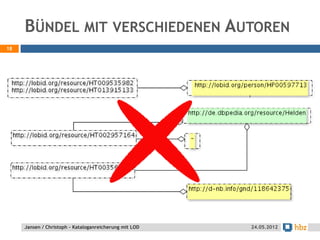
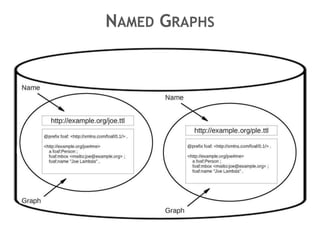
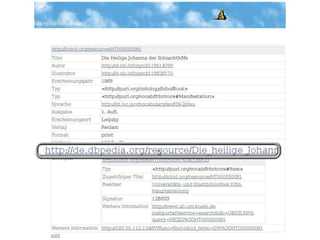
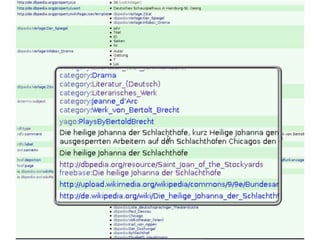
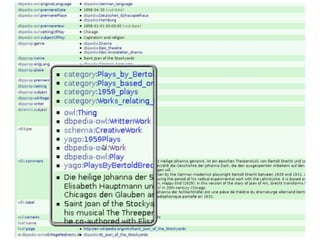
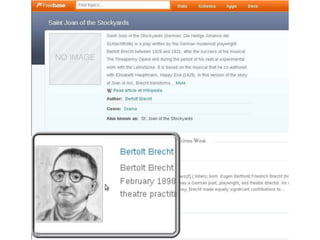
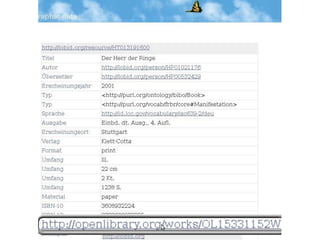
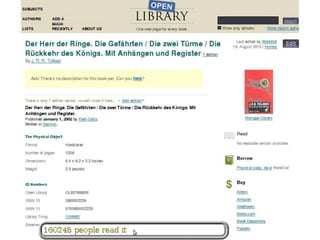
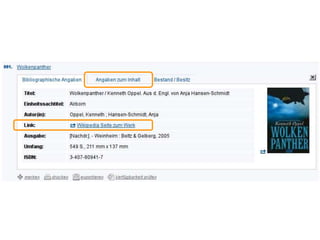
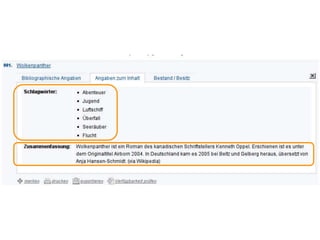
Der Vortrag von Heiko Jansen und Pascal Christoph behandelt die dynamische Kataloganreicherung mittels Linked Open Data (LOD), wobei verschiedene Methoden zur Ergänzung von Datensätzen vorgestellt werden. Es wird eine Infrastruktur zur Aggregation von LOD aus verteilten Quellen skizziert sowie die Herausforderungen und Erfolge bei der Integration dieser Daten in lokale Bibliothekssysteme thematisiert. Abschließend werden mögliche Weiterentwicklungen und Anwendungsbeispiele diskutiert.