Als PDF, PPTX herunterladen



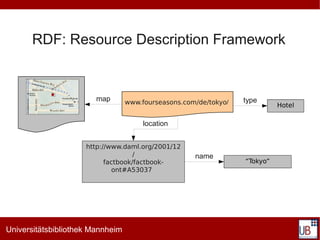
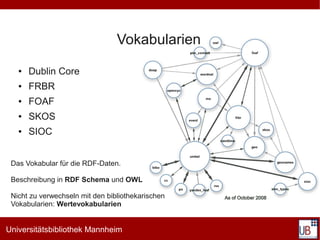




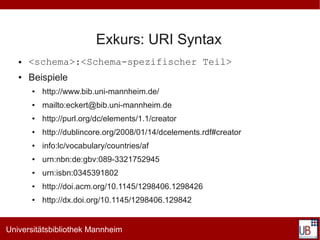







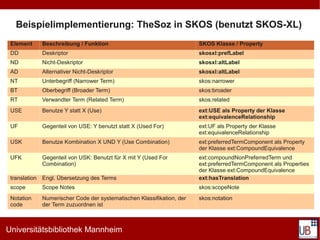










Das Dokument behandelt die Grundlagen des Semantic Web, insbesondere im Kontext von SKOS (Simple Knowledge Organization System) und Linked Data. Es werden die Notwendigkeit standardisierter Syntaxen, Vokabularien und Ressourcen für die Beschreibung von Metadaten hervorgehoben, sowie die Rolle von URIs bei der eindeutigen Identifikation von Ressourcen und deren Aggregation in Linked Data. Zusätzlich werden praktische Beispiele und Implementierungen von thesaurischen Systemen und deren Verknüpfungen mit offenen Datenquellen präsentiert.





































