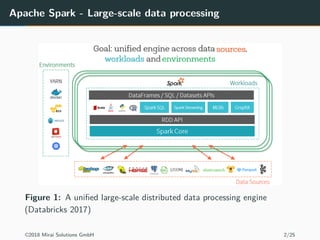
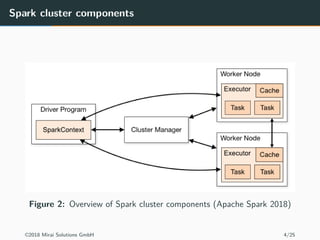
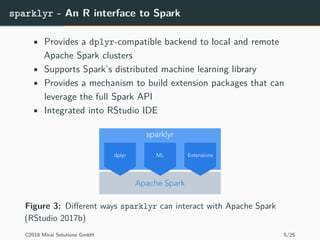
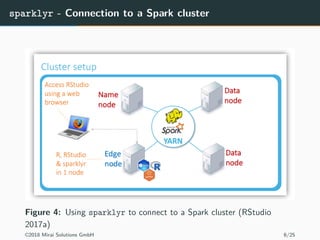
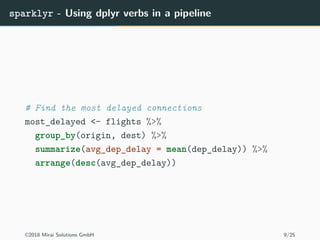
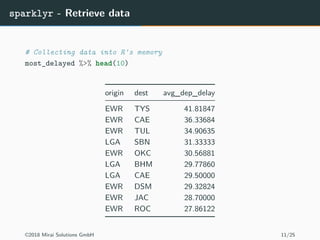
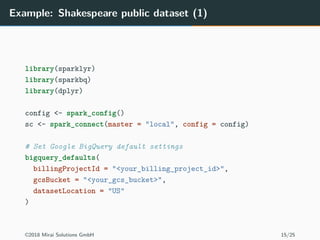
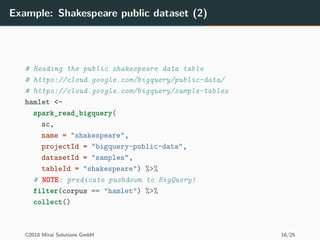
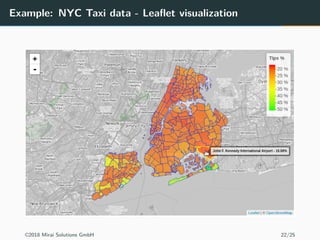
The document discusses the use of Apache Spark and the sparklyr package in R for large-scale data processing and analytics. It explains how sparklyr connects R to Spark clusters, allowing users to perform data manipulation and analysis using dplyr syntax while leveraging Spark's distributed computing capabilities. Additionally, it highlights examples of using sparklyr with Google BigQuery and NYC taxi datasets, emphasizing the benefits of integrating Spark with R for big data analytics.




![sparklyr - Connecting to Spark and loading data
library(sparklyr)
library(dplyr)
library(nycflights13)
sc <- spark_connect(master = "local")
flights <- copy_to(sc, flights, "flights")
src_tbls(sc)
[1] "flights"
Figure 5: Spark integration in the RStudio IDE
©2018 Mirai Solutions GmbH 8/25](https://image.slidesharecdn.com/sparklyr-20180108-180109083733/85/Big-Data-Analytics-in-R-using-sparklyr-8-320.jpg)


































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)










