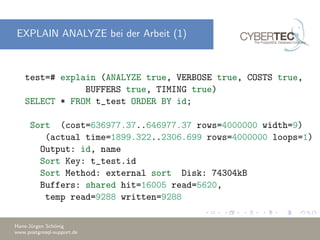
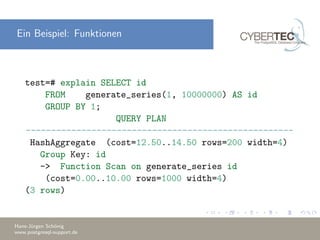
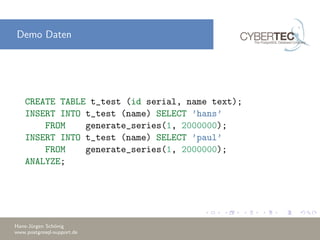
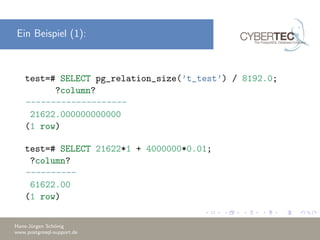
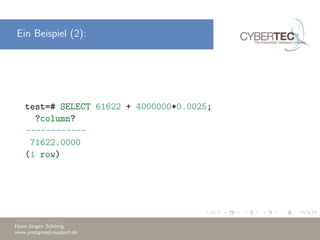
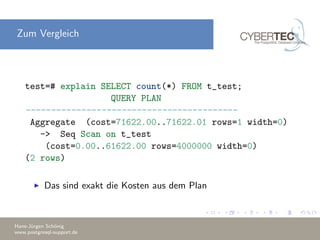
Das Dokument erklärt die Verwendung des 'EXPLAIN' Befehls in PostgreSQL, um den Ausführungsplan von Abfragen zu analysieren und Optimierungsstrategien zu verstehen. Es beschreibt die Kostenparameter, wie Sequential Page Cost und CPU Cost, die zur Bewertung der Abfrageleistung herangezogen werden, und diskutiert die Bedeutung von 'EXPLAIN ANALYZE' zur Identifizierung von Leistungsengpässen. Außerdem werden Beispiele für häufige Probleme und deren Lösungen gegeben, um bessere Abfragepläne zu erstellen.












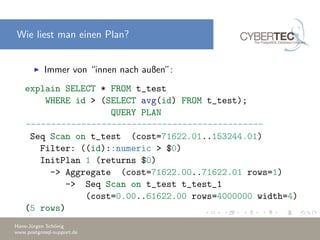


![EXPLAIN ANALYZE (2)
Command: EXPLAIN
Description: show the execution plan of a statement
Syntax:
EXPLAIN [ ( option [, ...] ) ] statement
EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
where option can be one of:
ANALYZE [ boolean ] VERBOSE [ boolean ]
COSTS [ boolean ] BUFFERS [ boolean ]
TIMING [ boolean ]
FORMAT { TEXT | XML | JSON | YAML }
Hans-J¨urgen Sch¨onig
www.postgresql-support.de](https://image.slidesharecdn.com/explainexplain-151206173909-lva1-app6891/85/Explain-explain-21-320.jpg)