Downloaden Sie, um offline zu lesen













![my_aggregation:
19
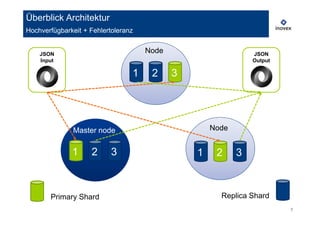
Das Aggregations Framework (aggs)
spezifische Analysen durch “nested aggregators” realisierbar
"aggregations": {
"<aggregation_name>": {
"<aggregation_type>": {
<aggregation_body>
},
["aggregations": { [<sub_aggregation>]* }]
}
[,"<aggregation_name_2>": { … }]*
}
bucket 1 bucket 2 bucket n metrics…](https://image.slidesharecdn.com/webinar-elasticsearch-und-big-data-inovex-23-140731041834-phpapp02/85/Elasticsearch-und-Big-Data-Webinar-vom-23-07-2014-19-320.jpg)



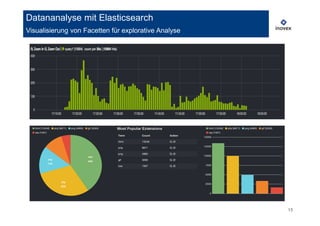
Das Dokument von Bernhard Pflugfelder behandelt die Anwendung von Elasticsearch zur Analyse von Big Data und beschreibt die Architektur, Datenimporte und das Aggregationsframework für die Datenanalyse. Besonderes Augenmerk liegt auf der Integration von Logstash und Hadoop für die effiziente Datenverarbeitung sowie auf der hohen Verfügbarkeit und Skalierbarkeit von Elasticsearch als dokumentenorientierte Datenbank. Es werden auch verschiedene Aggregationstypen und deren Einsatzmöglichkeiten in der Datenanalyse vorgestellt.



























