21-mal heruntergeladen
























![Sprachen des Semantic Web - RDF
●
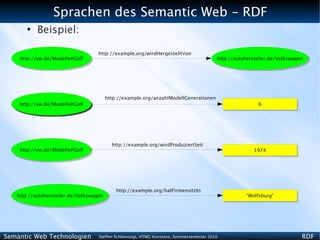
ENTITYs zur Abkürzung von URIs
– Durch Definition von ENTITYs (siehe XML-Vorlesung) können
lange Textstrings abgekürzt werden
– Dies können wir in Attributwerten verwenden
<?xml version=”1.0” encoding=”utf8”?>
<!DOCTYPE rdf:RDF [
<!ENTITY rdf "http://www.w3.org/1999/02/22rdfsyntaxns#">
<!ENTITY vwmodell “http://vw.de/Modelle#”>
<!ENTITY hersteller “http://autohersteller.de/”> ]>
<rdf:RDF xmlns:rdf=”http://www.w3.org/1999/02/22rdfsyntaxns#”
xmlns:ex=”http://example.org/”
xmlns:vwmodell=”http://vw.de/Modelle#”
xmlns:hersteller=”http://autohersteller.de/” >
<rdf:Description rdf:about=”&vwmodell;Golf”>
<ex:wirdHergestelltVon>
<rdf:Description rdf:about=”&hersteller;Volkswagen” >
<ex:hatFirmensitzIn>Wolfsburg</ex:hatFirmensitzIn>
</rdf:Description>
</ex:wirdHergestelltVon>
</rdf:Description>
</rdf:RDF>
Semantic Web Technologien Steffen Schlönvoigt, HTWG Konstanz, Sommersemester 2010 RDF](https://image.slidesharecdn.com/swtss1003rdf-100418030202-phpapp01/85/Semantic-Web-Technologies-SS-2010-03-RDF-25-320.jpg)














![Sprachen des Semantic Web - RDF
●
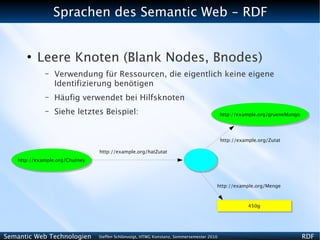
Leere Knoten
– Turtle-Syntax
@prefix ex: <http://example.org> .
ex:Chutney ex:hatZutat _:id1 .
_:id1 ex:Zutat ex:grueneMango ;
ex:Menge “450g”.
– Verkürzt
@prefix ex: <http://example.org> .
ex:Chutney ex:hatZutat [ ex:Zutat ex:grueneMango ;
ex:Menge “450g” ].
Semantic Web Technologien Steffen Schlönvoigt, HTWG Konstanz, Sommersemester 2010 RDF](https://image.slidesharecdn.com/swtss1003rdf-100418030202-phpapp01/85/Semantic-Web-Technologies-SS-2010-03-RDF-41-320.jpg)










Das Dokument behandelt die Grundlagen der RDF-Sprachen im Kontext des Semantic Web, insbesondere die Strukturierung und Beschreibung von Daten mittels RDF (Resource Description Framework). Es erläutert die Problematik der hierarchischen Baumstruktur von XML und präsentiert Graphen als ein geeigneteres Modell zur Organisation von Informationen im Semantic Web. Zudem werden die verschiedenen Formate zur Serialisierung von RDF-Daten und die Syntax der Triple zur Beschreibung von Beziehungen zwischen Ressourcen diskutiert.















































