Das Dokument beschreibt das Forschungsprojekt Qurator der Staatsbibliothek zu Berlin, das sich mit der Anwendung von Künstlicher Intelligenz zur Verbesserung der Digitalisierung und Analyse von kulturellem Erbe beschäftigt. Es werden verschiedene Technologien wie OCR-Qualitätsverbesserung, Layouterkennung und Named Entity Recognition vorgestellt, die aus einem interdisziplinären Ansatz von verschiedenen Projektpartnern resultieren. Ziel ist es, digitale Inhalte besser zugänglich zu machen und innovative Prozesse in der Kuratierung von Informationen zu fördern.











![Ein moderner OCR-Workflow
Binarisierung
Zeilen-
segmentierung
Zeilen-OCR Postcorrection
20
–
rath mit einer Pœna fiſcali angeſehen worden,
und ſolche durch des Hon. Graffen von
Königsfeld Vor–
ſpruch, nur aus Gnaden nachgelaſſen erhalten.
Sondern man hat auich dieſen 4. Wochen lang
alle Abend bey der Jnquißtin gantz allein
gelaſſen
Binnen welcher gantzer Zeit der Schreiber
Bredekam beſtändig bey Jhme geweſen, und
ſich in
der am 13ten Octobt. a.c. in Judicio gegen
ſeinen geweſenen Hrn. introducirter Appellation
deſſen Bey-
raths bedienet hat;
33) Dabenehenſt iſt der Schreiber binnen dieſer
gantzen Zeit auf freyem Fuß geblieben, und
hat nicht nur durch ſeinen Conlulenten, ſondern
auch, weilen del lnquilti ſelbſten in Jhtem
Gefängnüß
ſo viele Freyheit gelaſſen worden, daß ſie
frembden Beſuch von Jhren Anberwandten
ohngehindert en–
pfangen können, durch andere Perſonen ſich
mit ihr über alles, Was Er oder ſie dereinſten zu
ſagen hat–
ten· vereinigen können, immaſſen der Hofrath
[...]
20
rath mit einer Pœna fiſcali angeſehen worden,
und ſolche durch des Hrn. Graffen von
Königsfeld Vor–
ſpruch, nur aus Gnaden nachgelaſſen erhalten.
Sondern man hat auch dieſen 4. Wochen lang
alle Abend bey der Jnquisitin gantz allein
gelaſſen.
Binnen welcher gantzer Zeit der Schreiber
Bredekaw beſtändig bey Jhme geweſen, und
ſich in
der am 13 ten Octobr. a.c. in Judicio gegen
ſeinen geweſenen Hrn. introducirter Appellation
deſſen Bey-
raths bedienet hat;
33) Dabenebenſt iſt der Schreiber binnen dieſer
gantzen Zeit auf freyem Fuß geblieben, und
hat nicht nur durch ſeinen Conſulenten, ſondern
auch, weilen der Inquiſitin ſelbſten in Jhrem
Gefängnüß
ſo viele Freyheit gelaſſen worden, daß ſie
frembden Beſuch von Jhren Anverwandten
ohngehindert em–
pfangen können, durch andere Perſonen ſich
mit ihr über alles, Was Er oder ſie dereinſten zu
ſagen hat–
ten, vereinigen können, immaſſen der Hofrath
[...]
Acten-mäßiger Verlauff, Des Fameusen
Processus sich verhaltende ... (1749)](https://image.slidesharecdn.com/quratorsbbmetadatenkolloquium-191114174845/85/Kuratieren-mit-kunstlicher-Intelligenz-12-320.jpg)





![Stol, Pomrn. [56000]
Jn unſerem Genoſſenſchaftsregiſter iſt
heute unter Nr. 113 die ,,Landliche
Spar⸗ und Darlehnokaſſe Schmaatz,
eingetragene Genofſenſchaft mit be⸗
ſchränkter Haftpflicht in Schmaatz',
eingetragen worden. Gegenſtand des
Unternehmens iſt die Gewährung von
Darlehen an die Mitglieder für ihren
Geſchäfts⸗ und Wirtſchaftsbetrieb, Er-
leichterung der Geldanlage und Förderung
des Sparſinns, nebenbei gemeinſchaftliche
Beſchaffuag landwirtſchaftlicher Betriebs.
mittel. Die Haftſumme beträgt 20 ,
die Höchſtzahl der Geſchäftsanteile 100.
Vorſtandsmitglieder ſind: der Hofbeſitzer
Albert Timreck als Vorſitzender, der
Lehrer Auguſt Völz und der Hofbeſitzer
Paul Selt, ſämtlich in Schmaatz. Das
Statut iſt vom 25. Juli 192. Das
Geſchäftsjahr lauft vom 1. April bis
31. März. Die Bekanntmachungen er⸗
folgen unter der Firma der Genoſſenſchaft
im Pommerſchen Genoſſenſchaftsblatt, beim
Eingehen dieſes Blattes bis auf weiteres
im Deutſchen Reichsanzeiger. Die
Willenserklärungen des Vorſtands erfolgen
durch zwei Vorſtandsmitglieder. Hie
Zeichnung geſchieht derart, daß die Zeich-
nenden zu der Firma ihre Namensunter⸗
ſchrift beifügen. Die Einficht in die Liſte
der Genoſſen iſt während der Geſchäfts.
ſtunden des Gerichts jedermann geſtattet.
Stolp, den 1. Auguſt 1920. Das
Amtsgericht.
¹ Digitalisat aus dem
Reichsanzeiger August
1920 (via UB Mannheim)
OCR-Beispiel
Zeitung¹](https://image.slidesharecdn.com/quratorsbbmetadatenkolloquium-191114174845/85/Kuratieren-mit-kunstlicher-Intelligenz-19-320.jpg)


















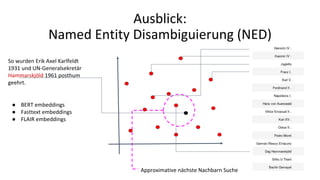
![NER in OCR- Volltexten
Vorwort von Alexander v. Humboldt zu den "Erinnerungen der Reise nach Indien von S. K. H. dem Prinzen
Waldemar von Preussen" : [Berlin, den 18 December 1854]](https://image.slidesharecdn.com/quratorsbbmetadatenkolloquium-191114174845/85/Kuratieren-mit-kunstlicher-Intelligenz-43-320.jpg)

![Feedforward - Netze
[1] Modifiziert aus: Rumelhart et al., Learning representations by back-propagating errors, Nature 1986.
[1]
Rekurrente - Netze
[1]](https://image.slidesharecdn.com/quratorsbbmetadatenkolloquium-191114174845/85/Kuratieren-mit-kunstlicher-Intelligenz-45-320.jpg)
![BERT - Architektur
[1]
[1] Devlin et al., BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, arXiv:1810.04805 2018](https://image.slidesharecdn.com/quratorsbbmetadatenkolloquium-191114174845/85/Kuratieren-mit-kunstlicher-Intelligenz-46-320.jpg)
![Transformer
Encoder [1]
[1] Vaswani et al., Attention Is All You Need, NIPS 2017](https://image.slidesharecdn.com/quratorsbbmetadatenkolloquium-191114174845/85/Kuratieren-mit-kunstlicher-Intelligenz-47-320.jpg)
![BERT - Vortraining
• [CLS] Der Strom, der nachts, wenn die Produktion [MASK] der
Bettfedernfabrik ruhte, nicht gebraucht wurde, wurde für die Kühl- und
Gefrieranlagen genutzt. [SEP] Ab 1951 nutzte man eine Spezialapparatur,
mit der frische Fische sofort [MASK] dem Fang eingefroren werden
konnten. [SEP]
Aufeinanderfolgend: Ja
• [CLS] Rollins Eltern stammen [MASK] den karibischen Jungferninseln. [SEP]
Kern der Sendung sind [MASK] Lach- und Sachgeschichten. [SEP]
Aufeinanderfolgend: Nein](https://image.slidesharecdn.com/quratorsbbmetadatenkolloquium-191114174845/85/Kuratieren-mit-kunstlicher-Intelligenz-48-320.jpg)
![BERT - Vortraining
[1] Devlin et al., BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, arXiv:1810.04805 2018
[1]](https://image.slidesharecdn.com/quratorsbbmetadatenkolloquium-191114174845/85/Kuratieren-mit-kunstlicher-Intelligenz-49-320.jpg)

![BERT - NER Training
[1] Devlin et al., BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, arXiv:1810.04805 2018
[1]](https://image.slidesharecdn.com/quratorsbbmetadatenkolloquium-191114174845/85/Kuratieren-mit-kunstlicher-Intelligenz-51-320.jpg)

![[1] Kai Labusch, Clemens Neudecker and David Zellhöfer. BERT for Named Entity Recognition in Contemporary and Historic German, KONVENS 2019
[1]](https://image.slidesharecdn.com/quratorsbbmetadatenkolloquium-191114174845/85/Kuratieren-mit-kunstlicher-Intelligenz-53-320.jpg)