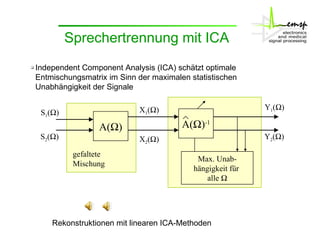
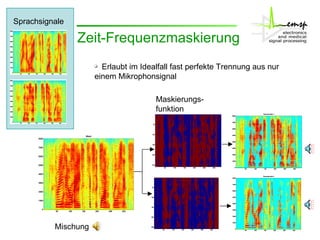
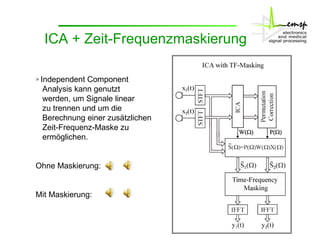
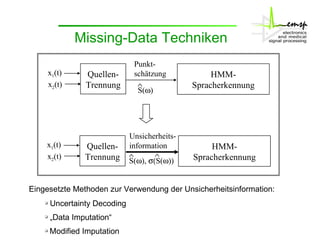
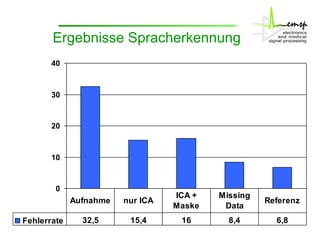
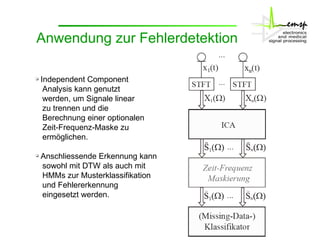
Das Dokument behandelt die Aktivitäten des Instituts zur Signaltrennung, insbesondere durch interne Komponentenanalysen (ICA) und Zeit-Frequenzmaskierung zur robusten Spracherkennung. Es wird erläutert, wie diese Methoden zur Rekonstruktion und Trennung von Sprachsignalen in gestörten Umgebungen verwendet werden können, sowie deren Auswirkungen auf die Signalqualität und Erkennung. Zudem wird die Anwendung von Missing-Data-Techniken zur Verbesserung der Spracherkennung in Verbindung mit ICA hervorgehoben.