21-mal heruntergeladen



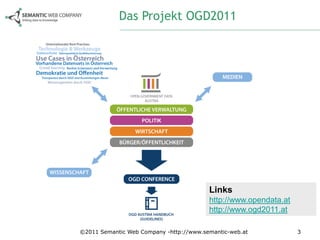


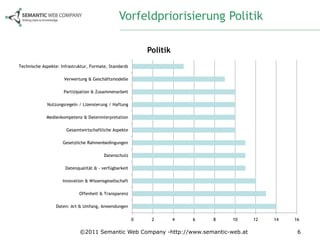
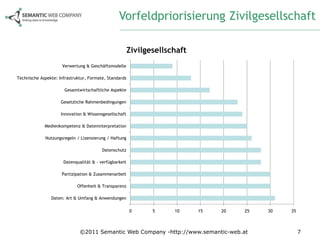
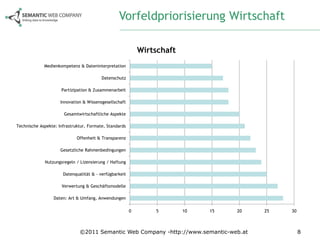
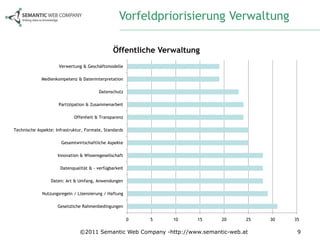
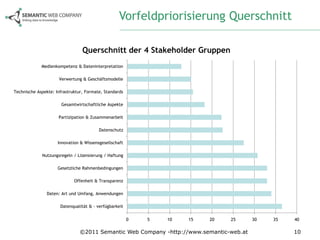






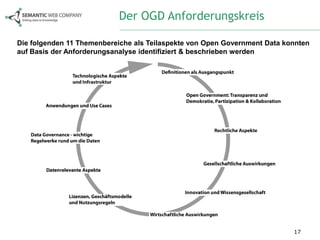





Das Dokument beschreibt die Anforderungsanalyse für Open Government Data (OGD) in Österreich im Rahmen des Projekts ogd2011, das zwischen September 2010 und Juli 2011 stattfand. Es umfasst Workshops mit verschiedenen Stakeholder-Gruppen aus Politik, Zivilgesellschaft, Wirtschaft und öffentlicher Verwaltung, um relevante Themen und Herausforderungen zu identifizieren. Außerdem werden konkrete Anforderungen und Empfehlungen für die Umsetzung von OGD in Österreich formuliert, einschließlich der Notwendigkeit eines zentralen Datenportals und der Harmonisierung von Datenstandards.



































































