Downloaden Sie, um offline zu lesen



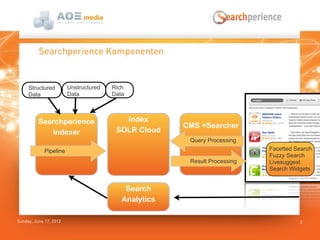

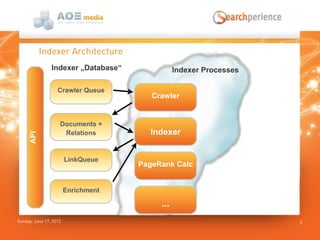
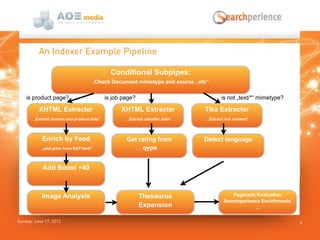





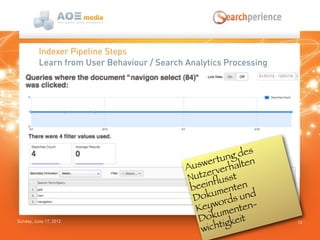

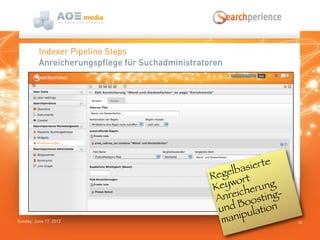
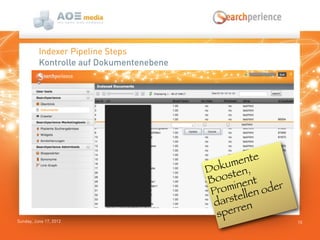




Das Dokument beschreibt die Suchlösung 'Searchperience', die auf Apache Solr basiert und eine Benutzererlebnis-orientierte Suchfunktion für Webseiten und Onlineshops bietet. Es erläutert die Architektur und die verschiedenen Schritte der Indexierungspipeline, die sowohl strukturierte als auch unstrukturierte Daten verarbeitet und Anreicherungen durch Benutzerverhalten und Analytik ermöglicht. Zudem wird darauf hingewiesen, dass Solr allein nicht als vollständige Indexierungspipeline ausreicht, da es keine flexible Kontrolle über die Schritte und die Skalierung bietet.















































