

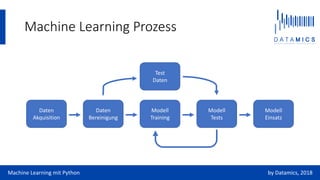















Das Dokument bietet eine Einführung in Machine Learning mit Python unter Verwendung des scikit-learn Pakets, das grundlegende Algorithmen und den typischen Prozess von der Datenakquisition über Modelltraining bis hin zu Modelltests und -einsatz behandelt. Es werden auch spezifische Methoden für überwachtes und unbeaufsichtigtes Lernen erläutert, einschließlich der Verwendung von Modelfit- und Vorhersagemethoden. Der Kurs umfasst zahlreiche Übungen zur Vertiefung des Verständnisses und zur praktischen Anwendung der Konzepte.

















