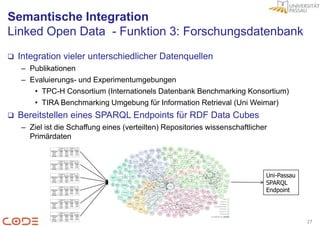
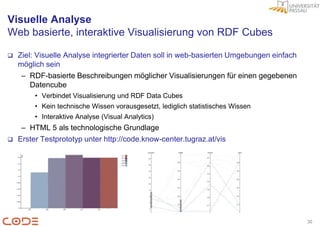
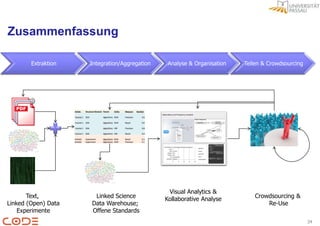
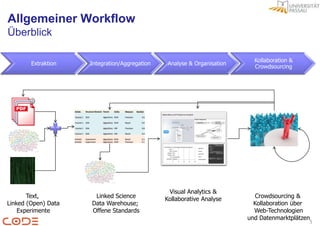
Das Dokument beschreibt die Herausforderungen der Faktenextraktion aus Forschungspublikationen und präsentiert einen Lösungsansatz im Forschungsprojekt CODE, das semantische Technologien und Crowdsourcing integriert. Ziel ist es, unstrukturierte Daten in ein semantisches Format zu überführen, um die Analyse und Visualisierung zu verbessern und die Qualität durch Benutzerfeedback zu sichern. Der allgemeine Workflow umfasst die Extraktion, Integration und visuelle Analyse von Forschungsdaten, wobei Linked Open Data als gemeinsame Beschreibungssprache dient.




















![Semantische Integration
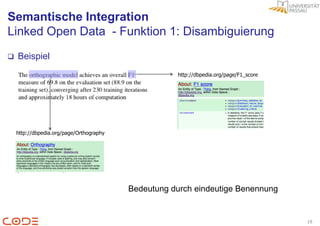
Linked Open Data - Funktion 2: Einheitliches Format
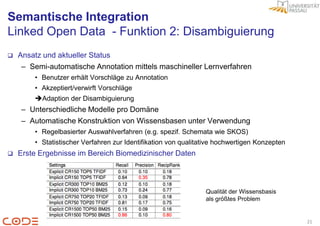
Nominal Nominal [0;1] [0;1]
Schema
Method Features Cosine Jaccard - Name
ANDD-Raw Unigram 0.956 0.952 - Einheit
Normalisierung TFIDF Unigram 0.884 0.874 - Ausprägung
Binary Unigram 0.861 0.852
SpotSigs Unigram 0.953 0.952
ANDD-Raw Trigram 0.936 0.91
Beobachtungen
TFIDF Trigram 0.875 0.873
Binary Trigram 0.869 0.867
SpotSigs Trigram NA NA
Zusätzliche Tabelle
Hinzufügen v. Tabellen in gleiche Repräsentation
Datensatz Method Features Cosine Jaccard
Quelle 1 ANDD-Raw Unigram 0.956 0.952
Quelle 1 TFIDF Unigram 0.884 0.874
Quelle 1 Binary Unigram 0.861 0.852
Quelle 1 SpotSigs Unigram 0.953 0.952
Quelle 1 ANDD-Raw Trigram 0.936 0.91
Quelle 1 TFIDF Trigram 0.875 0.873
Quelle 1 Binary Trigram 0.869 0.867
Quelle 1 SpotSigs Trigram NA NA
Quelle 2 ANDD-Raw NA 0.674 0.7
Quelle 2 TFIDF NA 0.625 0.626
Quelle 2 Binary NA 0.622 0.622
Quelle der Tabellen: H. Hajishirzi, W. Yih, and A. Kolcz, “Adaptive near-duplicate
detection via similarity learning,” in Proceeding of the 33rd international ACM SIGIR Quelle 2 SpotSigs NA 0.257 0.258
conference on Research and development in information retrieval, 2010, pp. 419–
426.
23](https://image.slidesharecdn.com/mgrani-trier-faktenextraktion-130219100113-phpapp01/85/Mgrani-trier-faktenextraktion-23-320.jpg)
![Semantische Integration
Linked Open Data - Funktion 2: Einheitliches Format
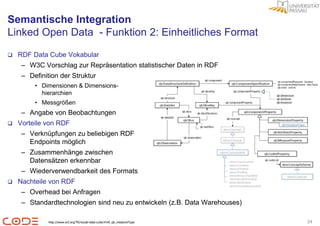
Beisipiel
Datensatz Beschreibung
code:mydataset a qb:DataSet;
rdfs:isDefinedBy <http://www.dummy.de/>;
rdfs:label “NER Vergleiche";
qb:structure code:dsd_ner.
Datensatz Struktur
code:dsd_ner a qb:DataStructureDefinition;
qb:component [ qb:dimension code:Methode];
qb:component [ qb:measure code:Cosine;
qb:conept <http://dbpedia.org/page/Cosine_similarity> ];
qb:component [ qb:measure code:Jaccard ];
Datenpunkte
Linked Data
code:obs1 a qb:Observation;
code:Methode [ rdfs:label “TFIDF" ];
code:Cosine [ rdfs:label "0.625" ];
code:Jaccard [ rdfs:label "0.622" ];
qb:dataSet code:mydatase.
25](https://image.slidesharecdn.com/mgrani-trier-faktenextraktion-130219100113-phpapp01/85/Mgrani-trier-faktenextraktion-25-320.jpg)