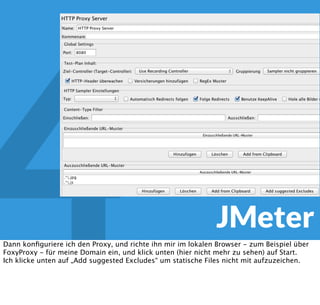

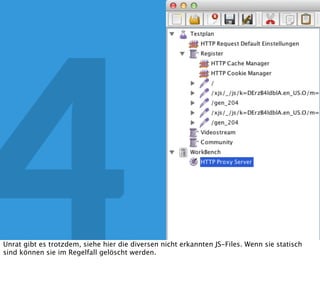
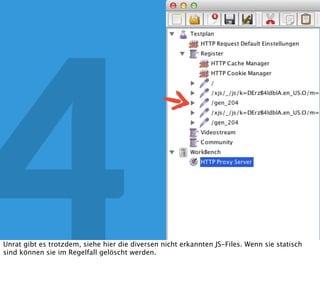
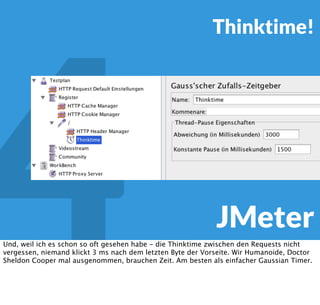
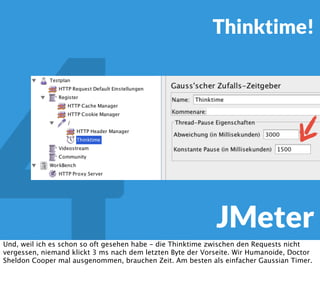
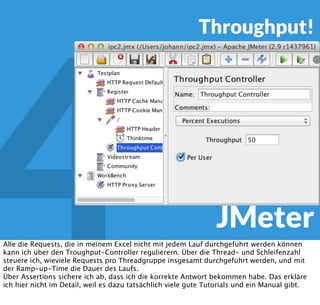



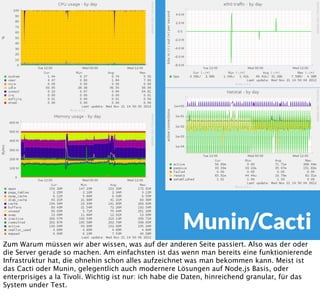


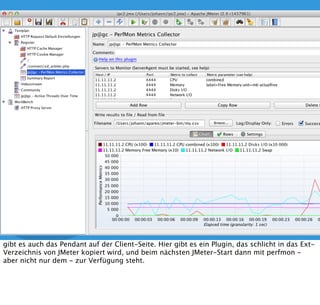





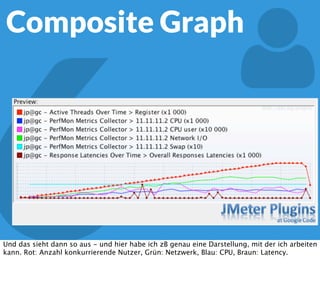
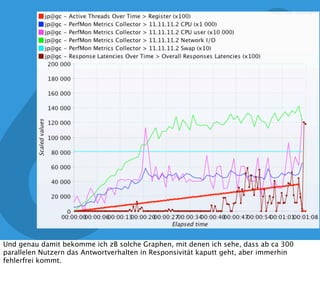















In diesem Dokument wird über die Herausforderungen und Praktiken der Performancemessung, insbesondere im Kontext von Webapplikationen, diskutiert. Der Autor teilt Erkenntnisse darüber, wie Performance-Tests oft unzureichend durchgeführt werden, und betont die Wichtigkeit der Nutzung von Tools wie JMeter für zuverlässige Ergebnisse. Das Dokument beschreibt außerdem, wie sich Systemressourcen auf Nutzerverhalten auswirken und wie eng beides miteinander verbunden ist.



































































