19-mal heruntergeladen





























![Syntax
• Query -> q
• FilterQuery ->fq
• Boolean Operatoren -> OR, AND, NOT, +, -
• Phrasen -> “Harrison Ford”~5
• Wildcard -> fi?m, film*
• Fuzzy -> Hale*0.9
• Boost -> q=star OR trek^4.0
• Range -> preis:[1 TO 10] oder preis:{1 TO 10}](https://image.slidesharecdn.com/jax-2012-apache-solr-als-enterprise-search-plattform-120422065615-phpapp02/85/Jax-2012-Apache-Solr-as-Enterprise-Search-Platform-39-320.jpg)




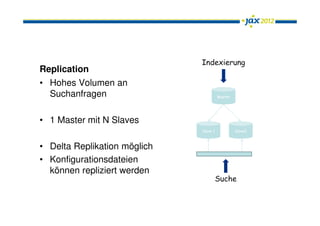
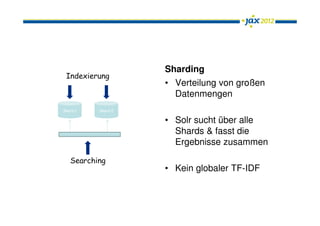
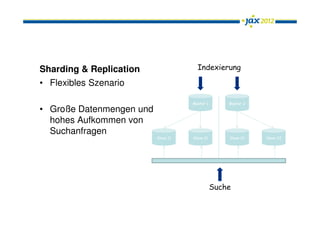
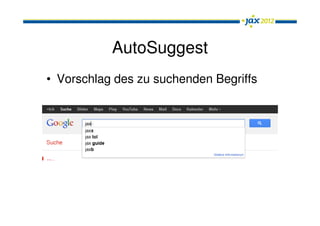
Das Dokument behandelt Apache Solr als eine leistungsfähige Enterprise-Search-Plattform, die Herausforderungen wie Datenquellenanbindung, Mehrsprachigkeit und Relevanzbewertung adressiert. Es wird die Architektur von Solr, einschließlich seiner Konfigurationsoptionen und integrierten Komponenten, sowie die Funktionen wie Autosuggest und Facetten erläutert. Zudem werden Ausblicke auf zukünftige Entwicklungen, wie Solr Cloud und Near Real Time Search, gegeben.
















































