Als PDF, PPTX herunterladen




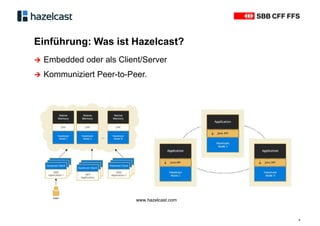


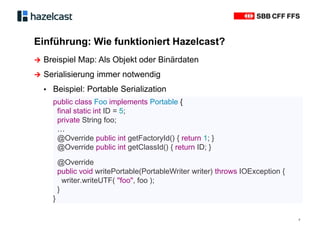
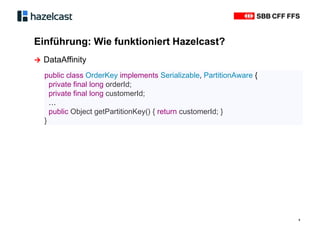

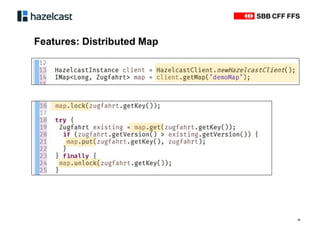





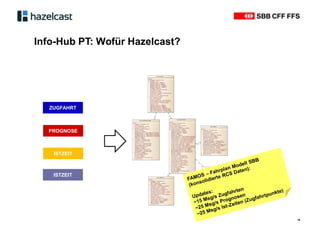
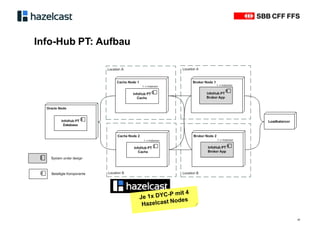


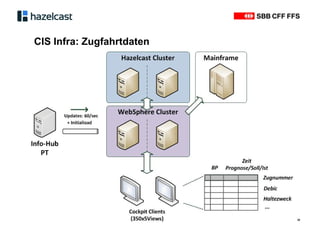

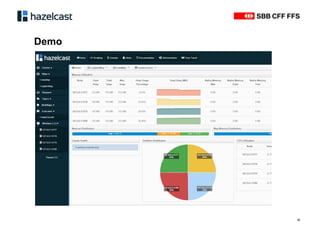




Das Dokument beschreibt Hazelcast, eine Open-Source-In-Memory-Daten-Grid-Lösung zur Verarbeitung verteilter Datenstrukturen und Berechnungen. Es erläutert die Funktionen wie verteilte Datenstrukturen, Abfragen und parallele Verarbeitung sowie Anwendungsbeispiele bei SBB und InfoHub-PT. Zudem werden technische Details zur Partitionierung und Serialisierung präsentiert, um die Funktionsweise und Integration in bestehende Systeme zu verdeutlichen.


































