CART Classification and Regression Trees Experienced User Guide
•Als PPT, PDF herunterladen•
3 gefällt mir•4,791 views

A guide to using CART Classification and Regression Trees for the experienced data miner or data scientist.

Empfohlen
Empfohlen
Weitere ähnliche Inhalte
Was ist angesagt?
Was ist angesagt? (20)
Andere mochten auch
Ähnlich wie CART Classification and Regression Trees Experienced User Guide
Ähnlich wie CART Classification and Regression Trees Experienced User Guide (20)
Mehr von Salford Systems
Mehr von Salford Systems (20)
Kürzlich hochgeladen
Kürzlich hochgeladen (20)
CART Classification and Regression Trees Experienced User Guide
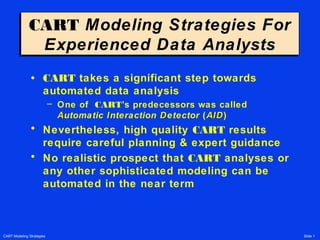
- 1. CART Modeling Strategies Slide 1 CART Modeling Strategies For Experienced Data Analysts CART Modeling Strategies For Experienced Data Analysts • CART takes a significant step towards automated data analysis – One of CART’s predecessors was called AAutomatic IInteraction DDetector (AIDAID) • Nevertheless, high quality CART results require careful planning & expert guidance • No realistic prospect that CART analyses or any other sophisticated modeling can be automated in the near term
- 2. CART Modeling Strategies Slide 2 All Data analysis, regardless of methods employed, have certain prerequisites All Data analysis, regardless of methods employed, have certain prerequisites • Complete understanding of the data available – Correct variable definitions – Sample sources and relationship to study population – Review of conventional summary statistics, percentiles – Standard reports that would be generated in the process of data integrity checks – Calculations verified: check that totals can be generated from components – Consistency checks: related fields do not conflict
- 3. CART Modeling Strategies Slide 3 Careful data preparationCareful data preparation • CART is far better suited to dirty data analysis than conventional statistical modeling or NN tools – capable of dealing with missing values, outliers • Nevertheless, considerable benefits to proper data preparation – the better the data the better a model can perform • Includes – correct identification of missing value codes (998 valid or .) – uniform data handling when records come from different entities (branches, regions, behavioral groups) – if responder data is processed separately from and differently than non-responder data, completely erroneous results will be produced
- 4. CART Modeling Strategies Slide 4 Some core preparatory stepsSome core preparatory steps • Identify illegal variables to be excluded from all models – ID variables – post event variables – variables unlikely to be available in future, or against which CART model is intended to compete (eg Bankruptcy scores) – variables disallowed by regulators (banking, insurance) – variables derived in part from dependent variables, or generated from target variable behavior – variables too closely connected to target for any reason
- 5. CART Modeling Strategies Slide 5 Exploratory Data Analysis with CART: Pre-modeling Exploratory Data Analysis with CART: Pre-modeling • Run a single split tree and report all competitors – ranks ability of all variables to separate target variable into homogeneous groups – command settings LIMIT DEPTH=1 ERROR EXPLORE BOPTIONS COMPETITORS=large number • Run limited depth trees for target using one predictor at a time (again exploratory--non-tested trees) – LIMIT DEPTH=2 (up to 4 nodes) or LIMIT DEPTH=3 (up to 8 nodes) (actual number depends on redundant node pruning) – provides optimal binning of variables – binned versions could be used in parametric models
- 6. CART Modeling Strategies Slide 6 The CART Non-linear Correlation Matrix The CART Non-linear Correlation Matrix • Run CART models using every pair of legal variables – should be unlimited depth – could be tested or exploratory – will detect non-linear dependencies • Results will be asymmetric – results can be used to fill out a correlation matrix • Alternate Procedure – run simple regressions using all pairs of variables – use CART to predict residuals – correlation determined by both linear and CART components
- 7. CART Modeling Strategies Slide 7 Example Pearson and CART correlation Matrices Example Pearson and CART correlation Matrices • From Kerry
- 8. CART Modeling Strategies Slide 8 CART Affiliation MatricesCART Affiliation Matrices • Select a group of interesting variables • Let each variable in turn be the target variable, all others in group are predictors • Grow standard trees (not depth limited) with test procedure to prune • Each column in matrix is a target variable • Rows are filled with importance scores (scaled to 0,1) • Provides a picture of variable interdependencies • Can highlight surprise relationships between predictors – can help in detecting data errors – when affiliations stringer or weaker than expected
- 9. CART Modeling Strategies Slide 9 Detection of multivariate outliers Detection of multivariate outliers • Grow CART tree for every variable as predicted by a trimmed down variable list • Predict each variable in turn from all other variables • Restrict trees to moderate to large terminal nodes – use ATOM or MINCHILD controls • For regression: measure deviation of each data point from predicted • For classification: check if class value of data point is rare in predicted terminal node • Use results to investigate unusual observations
- 10. CART Modeling Strategies Slide 10 Once data QC is complete serious CART modeling can begin Once data QC is complete serious CART modeling can begin • Need to understand nature of problem: – what would be the appropriate statistical models to use for problem at hand – e.g. is problem a simple binary outcome (respond or not to a direct mail piece) – alternatively, does it have an inherent time dimension (how long will customer remain customer -- telecommunications churn) latter problem involves censored data – is study of a fundamentally time series or panel data type – then need to allow for lagged variables, etc.
- 11. CART Modeling Strategies Slide 11 CART cannot protect you from using an improper analysis strategy CART cannot protect you from using an improper analysis strategy • CART will help you execute your analysis strategy more quickly and often more accurately • If the modeling strategy you have selected will produce biased results CART may just exacerbate the problem • A definitive modeling approach is not required, but a defensible approach is
- 12. CART Modeling Strategies Slide 12 Example: Targeting model for a catalog to maximize profit Example: Targeting model for a catalog to maximize profit • Sensible to model in stages – 1) yes/no response model: use classification tree – 2) Dollar volume of order for those who do respond modeled conditional on response=yes modeled just on subset of responders regression tree plausible or classification tree on binned order amounts – Final model could be an expected profit model prob(respond)*Expected(Revenue| Respond) model could be all CART, all logit, or a mixture such models discussed later
- 13. CART Modeling Strategies Slide 13 Modeling strategy will also dictate test strategy Modeling strategy will also dictate test strategy • Suppose we are tracking purchase behavior over time • Data organized as one record per purchase opportunity • The unit of observation will be a complete case history – ideally will want to assign some complete case histories to training data – other entire case histories to test data – important not to allow random assignment between train and test on a record by record basis – might want to hold back some records from longer case histories as an additional source of test data
- 14. CART Modeling Strategies Slide 14 Initial CART analyses are strictly exploratory Initial CART analyses are strictly exploratory • Intended to reveal summary and descriptive information about the data • Omnibus Model: dependent variable(s) fit to virtually all legal variables – Certain obvious exclusions necessary: ID numbers, clones and transforms of the dependent variable as discussed above – Omnibus Model reveals something about the predictability of the dependent variable – recall that largest tree has error no more than twice Bayes rate
- 15. CART Modeling Strategies Slide 15 Determine Splitting Rule to Use Determine Splitting Rule to Use • Gini, Twoing, power modified Twoing for classification – possibly ordered twoing • Least squares (LS) or Least Absolute Deviation (LAD) for regression • Best splitting rule can be selected very early in project and typically does not have to be revisited
- 16. CART Modeling Strategies Slide 16 Assess agreement among different test methods Assess agreement among different test methods • If data set is small cross validation is required • In this case rerun trees several times with different starting random number seeds – use to assess stability of size and error rate of best trees • With large data sets reassign cases between learn and test several times – initial check is on error rates and sizes of best trees
- 17. CART Modeling Strategies Slide 17 Run all as batch of startup CART trees Run all as batch of startup CART trees • Using three or four splitting rules, and three or four test sets will get some initial feel for predictability of target variable • Useful to develop some text processing scripts to extract components of the classic CART reports most interesting – tree sequence – misclassification results (which classes are wrong) – prediction success table – importance rankings latter can be aggregated as follows: add up all importance scores for each variable across all trees rescale so that highest score is 100 • LOPTION NOPRINT gives summary tables only – no tree detail; very helpful when trees tend to be
- 18. CART Modeling Strategies Slide 18 Derived variables almost certainly need to be created Derived variables almost certainly need to be created • Almost impossible to develop high performance models without analyst creation of derived variables • Many derived variables are “obvious” to domain specialists – to predict purchase amounts look at customer lifetime totals – possibly aggregate previous purchases into category subtotals – calculate trend; have orders been increasing or decreasing over time? • Consider standard statistical summaries of groups of variables: – mean, standard deviation, min, max, trend
- 19. CART Modeling Strategies Slide 19 Use linear combination splits to search for new derived variables Use linear combination splits to search for new derived variables • Linear combinations found by CART can suggest new derived variables • Recommend that the delete option be set high and that the required sample size also be substantial • LINEAR N=1000 DELETE=.4 – permits linear combination splits only in nodes with more than 1,000 cases – the higher the DELETE parameter the fewer terms in the combination • E.g.
- 20. CART Modeling Strategies Slide 20 Results of first models are used to generate the first cut back list of predictors Results of first models are used to generate the first cut back list of predictors • List is determined through a combination of judgment and perusal of initial CART runs • Purpose is error avoidance, exclusion of nuisance, pernicious and not believable variables • Variables that seem odd in the context, and thus probably should not have predictive value also excluded – Important not to exclude any variables that prior knowledge, conventional wisdom would include – Purpose of this stage is not radical pruning but elimination of valueless variables
- 21. CART Modeling Strategies Slide 21 Can be useful to explore trees for selected predictor variables or other variables of interest Can be useful to explore trees for selected predictor variables or other variables of interest • Can think of the CART tree as an extended non-parametric version of correlation analysis • Results simply reveal what variables are in some way associated in the data • Could construct a table of variables in the columns against variables that predict in the rows
- 22. CART Modeling Strategies Slide 22 Same procedure could be used to impute values for missing data points Same procedure could be used to impute values for missing data points • Actual procedure is complex and will be discussed in another context • Our proposed missing value imputation procedure is iterative • Also might start selecting complexity values that restrain growth of trees to reasonable sizes – A large data set might allow trees with many hundreds of terminal nodes – Yet optimal models might fall into the 20-100 terminal node size
- 23. CART Modeling Strategies Slide 23 Next set of models should explore the impact of alternative splitting and testing rules Next set of models should explore the impact of alternative splitting and testing rules • Useful to look at GINI, TWOING, and TWOING POWER=1 • Useful to compare external test data with cross-validation in smaller data sets • These runs may suggest which splitting rules are most promising for further work • In most problems the default GINI is the best rule to use – Definitively better than ENTROPY, often slightly better than TWOING
- 24. CART Modeling Strategies Slide 24 Impact of alternative splitting and testing rules; continued Impact of alternative splitting and testing rules; continued • In some problems, usually problems with poor predictability, TWOING, POWER=1 works well – e.g. Relative error in best GINI tree is .8 or higher – In these cases, the more balanced splitting strategy seems to yield better trees
- 25. CART Modeling Strategies Slide 25 Also want to compare results from different test procedures Also want to compare results from different test procedures • Compare runs with different subsets of test data randomly chosen from larger data sets • e.g., Create two uniform random variables – %LET TEST20A=urn <0.20 – %LET TEST20B=urn >0.20 – Use TEST20A to pick out test sample in one run and use TEST20B in another run
- 26. CART Modeling Strategies Slide 26 We hope results will be very similar across test sets We hope results will be very similar across test sets • Approximate size of optimal tree • Approximate relative error • Importance ranking of variables — which variables appear near top of list • Reasonable overlap of primary splitters in trees
- 27. CART Modeling Strategies Slide 27 Instability of results across test data sets is a warning sign Instability of results across test data sets is a warning sign • May need to carefully review interdependencies of predictor variables • Results may be due to a set of closely competing predictors with different information content • If so, will want to consider whether one or more of these competitors should be dropped • In this case, a judgment is made concerning variables to exclude from the model • Results may be unstable due to inherent variance of the tree predictor • In this case, will ultimately want to consider aggregation of experts discussed below
- 28. CART Modeling Strategies Slide 28 Experiments with Linear Combination Splits Experiments with Linear Combination Splits • Linear combinations are occasionally instructive • Not useful when many variables are involved • We recommend restriction to 2-variable linear combinations • Helpful if there are strictly positive variables transformed to logs – 2-variable linear combination might reveal a form like c1*log (X1) - c2*log(X2) , which is a ratio of the predictors
- 29. CART Modeling Strategies Slide 29 Reading CART resultsReading CART results • Useful to prepare a series of summary reports after CART runs are done • One report should just include the TREE SEQUENCE – Reveals the size of the optimal tree, relative error rate – Can be used to reject certain runs – too large, too small, too inaccurate • Another report extracts just the split variables: – Contains a listing of the node split variables – Provides an brief outline of how the tree evolved
- 30. CART Modeling Strategies Slide 30 Reports are used to select trees that appear to be promising Reports are used to select trees that appear to be promising • It is possible that no promising trees are found in the early rounds of analysis • Attractive trees need to be printed to facilitate absorption of the implicit model
- 31. CART Modeling Strategies Slide 31 Currently we use allCLEAR to print Currently we use allCLEAR to print • Future CART will include its own pretty print but will still support allCLEAR • We request the “splits” level of detail in the output – Includes split variable, split value, class assignment – Table of class distribution in the node might be too voluminous
- 32. CART Modeling Strategies Slide 32 Trees need to be read for the story they tell and assessed for plausibility Trees need to be read for the story they tell and assessed for plausibility • Particularly at the higher levels of the tree (lower levels might disappear with pruning) • Does the predictive model agree with intuition and prior expectations?
- 33. CART Modeling Strategies Slide 33 When troubling patterns emerge, need to look at the competitors of a node When troubling patterns emerge, need to look at the competitors of a node • Reveals what other variable would be used to split the node if the main splitter were not available • If the competitor is more acceptable than the primary in a node can consider dropping the primary • Method will only work if analyst is willing to exclude the variable from anywhere in the tree • On the basis of these reports and prints can determine candidate second round models
- 34. CART Modeling Strategies Slide 34 Now can move on to tools for model refinement Now can move on to tools for model refinement • Selection of right-sized trees based on judgment • Altering costs of misclassification • Creation of new variables
- 35. CART Modeling Strategies Slide 35 Judgmental Pruning of Trees: A necessary step in model development Judgmental Pruning of Trees: A necessary step in model development • When the CART monograph was published in 1984 the authors suggested that the best tree was the “one-se-rule tree” • This is the smallest tree within one standard error of the minimum cost tree • The reasoning was: all trees within a one standard error band are statistically indistinguishable, and small trees are inherently more comprehensible and preferable
- 36. CART Modeling Strategies Slide 36 Judgmental Pruning of Trees: continued Judgmental Pruning of Trees: continued • The current view of the CART originators is that one should accept the literal minimum cost tree produced by CART • This view is based on a further dozen years of experience which has revealed that the “one- se-rule” may be too conservative • Nonetheless, compelling reasons exist to prefer smaller trees in data-mining investigations
- 37. CART Modeling Strategies Slide 37 In data-mining exercises trees can easily grow to unmanageable depths In data-mining exercises trees can easily grow to unmanageable depths • With the prodigious volumes of warehoused data, greedy analysis tools can develop complex models without restraint • Paradoxically, the large quantities of data can serve to mislead • The problem is similar to that noted by statisticians who first analyzed large national probability sample databases: in regression, t-test, and chi-square tests, almost every estimated coefficient is “significantlysignificantly” different from zero, and every null is rejected • In the tree-growing context, elaborate trees of great depth appear to perform extremely well even on independent hold-out samples
- 38. CART Modeling Strategies Slide 38 A way to “discount” findings based on very large data sets is needed A way to “discount” findings based on very large data sets is needed • The solution in the conventional modeling context has been to adjust the significance level required before placing too much faith in a finding • For example, a t-statistic of 2.2 for a regression coefficient based on 30 degrees of freedom should be considered more compelling than the same t-statistic based on 100,000 degrees of freedom • In the CART context it would be useful to have optimal tree size selection criteria that adapted to the volume of data available
- 39. CART Modeling Strategies Slide 39 Three tools for adjusting an analysis to data richness are available in CART Three tools for adjusting an analysis to data richness are available in CART • The ATOM or minimum node size available for splitting: as the data set size increases, ATOM size can also be increased (perhaps with the log of sample size) – The thinking is: as data sets increase in size, require the amount of data needed to support a split to increase also
- 40. CART Modeling Strategies Slide 40 Three tools for adjusting an analysis; continued Three tools for adjusting an analysis; continued • The minimum child size can also be adjusted. MINCHILD prevents CART from splitting off nodes too small to support separate analysis – For example, we might not want to attempt inferring the probability of prepay in any node containing less than 100 observations – MINCHILD and ATOM are closely related but are different concepts. MINCHILD guarantees that no terminal node will ever be smaller than its predetermined value. ATOM determines the minimum size of a node that is eligible to be split. ATOM must always be at least 2*MINCHILD so that if the smallest node eligible for splitting is split into two equal parts, each part will be at least as large as MINCHILD. • Trees other than the “optimal” tree can be PICKED from the tree sequence
- 41. CART Modeling Strategies Slide 41 The third tool is selection of a tree from the CART sequence The third tool is selection of a tree from the CART sequence • Analyst intervention in tree selection is both desirable and unavoidable • Allows the incorporation of prior knowledge and domain expertise • This type of selection is really just pruning: the analyst decides to prune back further than the CART algorithms recommend • Topic is mentioned briefly in the CART monograph where the authors discuss their decision to eliminate one or two nodes near the bottom of a medical diagnosis tree: – MD’s running the study did not believe that these lower level splits captured the underlying biology • This is similar to a statistician deciding to exclude a borderline significant interaction in a regression
- 42. CART Modeling Strategies Slide 42 In the data-mining context, tree selection can be guided by the relative error plot In the data-mining context, tree selection can be guided by the relative error plot • Each CART run produces a plot of relative error against number of nodes and the relative error is printed on the TREE SEQUENCE report • In data mining these plots have a characteristic shape: steep declines in the relative error as tree initially evolves followed by lengthy flat portions in which further error reduction is extremely small with each additional node • Further, the test data support the hypothesis that many of these error reductions are “statisticallystatistically significantsignificant.” In the CART context the claim is that the more complex larger trees will predict well on fresh data and thus contain valuable information.
- 43. CART Modeling Strategies Slide 43 An analyst could defensibly decide to trade off a large block of nodes for a small “increase” in prediction error An analyst could defensibly decide to trade off a large block of nodes for a small “increase” in prediction error• In one of our CART models the “optimaloptimal” tree had 100 terminal nodes and a relative error of 0.333968 +/- 0.00578 • Yet the sub-tree with 63 terminal nodes only has a relative error of 0.34339, a one-point apparent loss in accuracy. • And 29 terminal nodes yield a relative error of . 38564
- 44. CART Modeling Strategies Slide 44 Final tree selection based on the relative error plot alone Final tree selection based on the relative error plot alone • In many applications it will be difficult to make a final tree selection based on the relative error plot alone • The plot reveals many opportunities for selection, but rarely serves to single out a best tree • In some problems it is possible to find the tree that exhausts all substantial improvements and that separates a steeply sloping section from a flat plateau
- 45. CART Modeling Strategies Slide 45 The next step of tree assessment The next step of tree assessment • Carefully review of a relatively large tree chosen by CART • Examination of a large tree node-by-node will be very instructive • We are assuming that the early splits of the tree have already been examined and found to be convincing and acceptable
- 46. CART Modeling Strategies Slide 46 Review of a relatively large tree chosen by CART Review of a relatively large tree chosen by CART • Purpose of this stage of review is to consider the lower branches: – Do any of the splits appear fortuitous or not particularly believable? – Are the same variables being used repeatedly to minutely subdivide a predictor? – Is it worth pursuing additional refinement of the sub- sample reached at a particular juncture in the tree? – Is there any concern for whatever reason that the splits are not reasonable representations of reality?
- 47. CART Modeling Strategies Slide 47 Additional ConsiderationsAdditional Considerations • The tree that results when questionable or low value sections of the CART optimal tree are dropped should be considered – Unfortunately, there appears to be no substitute for the careful and detailed examination of the CART tree node-by-node – However, the only contribution of judgment here is to eliminate nodes that are thought to be the result of over-fitting
- 48. CART Modeling Strategies Slide 48 Goodness-Of-Fit Measures for Classification Trees in Classic CART Goodness-Of-Fit Measures for Classification Trees in Classic CART • CART classification trees automatically generate diagnostic reports – Relative Error Rate for all trees in pruned sequence – Misclassification Rate By Class for Learn and Test data – Misclassification Table: Actual vs. Predicted Class • CART class probability trees display only the relative error sequence • Although these reports are helpful in sorting out the most promising trees early on in CART analyses, they contain far less information than needed for proper model assessment
- 49. CART Modeling Strategies Slide 49 Characteristics of the CART GINI Measure Characteristics of the CART GINI Measure • Measure is zero whenever a node is pure • Most CART trees are grown and pruned using the Gini measure of within node diversity • Gini is largest when distribution of classes in a node is uniform • CART trees usually grown with priors EQUAL – Essential to encourage promising tree evolution when class distribution is skewed – Practical impact is to make make CART strive for roughly equal accuracy in all classes – Priors DATA and priors MIX rarely work well • CART Gini measure will then be priors adjusted i t pi i ( )= −∑1 2
- 50. CART Modeling Strategies Slide 50 One new measure of tree performance — “Rho-squaredRho-squared” One new measure of tree performance — “Rho-squaredRho-squared” • Although the growing process is improved with equal priors, the practical evaluation of the tree requires using data priors – Actual node distributions, not priors adjusted • We therefore compute unadjusted Gini for entire tree and compare this with the Gini of the root • Provides a measure of the improvement due to splitting
- 51. CART Modeling Strategies Slide 51 “Rho-squaredRho-squared”; continued“Rho-squaredRho-squared”; continued • Formal definition of Rho-squared Rho-squared = 1 - Gini(tree)/Gini(root) – If Gini(tree)=Gini(root) we have no improvement and rho-squared=0 – If Gini(tree)=0, meaning all terminal nodes are perfectly pure, then rho-squared=1 – Thus, rho-squared measures how the gap from Gini(root) to a Gini of 0 is closed by the model • Can be used to compare competing tree models
- 52. CART Modeling Strategies Slide 52 Second new measure compares learn vs. test class distribution in terminal nodes Second new measure compares learn vs. test class distribution in terminal nodes • Every classification tree generates a distribution of the dependent variable in each terminal node • This learn data distribution can be compared with the distribution observed in other data: – The test data used to calibrate relative error rates and select the optimal tree – A test data set independent of both learn and test data used in the tree modeling – Data from other sources that are not necessarily expected to be similar to the tree under study • Might also want to compare the test data with external data
- 53. CART Modeling Strategies Slide 53 Performance comparisons can be summarized in a chi-square statistic Performance comparisons can be summarized in a chi-square statistic – If there are K classes then each terminal node contributes a chi-square statistic with K-1 df – With T terminal nodes the overall statistic for the tree has T*(K-1) degrees of freedom – Can decompose the statistic by node or by class – Useful when the statistic is large to determine source of large deviations Are we fitting badly in a specific subtree? Are the deviations concentrated in one class?
- 54. CART Modeling Strategies Slide 54 Class Probability TreesClass Probability Trees • Technically, project Oracle uses class probability trees for forecasts and simulation • Class probability trees use the same GINI method for growing • Uses GINI for pruning trees as well • Nevertheless, we used classification trees throughout and interpreted the results as class probability trees • Several reasons for this approach – Classification trees produce misclassification reports – Can be guided by variable cost of misclassification – Class probability trees sometimes much smaller than classification trees
- 55. CART Modeling Strategies Slide 55 Class Probability Trees; continued Class Probability Trees; continued • Main problem with class probability trees – Pruning based on equal priors – Want pruning based on data priors, not yet possible in CART • Hence, use of classification tree to allow judgmental pruning • Nonetheless, looking at class probability tree sizes can be used to bound right sized tree • Would be desirable to modify CAR to allow different priors in growing and pruning