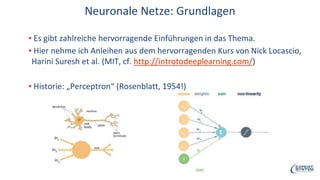
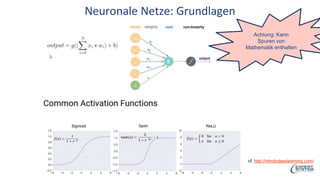
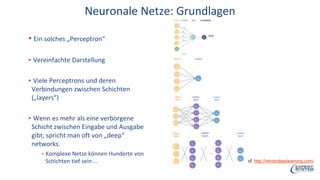
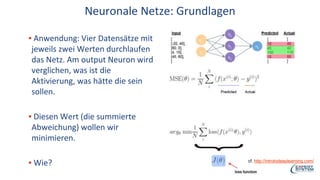
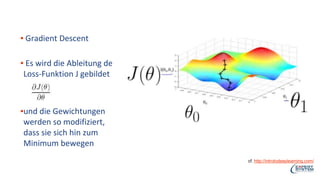
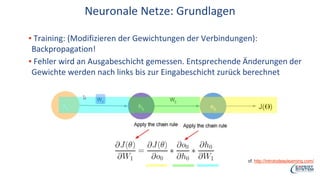
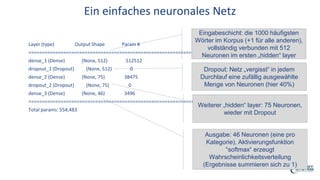
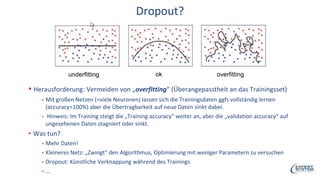
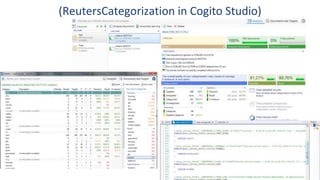
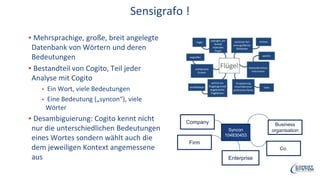
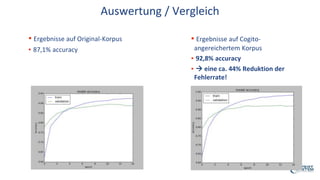
Das Webinar von Expert System am 29. Juni 2017 thematisierte 'Deep Learning' und dessen Anwendungsmöglichkeiten in verschiedenen Branchen mittels der Cognitive-Computing-Technologie Cogito. Es wurden grundlegende Konzepte, wie neuronale Netze und maschinelles Lernen, sowie konkrete Anwendungsbeispiele, die Erfolge in der Ziffernerkennung und Dokumentenkategorisierung illustrieren, präsentiert. Zudem wurde auf die Herausforderungen wie Overfitting und die Integration zusätzlicher Wissensressourcen hingewiesen, um die Genauigkeit von Modellen zu erhöhen.