
Empfohlen
Empfohlen
Weitere ähnliche Inhalte
Ähnlich wie Big Data_Architecture.pptx
Ähnlich wie Big Data_Architecture.pptx (20)
Kürzlich hochgeladen
Kürzlich hochgeladen (20)
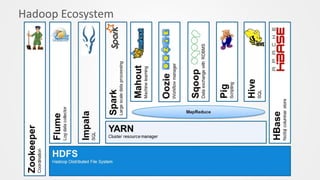
Big Data_Architecture.pptx
- 2. Components of a Big Data Architecture
- 3. Orchestration • Most big data solutions consist of repeated data processing operations, encapsulated in workflows that: – transform source data, – move data between multiple sources and sinks, – load the processed data into an analytical data store, – or push the results straight to a report or dashboard.
- 4. Orchestration • In the data pipeline example below, the orchestration-based solution has a central orchestration flow with all of the state transition rules that are centrally managed in a tool (e.g. Oozie, activity, Azkaban, etc.). • Each service sends the event/data back to the central brain, which guides the process to the next step.
- 5. Choreography • Choreography is a set of decoupled microservices that knows what data to expect and provide without a central brain or conductor.
- 6. λ Lambda architecture • First proposed by Nathan Marz, – Addresses this problem by creating two paths for data flow. • All data coming into the system goes through these two paths: – A batch layer (cold path) stores all of the incoming data in its raw form and performs batch processing on the data. The result of this processing is stored as a batch view. – A speed layer (hot path) analyzes data in real time. This layer is designed for low latency, at the expense of accuracy. – The batch layer feeds into a serving layer that indexes the batch view for efficient querying. – The speed layer updates the serving layer with incremental updates based on the most recent data.
- 8. λ Lambda architecture • A drawback to the lambda architecture – is its complexity. • Processing logic appears in two different places – — the cold and hot paths — using different frameworks. – leads to duplicate computation logic and the complexity of managing the architecture for both paths. • Example of Projects implementing Lambda Architecture – Generic: Twitter Summingbird • https://github.com/twitter/summingbird – Dedicated to machine Learning: Cloudera Oryx 2 • http://oryx.io/)
- 9. λ Lambda architecture: strengths • Immutability - retaining master data – With timestamped events – Appended versus overwritten events • Attempt to beat CAP • Pre-computed views for – further processing – faster ad-hoc querying
- 10. λ Lambda architecture: weakness • Two Analytics systems to support • Operational complexity • By the time a scheduled job is run 90% of the data is stale • Many moving parts: KV store, real time platform, batch technologies • Running similar code and reconciling queries in dual systems • Analytics logic changes on dual systems
- 11. Kappa Architecture - Where Every Thing Is A Stream • The kappa architecture was proposed by Jay Kreps as an alternative to the lambda architecture. • It has the same basic goals as the lambda architecture, but with an important distinction: – All data flows through a single path, using a stream processing system.
- 13. Kappa Architecture: • strengths – solution to do everything, – independent technology, – simpler than the Lambda architecture. • weakness – no separation between needs, – growing competence. • Kappa architecture is used by companies like Linkedin.
- 14. SMACK architecture • The SMACK architecture (for Spark Mesos Akka Cassandra Kafka) – is quite different from the Lambda or Kappa architectures since it consists of a list of solutions. – It is therefore necessary to understand the advantages and weaknesses of the solutions before validating the implementation of a use case. – Kafka is sometimes replaced by Kinesis on the cloud (Amazon AWS)
- 15. • Spark - fast and general engine for distributed, large-scale data processing • Mesos - cluster resource management system that provides efficient resource isolation and sharing across distributed applications • Akka - a toolkit and runtime for building highly concurrent, distributed, and resilient message-driven applications on the JVM • Cassandra - distributed, highly available database designed to handle large amounts of data across multiple datacenters • Kafka - a high-throughput, low-latency distributed messaging system/commit log designed for handling real- time data feeds SMACK architecture
- 17. • strengths – a minimum of solutions capable of handling a very large number of problems, – mature solutions of Big Data, – scalability of solutions, – unique management solution (Mesos), – compatible batchs, real time, Lambda, ... • weakness – integration of new needs and therefore new frameworks, – complex architecture. • The SMACK architecture is used by companies like TupleJump or ING. SMACK architecture
- 18. Microservices Architecture • The microservice architecture is often described Container-Oriented Architecture. • This is not a complete architecture and specific to Big Data.
- 20. Microservices Architecture vs SOA • Microservices are the natural evolution of service oriented architectures (SOA) • Differences between microservices and SOA – In a microservices architecture, services • are small, independent, and loosely coupled. – Each service is a separate codebase, which can be managed by a small development team. – Services can be deployed independently. – Services are responsible for persisting their own data or external state. This differs from the traditional model, where a separate data layer handles data persistence. – Services communicate with each other by using well-defined APIs. – Internal implementation details of each service are hidden from other services. – Services don't need to share the same technology stack, libraries, or frameworks.
- 21. Microservices Architecture Orchestration Docker and its ecosystem are great for managing images, and running containers in a specific host. Kubernates: provides orchestration, service discovery, load balancing -- together in one nice package for you. Discovery Load Balancing
- 22. Criteria for selecting an architecture Architecture Main criterion Use case Hadoop Store data at a low cost Data Lake lambda Build a complete view of the data Chain of treatment / valuation of the data Kappa Provide a fresh vision of the data Business data for users SMACK Deal with data at a low cost Data Analysis (Machine Learning) Microservices Scalability (elasticity), decoupling Smart Cities
- 23. Smart Tarffic- IOT Reference Architecture
- 24. Data sources • All big data solutions start with one or more data sources. Examples include: – Application data stores, such as relational databases. – Static files produced by applications, such as web server log files. – Real-time data sources, such as IoT devices.
- 25. Data storage • Data for batch processing operations is typically stored in a distributed file store that can hold high volumes of large files in various formats. – Data lake (Azure Data Lake Store , S3, HDFS(Cloudera, Hortonworks) – NoSQL Store (Cassandra, Hbase, Neo4j, mongodb) – Database as Service : DBaaS • Oracle Database as a Service , • Azure Storage (Microsoft Azure Cloud SQL Database )
- 26. Batch processing • Because the data sets are so large, often a big data solution must process data files using long-running batch jobs to filter, aggregate, and otherwise prepare the data for analysis. Usually these jobs involve reading source files, processing them, and writing the output to new files. Options include running U-SQL jobs in Azure Data Lake Analytics, using Hive, Pig, or custom Map/Reduce jobs in an HDInsight Hadoop cluster, or using Java, Scala, or Python programs in an HDInsight Spark cluster.
- 27. Real-time message ingestion. • If the solution includes real-time sources, the architecture must include a way to capture and store real- time messages for stream processing. This might be a simple data store, where incoming messages are dropped into a folder for processing. However, many solutions need a message ingestion store to act as a buffer for messages, and to support scale-out processing, reliable delivery, and other message queuing semantics. This portion of a streaming architecture is often referred to as stream buffering. Options include Azure Event Hubs, Azure IoT Hub, and Kafka.
- 28. Stream processing • After capturing real-time messages, the solution must process them by filtering, aggregating, and otherwise preparing the data for analysis. The processed stream data is then written to an output sink. Azure Stream Analytics provides a managed stream processing service based on perpetually running SQL queries that operate on unbounded streams. You can also use open source Apache streaming technologies like Storm and Spark Streaming in an HDInsight cluster.
- 29. Analytical data store • Many big data solutions prepare data for analysis and then serve the processed data in a structured format that can be queried using analytical tools. The analytical data store used to serve these queries can be a Kimball-style relational data warehouse, as seen in most traditional business intelligence (BI) solutions. Alternatively, the data could be presented through a low-latency NoSQL technology such as HBase, or an interactive Hive database that provides a metadata abstraction over data files in the distributed data store. Azure SQL Data Warehouse provides a managed service for large-scale, cloud-based data warehousing. HDInsight supports Interactive Hive, HBase, and Spark SQL, which can also be used to serve data for analysis.
- 30. Analysis and reporting • The goal of most big data solutions is to provide insights into the data through analysis and reporting. To empower users to analyze the data, the architecture may include a data modeling layer, such as a multidimensional OLAP cube or tabular data model in Azure Analysis Services. It might also support self-service BI, using the modeling and visualization technologies in Microsoft Power BI or Microsoft Excel. Analysis and reporting can also take the form of interactive data exploration by data scientists or data analysts. For these scenarios, many Azure services support analytical notebooks, such as Jupyter, enabling these users to leverage their existing skills with Python or R. For large-scale data exploration, you can use Microsoft R Server, either standalone or with Spark.