Als PDF, PPTX herunterladen







![Beispiel 1
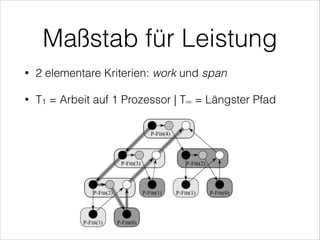
•
Laufe durch das Array A und quadriere A[i]
•
Serielle Laufzeit: O(n)](https://image.slidesharecdn.com/multithreadedalgorithmsofficial-140124113704-phpapp02/85/Multithreaded-Algorithms-8-320.jpg)
![Beispiel 2
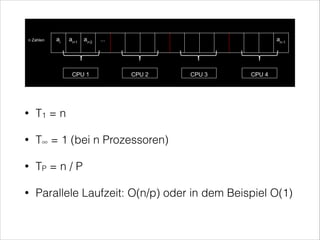
•
findMax(int[] A)
•
Serielle Laufzeit: O(n)](https://image.slidesharecdn.com/multithreadedalgorithmsofficial-140124113704-phpapp02/85/Multithreaded-Algorithms-10-320.jpg)
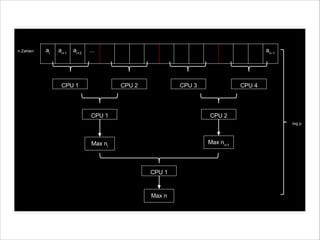










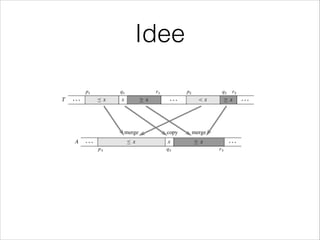
![•
Array T[] und Array A[]
•
Zwei (sortierte) Teilfolgen
T[p1..r1] mit n1 = r1 - p1 + 1
T[p2..r2] mit n2 = r2 - p2 + 1
•
werden vereinigt in
A[p3..r3] der Länge n3 = r3 - p3 + 1 = n1 + n2](https://image.slidesharecdn.com/multithreadedalgorithmsofficial-140124113704-phpapp02/85/Multithreaded-Algorithms-24-320.jpg)
![•
Wir nehmen an n1 ≥ n2
•
•
Identifizieren von x = T[q1] der sortierten Teilfolge
T[p1..r1] an der Stelle
q1 = (p1 + r1) / 2
x ist somit der Median von T[p1..r1]](https://image.slidesharecdn.com/multithreadedalgorithmsofficial-140124113704-phpapp02/85/Multithreaded-Algorithms-25-320.jpg)
![•
Jedes Element in T[p1..q1 - 1] ≤ x
•
Jedes Element in T[q1 + 1..r1] ≥ x
•
Mit Hilfe von BinarySearch() wird anschliessend
das Element T[q2] ermittelt, um sicherzustellen,
dass T[p2..r2] nach dem Einfügen von x zwischen
T[q2-1] und T[q2] immer noch sortiert ist](https://image.slidesharecdn.com/multithreadedalgorithmsofficial-140124113704-phpapp02/85/Multithreaded-Algorithms-26-320.jpg)
![Anschließend Vereinigen der Teilfolgen T[p1..r1] und T[p2..r2] nach
A[p3..r3] in folgenden Schritten:
•
1. Setze q3 = p3 + (q1 - p1) + (q2 - p2)
2. Kopiere x nach A[q3]
3. Rekursives Merge() von T[p1..q1 - 1] mit T[p2..q2 - 1] und setze
das Ergebnis in die Teilfolge A[p3..q3 - 1]
4. Rekursives Merge() von T[q1 + 1..r1] mit T[q2..r2] und setze das
Ergebnis in die Teilfolge A[q3 + 1..r3]](https://image.slidesharecdn.com/multithreadedalgorithmsofficial-140124113704-phpapp02/85/Multithreaded-Algorithms-27-320.jpg)

![Binary Search
•
Die Prozedur BinarySearch(x, T, p, r) erhält einen Schlüssel x und
eine Teilfolge T[p..r] und gibt eine der folgenden Werte zurück:
•
•
Wenn x ≤ T[p] und daher ≤ alle Elemente in T[p..r]:
Rückgabewert: Index p
•
•
Wenn T[p..r] leer ist (r < p)
Rückgabewert: Index p
Wenn x > T[p] dann gebe den größten Index q in dem Bereich p
< q ≤ r + 1, so dass gilt T[q-1] < x zurück
Aufgrund der seriellen Bearbeitung wird daher Θ(log n) im
schlechtesten Fall benötigt. Work und span können also insgesamt
mit Θ(log n) abgeschätzt werden](https://image.slidesharecdn.com/multithreadedalgorithmsofficial-140124113704-phpapp02/85/Multithreaded-Algorithms-29-320.jpg)


![Im schlechtesten Fall führt ein rekursiver Aufruf n1/2
Elemente aus T[p1..r1] mit allen n2 Elementen aus T[p2..r2]
zusammen:
•
n1/2+ n2 ≤ n1/2 + n2/2 + n2/2
= (n1 + n2) / 2 + n2/2
≤ n/2 + n/4
= 3n / 4
Gemeinsam mit O(log n) aus BINARY-SEARCH ergibt sich
eine Gesamtabschätzung von:
•
PM∞(n) = PM∞(3n/4) + Θ(log n)
PM∞(n) = Θ(log2 n)](https://image.slidesharecdn.com/multithreadedalgorithmsofficial-140124113704-phpapp02/85/Multithreaded-Algorithms-32-320.jpg)







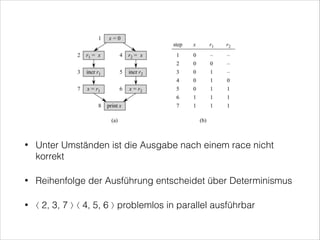
Das Dokument behandelt multithreaded Algorithmen, insbesondere den parallelen Mergesort, und erläutert technische Aspekte sowie die Leistungsanalyse von Algorithmen im Kontext mehrerer Prozessoren. Es wird beschrieben, wie parallele Berechnungen durchgeführt werden können, während Herausforderungen wie Race Conditions und die Notwendigkeit der Synchronisation angesprochen werden. Zudem wird die Effizienz des parallelen Mergesorts im Vergleich zu herkömmlichem Mergesort hervorgehoben, wobei bedeutende Leistungsgewinne erzielt werden können.



























