Downloaden Sie, um offline zu lesen









![Noch mehr Metadaten
● Typische Metadaten, die für die Suche interessant sind:
● Alle „sinntragenden“ Wörter aus dem Text des
Dokuments → Namen, Tätigkeiten,
Eigenschaften, Zahlen, uvm.
– Aber: Keine Stoppwörter wie → der, die, das, eine,
ein, und, doch, oder, an, von, in […]
– Typische Stoppwortliste (DE): ~1000 Wörter
● Und beliebig viel mehr:
– Geodaten, Zeitstempel & Zeitreihen, Autoren,
Schlagworte (tags), Dokumentlänge, Teasertext,
Zusammenfassung, Verweise auf andere Dokumente,
Anzahl der Wörter,](https://image.slidesharecdn.com/dernucleuseinersuchmaschine-101218135922-phpapp02/85/Der-Nucleus-einer-Suchmaschine-10-320.jpg)

![Ein Beispiel zu Veranschaulichung
Wir haben drei Textdateien mit Zitaten:
Text: "Wir wissen, wo du bist. Wir wissen wo du warst. Wir wissen
mehr oder weniger worüber du nachdenkst."
Autor: Eric E. Schmidt
Text: "[…] Man kann ohne Angst vor Übertreibung von einer „Generation Google“ sprechen, deren
Umgang mit Wissen und Information nachhaltig von der Suchmaschine beeinflusst wird. [...]“
Autor: Malte Herwig
Titel: Eliten in einer egalitären Welt
Seiten: 188
Datum: 2005
Text: „[...] Die Erfindung der Buchdruckerkunst macht dem menschlichen Verstande
zwar Ehre, doch verliert sie sehr, wenn man sie mit der Erfindung der Buchstaben
vergleicht. [...]“
Autor: Thomas Hobbes
Titel: Leviathan
Titel (lang): Leviathan (or the Matter, Forme and Power of a Commonwealth
Ecclesiastical and Civil)](https://image.slidesharecdn.com/dernucleuseinersuchmaschine-101218135922-phpapp02/85/Der-Nucleus-einer-Suchmaschine-12-320.jpg)



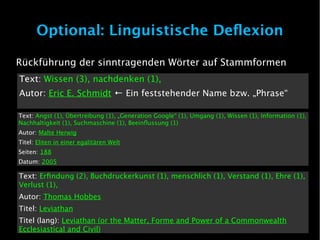
![Indexierung – Stoppwörter entfernen
Wir haben drei Textdateien mit Zitaten
Text: "Wir wissen, wo du bist. Wir wissen wo du warst. Wir wissen mehr oder weniger
worüber du nachdenkst."
Autor: Eric E. Schmidt ← Ein feststehender Name bzw. eine „Phrase“
Text: "[…] Man kann ohne Angst vor Übertreibung von einer „Generation Google“ sprechen, deren
Umgang mit Wissen und Information nachhaltig von der Suchmaschine beeinflusst wird. [...]“
Autor: Malte Herwig
Titel: Eliten in einer egalitären Welt
Seiten: 188
Datum: 2005
Text: „[...] Die Erfindung der Buchdruckerkunst macht dem menschlichen Verstande
zwar Ehre, doch verliert sie sehr, wenn man sie mit der Erfindung der Buchstaben
vergleicht. [...]“
Autor: Thomas Hobbes
Titel: Leviathan
Titel (lang): Leviathan (or the Matter, Forme and Power of a Commonwealth
Ecclesiastical and Civil)](https://image.slidesharecdn.com/dernucleuseinersuchmaschine-101218135922-phpapp02/85/Der-Nucleus-einer-Suchmaschine-16-320.jpg)




Das Dokument behandelt die Funktionsweise von suchmaschinen und ihren Indexierungsprozessen. Es erklärt, was Suchmaschinen leisten, welche Daten sie speichern und welche Kriterien bei der spätere Abfrage eine Rolle spielen, darunter die Verwendung von Metadaten und das Entfernen von Stoppwörtern. Zudem wird der Unterschied zwischen Suchmaschinen und Datenbanken sowie die Bedeutung eines invertierten Indexes zur effizienten Suchabfrage hervorgehoben.



































