![Web@rchiv Österreich Webarchivierung an der Österreichischen Nationalbibliothek Michaela Mayr Österreichische Nationalbibliothek [email_address] www.onb.ac.at](https://image.slidesharecdn.com/mayrliest20100818-101019072116-phpapp01/85/Osterreich-liest-Vortrag-zum-Web-rchiv-Osterreich-1-320.jpg)
![Web@rchiv Österreich Webarchivierung an der Österreichischen Nationalbibliothek Michaela Mayr Österreichische Nationalbibliothek [email_address] www.onb.ac.at](https://image.slidesharecdn.com/mayrliest20100818-101019072116-phpapp01/75/Osterreich-liest-Vortrag-zum-Web-rchiv-Osterreich-1-2048.jpg)






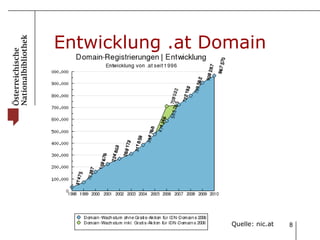



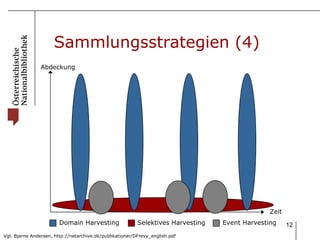

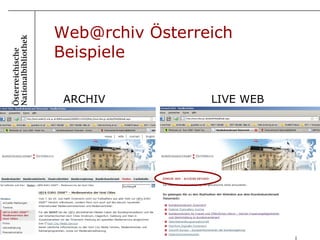


Das Dokument beschreibt das Webarchivierungsprojekt 'web@rchiv' der Österreichischen Nationalbibliothek, welches 2008 ins Leben gerufen wurde und seit 2009 tätig ist, um Internetinhalte als nationales Kulturgut langfristig zu sichern. Es werden verschiedene Strategien wie Domain-Harvesting, selektives Harvesting und Event-Harvesting eingesetzt, um eine breite Sammlung von Websites zu gewährleisten, insbesondere aus den Bereichen Medien, Kultur und Wissenschaft. Aktuell umfasst das Archiv etwa 6,2 TB komprimierte Daten, die 420 Millionen Objekte beinhalten.
































