Als PDF, PPTX herunterladen




























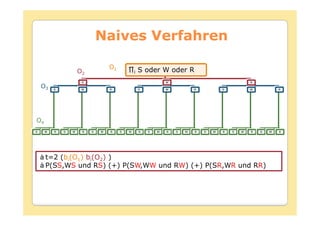
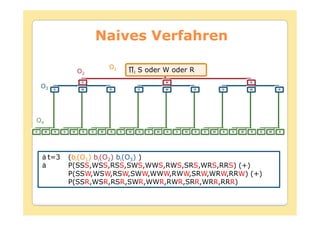
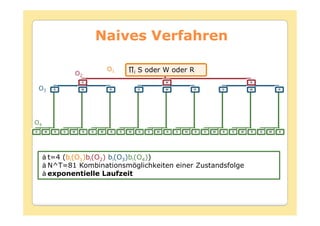







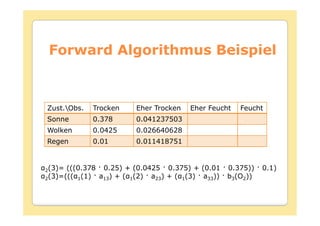



![Forward Algorithmus
Initialisierung :
1 i bi(O1
Induktion :
N
t+1(j) = [ ∑ t(i) aij ] bj(Ot+1)
i =1
Terminierung :
N
P(O| ) =∑ T(i)
i=1](https://image.slidesharecdn.com/hmm-091119042903-phpapp02/85/Hidden-Markov-Modelle-50-320.jpg)



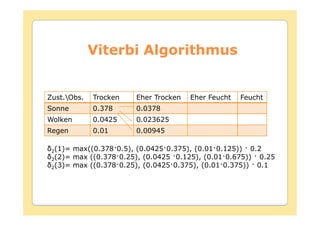

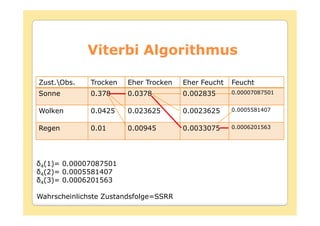

![Viterbi Algorithmus
Initialisierung :
1 ibi(O1
1(i) =0
Rekursion :
t(j) = max [ t-1(i)aij]bj(Ot
t(j) = argmax [ t-1(i)aij]
Terminierung :
P* = max [ t(i)]
qT* = argmax [ t(i)]
Pfad (Zustandssequenz) Backtracking :
qt* = t+1(q*t+1) t = T-1,T-2,…,1](https://image.slidesharecdn.com/hmm-091119042903-phpapp02/85/Hidden-Markov-Modelle-58-320.jpg)


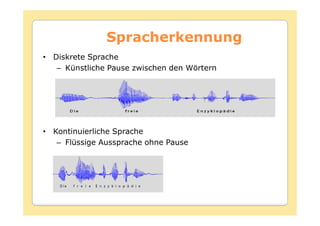






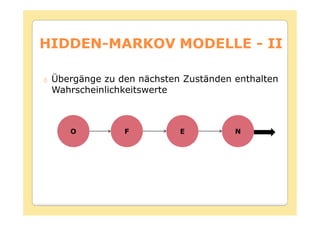
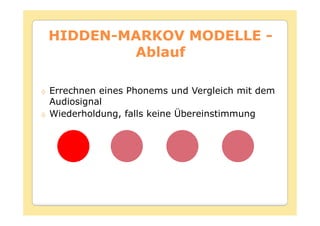
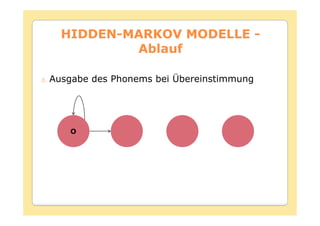
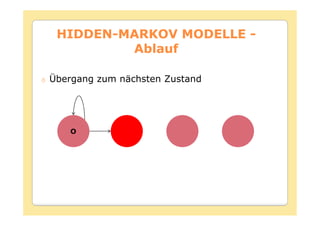
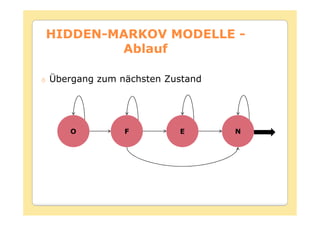















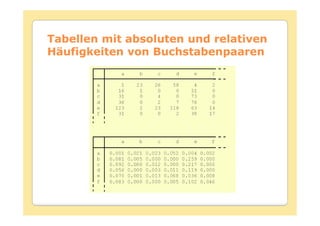
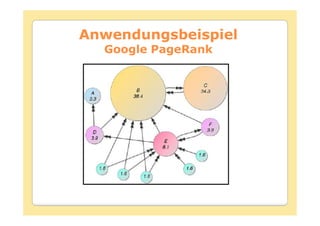
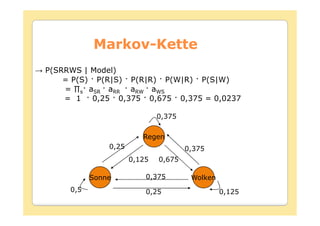
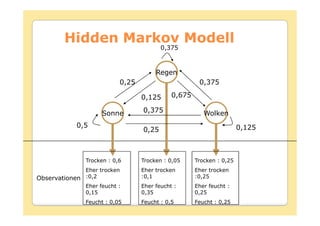
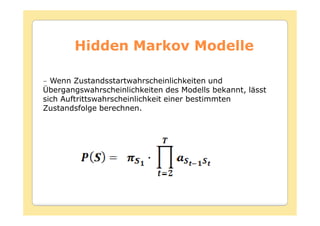
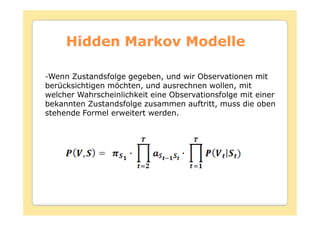
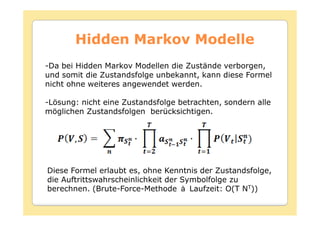
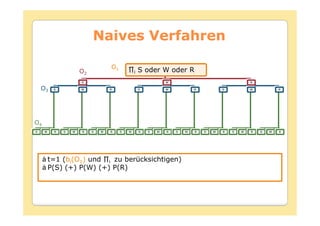
Das Dokument behandelt die Theorie und Anwendungen von Hidden Markov Modellen (HMM), einschließlich ihrer Geschichte, Wahrscheinlichkeitsgrundlagen und Algorithmen wie dem Forward- und Viterbi-Algorithmus, die für die Spracherkennung verwendet werden. Es werden statistische Charakterisierungen, Beispiele für praktische Anwendungen in verschiedenen Bereichen wie Biologie, Physik und Informatik sowie spezifische Problematiken und Lösungsansätze bei der Berechnung von Wahrscheinlichkeiten und Zuständen dargestellt. Insbesondere wird die effiziente Berechnung der Auftrittswahrscheinlichkeiten und die Dekodierung verborgener Zustandsfolgen in HMM erläutert.






















