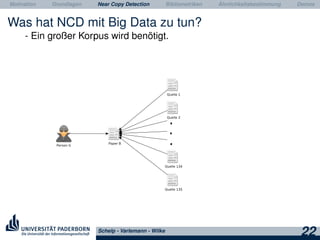
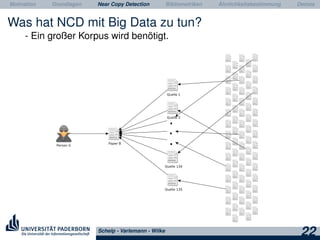
Das Dokument behandelt Grundlagen und Techniken der Near Copy Detection (NCD) zur Erkennung von Ähnlichkeiten zwischen wissenschaftlichen Publikationen und Plagiaten. Es beschreibt die Herausforderungen bei der Verarbeitung großer Datenmengen, die notwendigen Technologien wie Hadoop und HBase sowie den Einsatz von Bibliometriken zur Verbesserung der Analyse und den Umgang mit den gewonnenen Daten. Zudem werden verschiedene Ansätze zur Textübernahme und die Differenzierung zwischen Plagiaterkennung und NCD erläutert.










































![Motivation Grundlagen Near Copy Detection Bibliometriken Ähnlichkeitsbestimmung Demos
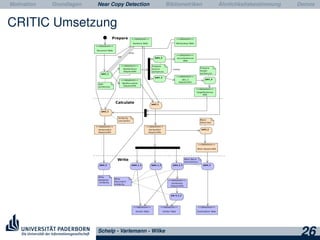
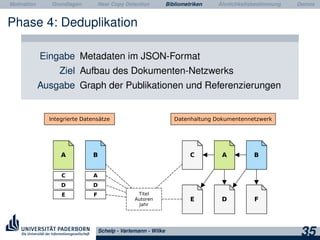
Phase 2: Extraktion
Eingabe Datensätze als Volltexte und PDF
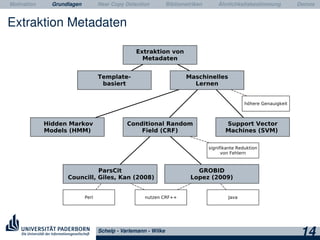
Ziel Extraktion von Metadaten
Berechnung Software: ParsCit, GROBID
Ausgabe Metadaten in 3 XML-Formaten
Auszug: GROBID Header
<title level="a" type="main">PLME as a Cognitive Tool for Knowledge Achievement and Informal Learning
</title> [...]
<author>
<persName>
<forename type="first">Johannes</forename>
<surname>Magenheim</surname>
</persName>
<affiliation>
<orgName type="institution">University of Paderborn</orgName>
<address><country key="DE">Germany</country></address>
</affiliation>
</author>
Schelp - Varlemann - Wilke
30](https://image.slidesharecdn.com/folien-130628075639-phpapp01/85/INSPIRE-Insight-to-Scientific-Publications-and-References-50-320.jpg)






![Motivation Grundlagen Near Copy Detection Bibliometriken Ähnlichkeitsbestimmung Demos
Bibliometrie: Distanz von Zitationen
In-text Citation Distance Analysis (ICDA)“ Gipp, Beel & Hentschel (2009)
Citation Proximity Analysis (CPA) Gipp & Beel (2009)
Distanz-Klasse Gewichtung
Gleiches Dokument 1
Gleicher Abschnitt 2
Gleicher Absatz 3
Gleicher Satz 4
Gleiche Markierung [1,2] 5
Schelp - Varlemann - Wilke
38](https://image.slidesharecdn.com/folien-130628075639-phpapp01/85/INSPIRE-Insight-to-Scientific-Publications-and-References-58-320.jpg)













































