



![Parallele Programmiermodelle MPI Unabhängige Prozesse Kein globales Speichermodell Kommunikation-Bibliothek Kommunikation und Lastverteilung muss explizit programmiert werden API MPI_Send(buff, cnt, type, dest, tag, comm) MPI_Recv(buff, cnt, type, src, tag, status) MPI_Reduce(send_buf, recv_buf, cnt, type, MPI_SUM, 0, comm) MPI_Barrier(comm) OpenMP Parallelität durch Threads Global-addressierbarer Speicher Automatische Lastverteilung API #pragma omp for private i for (i=0; i <n; i++){ a[i] += b[i] * c[i]; }](https://image.slidesharecdn.com/20090519kerskenvampir-090618234632-phpapp02/85/VampirTrace-und-Vampir-5-320.jpg)






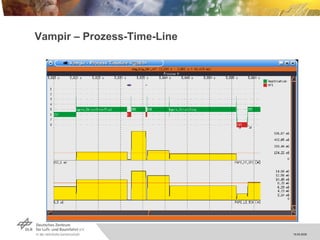






Die Techtalk-Präsentation von Hans-Peter Kersken behandelt die Performance-Analyse in Hochleistungsrechnen (HPC), insbesondere die Verwendung von Vampirtrace zur zeitlichen Nachverfolgung und Analyse von parallelen Programmiermodellen wie MPI und OpenMP. Es werden die Vorteile und Herausforderungen der Performance-Analyse, einschließlich des Laufzeit-Overheads und der Komplexität von printf-Tracking, angesprochen. Das Dokument stellt auch verschiedene Tools und Frameworks vor, die zur Optimierung der Performance und zur Visualisierung von Laufzeitverhalten eingesetzt werden können.











































