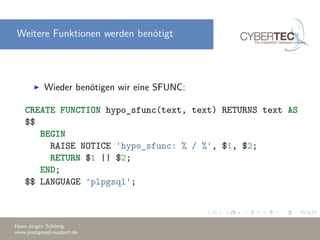
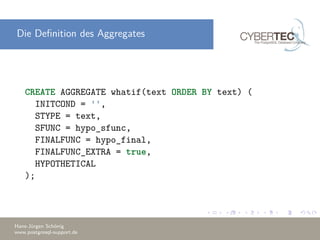
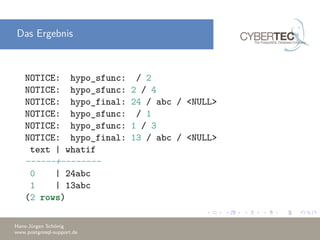
Das Dokument beschreibt, wie man in PostgreSQL eigene Aggregatfunktionen erstellt, einschließlich einfacher Aggregates, Fensterfunktionen und hypothetische Aggregates. Es werden Grundlagen und technische Details erläutert, wie etwa die Erstellung von Funktionen, um Aggregationen aus mehreren Zeilen zu bilden, sowie Optimierungstechniken zur Reduzierung der Funktionsaufrufe. Am Ende werden Beispiele für die Anwendung dieser Konzepte gegeben.



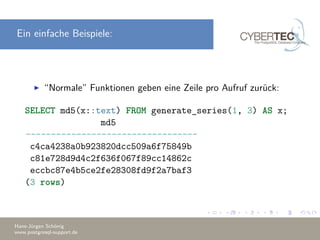

![Eigene Aggregates schreiben
CREATE AGGREGATE name ( [ argmode ] [ argname ]
arg_data_type [ , ... ] ) (
SFUNC = sfunc, STYPE = state_data_type
[ , SSPACE = state_data_size ]
[ , FINALFUNC = ffunc ] [ , FINALFUNC_EXTRA ]
[ , INITCOND = initial_condition ]
[ , MSFUNC = msfunc ] [ , MINVFUNC = minvfunc ]
[ , MSTYPE = mstate_data_type ]
[ , MSSPACE = mstate_data_size ]
[ , MFINALFUNC = mffunc ] [ , MFINALFUNC_EXTRA ]
[ , MINITCOND = minitial_condition ]
[ , SORTOP = sort_operator ]
)
Hans-Jürgen Schönig
www.postgresql-support.de](https://image.slidesharecdn.com/deaggregationhowto-150713125704-lva1-app6892/85/PostgreSQL-Eigene-Aggregate-schreiben-7-320.jpg)





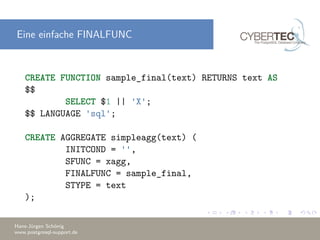
















![Die Syntax für Ordered Sets
CREATE AGGREGATE name ( [ [ argmode ] [ argname ]
arg_data_type [ , ... ] ]
ORDER BY [ argmode ] [ argname ]
arg_data_type [ , ... ] ) (
SFUNC = sfunc,
STYPE = state_data_type
[ , SSPACE = state_data_size ]
[ , FINALFUNC = ffunc ]
[ , FINALFUNC_EXTRA ]
[ , INITCOND = initial_condition ]
[ , HYPOTHETICAL ]
)
Hans-Jürgen Schönig
www.postgresql-support.de](https://image.slidesharecdn.com/deaggregationhowto-150713125704-lva1-app6892/85/PostgreSQL-Eigene-Aggregate-schreiben-30-320.jpg)