







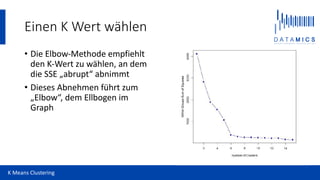


Das Dokument bietet eine Einführung in das k-means Clustering, einem unüberwachten Lernalgorithmus, der darauf abzielt, Daten in ähnliche Cluster zu gruppieren. Der Algorithmus funktioniert durch die Wahl einer Clusteranzahl 'k', zufällige Zuordnung von Beobachtungen und wiederholte Berechnung von Cluster-Mittelpunkten, bis sich die Cluster nicht mehr verändern. Anwendungsbeispiele mit Python zeigen, wie echte Daten, wie Universitäten basierend auf ihren Eigenschaften, analysiert werden können.

















