11-mal heruntergeladen




![5
Zur Anzeige wird der QuickTime™
Dekompressor „“
benötigt.
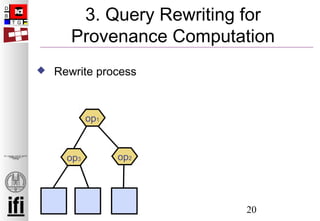
The problem of computing this type of
provenance has been solved before
See e.g. [Cui, Widom ICDE ‘00]
but...
Non-relational representation of provenance
data
Separation of provenance and “normal” data
Non-relational computation of provenance
data
1. Introduction](https://image.slidesharecdn.com/2009icdeperm-140625071709-phpapp01/85/ICDE-2009-Perm-Processing-Provenance-and-Data-on-the-same-Data-Model-through-Query-Rewriting-5-320.jpg)

































Das Dokument präsentiert das Konzept von 'perm', einem Provenienzmanagementsystem, das die Provenienz von relationalen Daten durch Abfrageumformung verarbeitet. Es beschreibt, wie Provenienz in ein relationales Modell integriert werden kann, sodass sie effizient gespeichert und abgefragt werden kann, sowie die Implementierung von perm in PostgreSQL. Die Ergebnisse zeigen, dass dieses System umfangreiche SQL-Funktionalität für Provenzdaten bietet und zukünftige Arbeiten zur Verbesserung der Effizienz der Provenienzberechnung skizziert.





![[ICDE 2014] Incremental Cluster Evolution Tracking from Highly Dynamic Networ...](https://cdn.slidesharecdn.com/ss_thumbnails/icde2014-140416141240-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)

















