Als PDF, PPTX herunterladen














![MapReduce & Apache Hadoop Folie 29
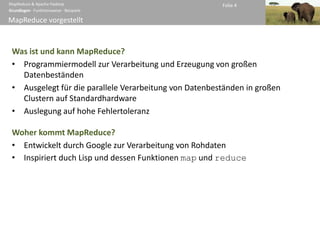
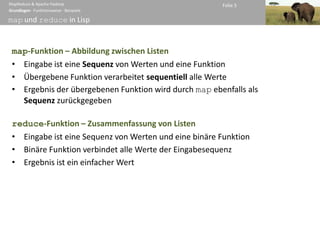
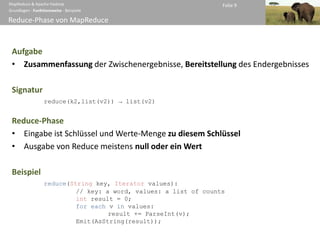
Geschichte ∙ Architektur ∙ MapReduce-Anwendungen ∙ Beispiele ∙ Zusammenfassung
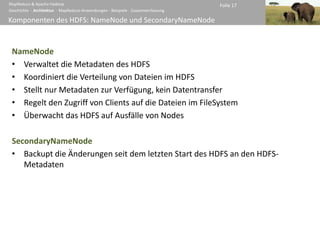
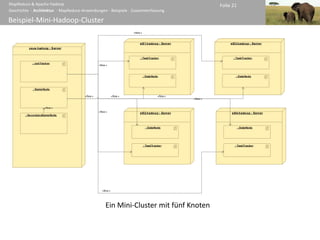
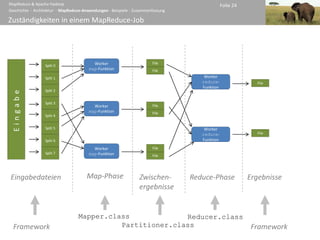
LogFileSorter – Der Job
public class LogFileSorter {
Auswertung der Befe
public static void main(String[] args)
throws IOException, ClassNotFoundException, InterruptedException
{
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
Job job = new Job(conf, LogFileSearch.class.getSimpleName());
job.setJarByClass(LogFileSearch.class);
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(LFSMapperSearch.class);
job.setOutputKeyClass(LFSBPKey.class); Konfiguration des Jobs
job.setOutputValueClass(Text.class); (Zuweisung der Zuständigkeiten)
job.setPartitionerClass(LFSBPPartioner.class);
job.setReducerClass(LFSReducer.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileInputFormat.setInputPathFilter(job, LFSPathFilter.class); Konfiguration der Job-
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
Eingabe und der Job-
System.exit(job.waitForCompletion(true) ? 0 : 1); Ausgabe
}
}](https://image.slidesharecdn.com/mr-hadoop-100122091621-phpapp01/85/MapReduce-Apache-Hadoop-29-320.jpg)



Das Dokument beschreibt MapReduce, ein Programmiermodell zur parallelen Verarbeitung großer Datenmengen in Clustern, das von Google entwickelt wurde. Es erklärt die beiden Phasen des Modells - Map und Reduce - sowie die Architektur von Apache Hadoop, einem offenen Framework zur Implementierung von MapReduce-Anwendungen. Zudem werden die Komponenten des Hadoop-Ökosystems, wie das Hadoop Distributed File System (HDFS) und die Rollen von Jobtracker und Tasktracker, behandelt.



























