






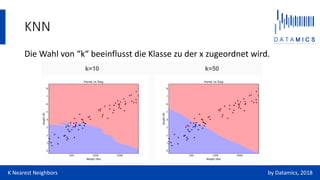




K-nearest neighbors (KNN) ist ein einfacher Klassifizierungsalgorithmus, der die Klassifikation eines neuen Datenpunkts anhand der Mehrheit der k nächsten Nachbarn vornimmt. Der Algorithmus hat Vorteile wie Einfachheit und Flexibilität, jedoch auch Nachteile wie hohe Vorhersagekosten bei großen Datensätzen und Schwierigkeiten mit hochdimensionalen Daten. In Data-Science-Interviews wird oft das Klassifizieren anonymisierter Daten mit KNN als Beispiel verwendet.

















