Als PDF, PPTX herunterladen









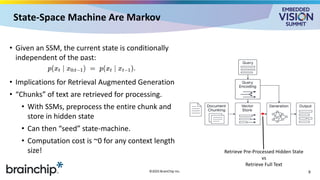


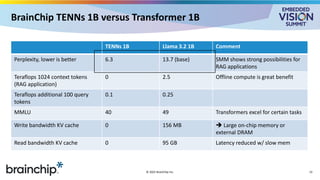





For the full video of this presentation, please visit: https://www.edge-ai-vision.com/2025/06/state-space-models-vs-transformers-for-ultra-low-power-edge-ai-a-presentation-from-brainchip/ Tony Lewis, Chief Technology Officer at BrainChip, presents the “State-space Models vs. Transformers for Ultra-low-power Edge AI” tutorial at the May 2025 Embedded Vision Summit. At the embedded edge, choices of language model architectures have profound implications on the ability to meet demanding performance, latency and energy efficiency requirements. In this presentation, Lewis contrasts state-space models (SSMs) with transformers for use in this constrained regime. While transformers rely on a read-write key-value cache, SSMs can be constructed as read-only architectures, enabling the use of novel memory types and reducing power consumption. Furthermore, SSMs require significantly fewer multiply-accumulate units—drastically reducing compute energy and chip area. New techniques enable distillation-based migration from transformer models such as Llama to SSMs without major performance loss. In latency-sensitive applications, techniques such as precomputing input sequences allow SSMs to achieve sub-100 ms time-to-first-token, enabling real-time interactivity. Lewis presents a detailed side-by-side comparison of these architectures, outlining their trade-offs and opportunities at the extreme edge.

















![[February 2017 - Ph.D. Final Dissertation] Enabling Power-awareness For Multi...](https://cdn.slidesharecdn.com/ss_thumbnails/matteoferroni-enablingpower-awarenessformulti-tenantsystems-171205223104-thumbnail.jpg?width=640&height=640&fit=bounds)

















































