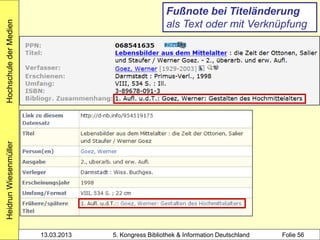
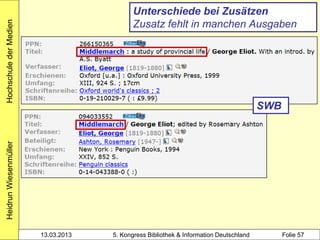
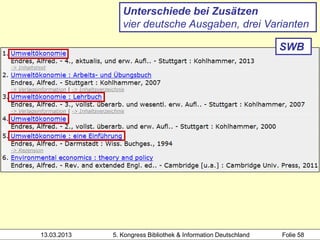
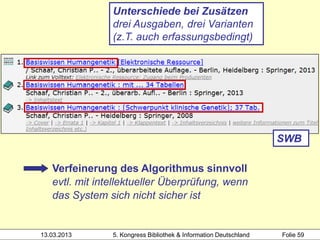
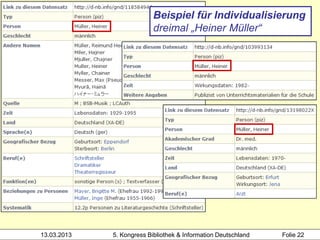
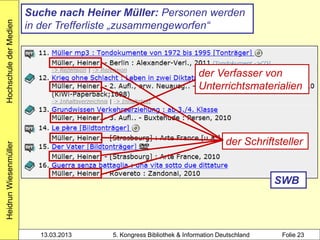
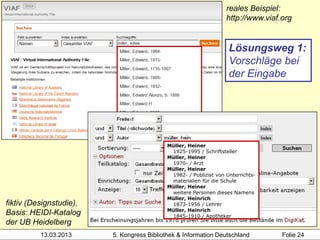
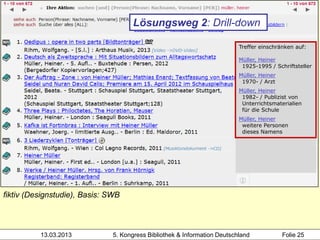
Der Workshop von Heidrun Wiesenmüller an der Hochschule der Medien thematisiert die Herausforderungen und Möglichkeiten der Individualisierung und Differenzierung von Normsätzen im Bereich des Clustering von Werkdaten. Es wird aufgezeigt, wie durch maschinelles Erstellen von Normsätzen und Optimierungspotenziale beim Clustering eine Verbesserung in der Katalogisierung und Analyse von Bibliotheksdaten erzielt werden kann. Die Untersuchung der bestehenden Problematik und der Integration angloamerikanischer Daten könnte die Individualisierung und Verknüpfung von Datensätzen entscheidend fördern.





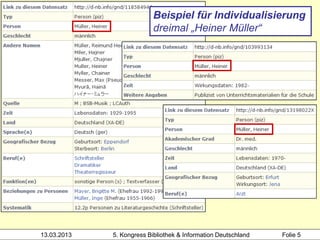







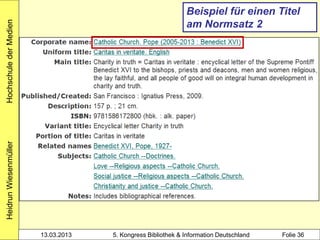





![1100 1972
1500 ger
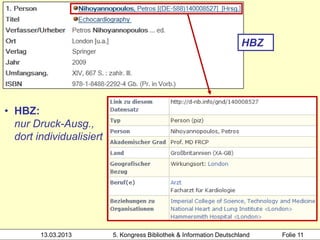
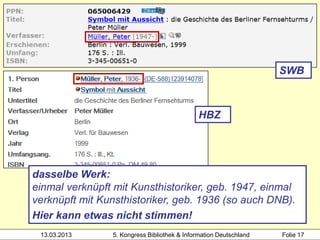
Hochschule der Medien
2000 3-7940-2607-1
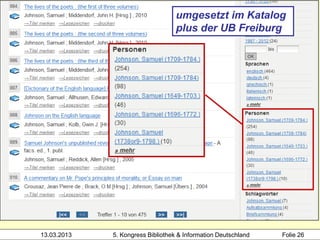
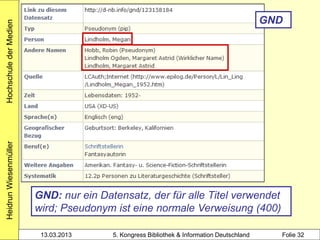
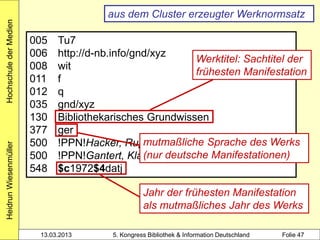
3000 !PPN!Hacker, Rupert*1935-*
4000 Bibliothekarisches Grundwissen$hRupert Hacker
4030 München-Pullach [u.a.]$nVerl. Dokumentation
4060 368 S. Beispiel 1:
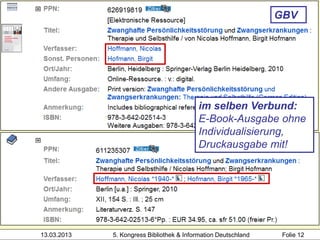
1100 2008 zwei Mitglieder desselben
1500 ger Clusters (SWB, gekürzt)
2000 978-3-598-11771-8
3000 !PPN!Gantert, Klaus*1968-*
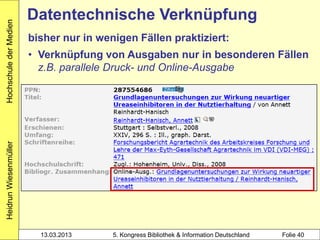
Heidrun Wiesenmüller
3001 !PPN!Hacker, Rupert*1935-*
4000 Bibliothekarisches Grundwissen$hKlaus Gantert;
Rupert Hacker
4020 8., vollst. neu bearb. und erw. Aufl.
4030 München$nSaur
4060 414 S.
13.03.2013 5. Kongress Bibliothek & Information Deutschland Folie 45](https://image.slidesharecdn.com/wiesenmuellerbibliothekskongress2013workshop-clustering-130317141408-phpapp01/85/Heidrun-Wiesenmuller-Anreichern-abgleichen-verknupfen-Anwendungsideen-fur-das-Werk-Clustering-45-320.jpg)



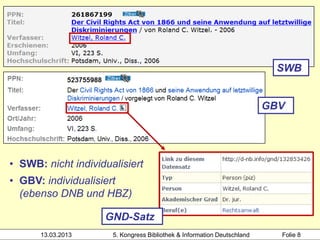
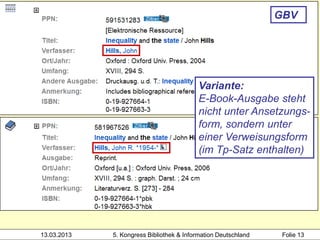
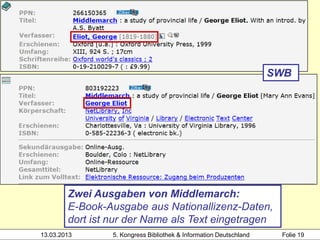
![1100 2012
1500 eng
Hochschule der Medien
2000 978-1-4087-0420-2
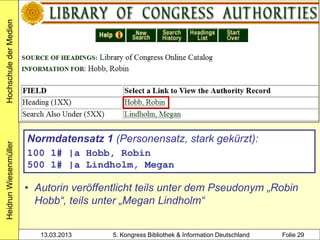
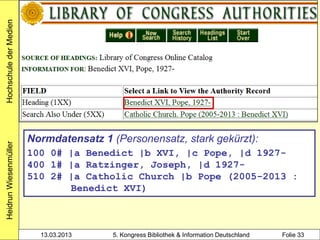
3000 !PPN!Rowling, Joanne K.*1965-*
4000 The @casual vacancy$hJ. K. Rowling
4030 London$nLittle, Brown
4060 503 S. Beispiel 2:
1100 2012 zwei Mitglieder desselben
1500 ger$ceng Clusters (SWB, gekürzt)
2000 978-3-551-58888-3
3000 !PPN!Rowling, Joanne K.*1965-*
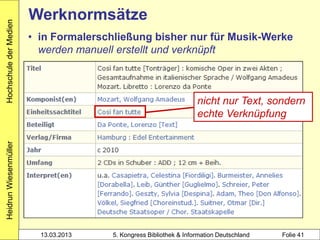
Heidrun Wiesenmüller
3010 !PPN!Aeckerle, Susanne*1942-*[Übers.]
3211 The @casual vacancy <dt.>
4000 Ein @plötzlicher Todesfall$dRoman$hJ. K.
Rowling. Aus dem Engl. von Susanne Aeckerle ...
4030 Hamburg$nCarlsen
4060 574 S.
13.03.2013 5. Kongress Bibliothek & Information Deutschland Folie 50](https://image.slidesharecdn.com/wiesenmuellerbibliothekskongress2013workshop-clustering-130317141408-phpapp01/85/Heidrun-Wiesenmuller-Anreichern-abgleichen-verknupfen-Anwendungsideen-fur-das-Werk-Clustering-50-320.jpg)

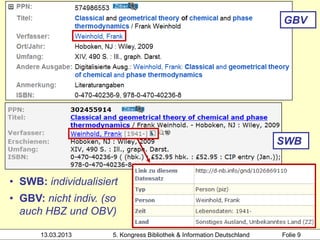
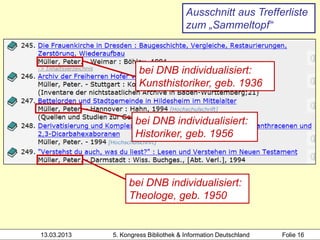
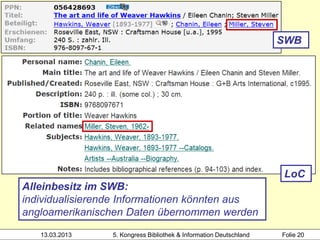
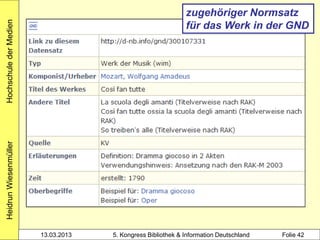
![Hochschule der Medien
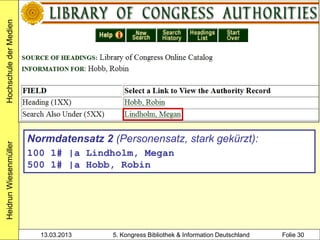
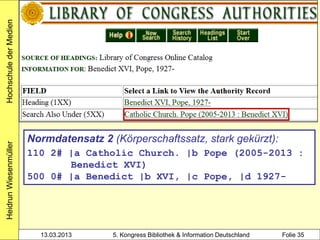
alle Mitglieder des Clusters werden
mit Werknormsatz verknüpft
1100 2012
1500 ger$ceng
2000 978-3-551-58888-3
3000 !PPN!Rowling, Joanne K.*1965-*
3010 !PPN!Aeckerle, Susanne*1942-*[Übers.]
3211 The @casual vacancy <dt.>
3212 !PPN!The @casual vacancy / Rowling,
Joanne K.*1965-*
4000 Ein @plötzlicher Todesfall$dRoman$hJ. K.
Heidrun Wiesenmüller
Rowling. Aus dem Engl. von Susanne Aeckerle ...
4030 Hamburg$nCarlsen Verknüpfung zum Werk-
4060 574 S. normsatz über Identnummer
13.03.2013 5. Kongress Bibliothek & Information Deutschland Folie 52](https://image.slidesharecdn.com/wiesenmuellerbibliothekskongress2013workshop-clustering-130317141408-phpapp01/85/Heidrun-Wiesenmuller-Anreichern-abgleichen-verknupfen-Anwendungsideen-fur-das-Werk-Clustering-52-320.jpg)