Downloaden Sie, um offline zu lesen




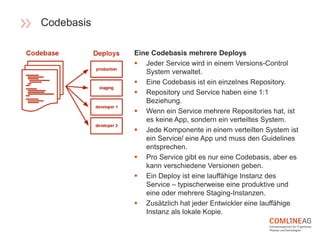
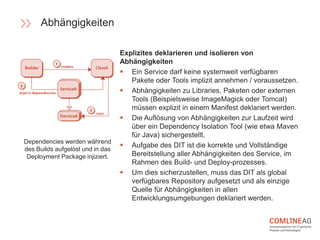


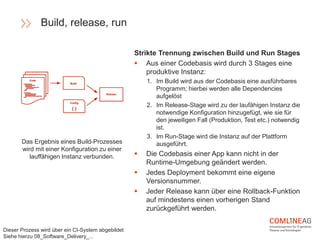





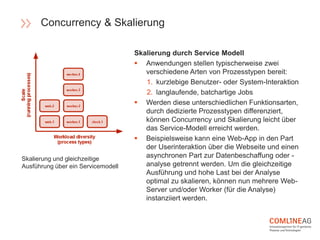

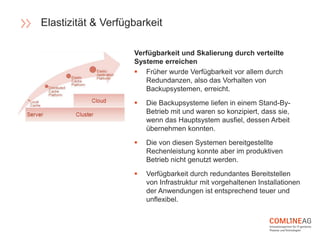

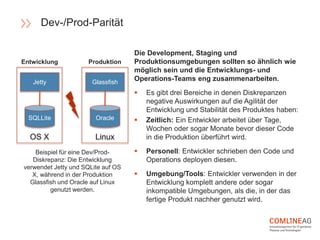



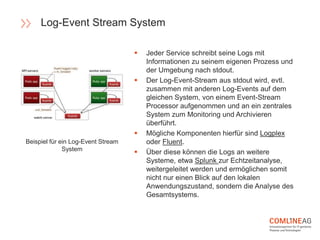




Die Comline AG stellt Richtlinien für die Software-Entwicklung innerhalb der Open Platform vor, die sich auf Architektur, Codebasen, Abhängigkeiten und der Trennung von Konfiguration und Code konzentrieren. Wichtige Konzepte sind CQRS zur Trennung von Lese- und Schreiboperationen, die Entwicklung verteilter Systeme mit speziellen Richtlinien für Backend-Dienste, und die Notwendigkeit, dass Entwicklungs- und Produktionsumgebungen möglichst ähnlich bleiben. Zudem wird Wert auf Elastizität und Verfügbarkeit gelegt, um eine agile und effiziente Softwarebereitstellung zu gewährleisten.













































