Als PDF, PPTX herunterladen



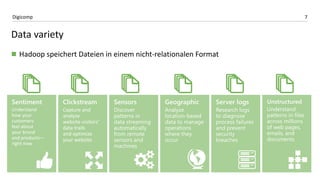

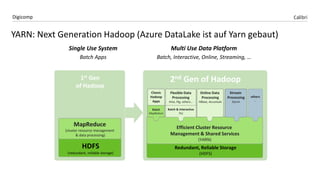
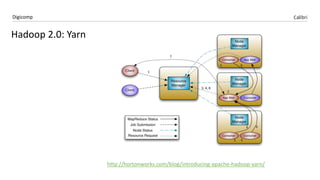



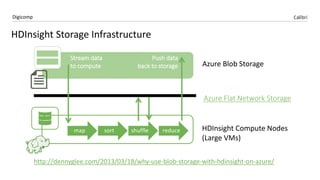









Das Dokument behandelt die Microsoft BI-Plattform in der Cloud, insbesondere die Implementierung von Apache Hadoop und Azure HDInsight. Es hebt die Vorteile von Hadoop bezüglich Speicherung und Verarbeitung großer Datenmengen hervor und erklärt die Integration von Self-Service BI mit Power BI sowie Azure Data Lake. Zu den Schlüsselfunktionen zählen verteilte Speicherung, fehlertolerante Architektur und die Möglichkeit, Daten aus verschiedenen Quellen zu kombinieren.















































