Downloaden Sie, um offline zu lesen





![Vorhandener Datensatz in Empfehlungssystemen
Benutzer × Items Star Wars Star Gate Micky Mouse
Julia 0 3 4
Paul 5 4 4
Peter 5 3.5 0
Torsten 1 0 3
Hans 5 2 0
Olaf 1 0 0
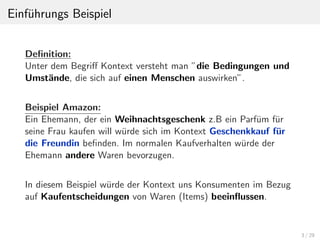
In normalen Empfehlungssystemen wird zu jedem Benutzer und
jedem Item, eine abgegebene Benutzerbewertung gespeichert.
z.B r ∈ [0-5]
Datensatz der Form: <U, I, R>
R: Menge aller Benutzerbewertungen r
9 / 29](https://image.slidesharecdn.com/seminarpraesentation-180108230941/85/Kontext-basierte-Personalisierungsansatze-9-320.jpg)

![Bewertungsfunktion: Rank
Formal:
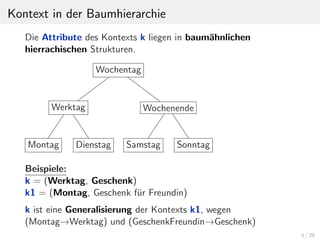
Die Bewertungsfunktion Rank ordnet jedem Benutzer u und
jedem Item i einen positiven Wert gr¨oßer 0 zu.
Wichtig:
Je gr¨oßer dieser Wert ausf¨allt, desto wichtiger ist ein Item f¨ur
einen Benutzer.
TopN Items
BenutzerBewertung R = U × IBenuzter U
Items I
Funktion: Rank Bewertung ∈ ]0,...]
Nach der Berechnung der Rank Funktion werden die h¨ochst
bewerteten Items in die Menge TopN gespeichert.
11 / 29](https://image.slidesharecdn.com/seminarpraesentation-180108230941/85/Kontext-basierte-Personalisierungsansatze-11-320.jpg)

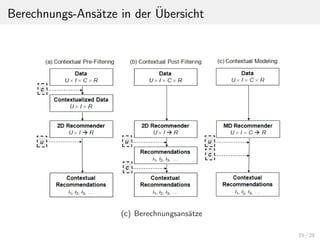
![Ansatz 1: Kontextuelle Vorfilterung
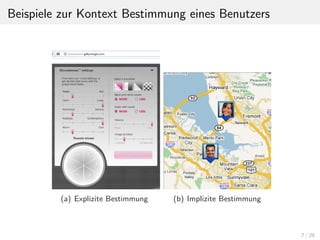
Bei der kontextuellen Vorfilterung wird zun¨achst die Dimension K
aus dem Datensatz durch Selektion mit K=k’ eliminiert.
DATA := <U, I, K=k’, R>
Somit entsteht die Datenmenge DATA’:
DATA[k’] = <U, I, k’, R> → DATA’ = <U, I, R>
Auf der neuen Datenmenge DATA[k’] kann wie bei normalen
Empfehlungssystemen die Bewertungsfunktion Rank aufgestellt
und berechnet werden, da die Dimension K des Kontexts wegf¨allt.
16 / 29](https://image.slidesharecdn.com/seminarpraesentation-180108230941/85/Kontext-basierte-Personalisierungsansatze-16-320.jpg)
![Ansatz 1: Kontextuelle Vorfilterung
Benutzer × Items Forrest Gump Star Wars 7 Cast Away
Julia in k’ 0 0 3
Julia in k” 0 4 0
Torsten in k’ 1 0 2
Selektion:
Mit K=k’ entsteht der neue Datensatz DATA[k’].
DATA[k’] = <U, I, k’, R>
Benutzer × Items Forrest Gump Star Wars 7 Cast Away
Julia in k’ 0 0 3
Torsten in k’ 1 0 2
Julia befindet sich momentan im Kontext k’. Alle anderen
abgegebenen Bewertungen der Benutzer im Kontext k’ w¨aren
f¨ur sie relevant.
17 / 29](https://image.slidesharecdn.com/seminarpraesentation-180108230941/85/Kontext-basierte-Personalisierungsansatze-17-320.jpg)


![Komplexit¨at modellbasierter Ans¨atze
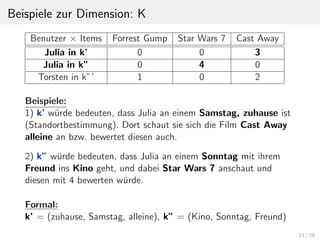
Beispiel: Online-Buchshop:
k = (WochenTag, KaufAbsicht, Niederschlag, Stimmung)
WochenTag = [Mo, Di, Mi, Do, Fr, Sa, So, WE, WT...]
KaufAbsicht = [Arbeit, Pers¨ohnlich, Geschenk, Partner, Freund,
Eltern, Sammlung, GeburtstagsGeschenk, HeiratsGeschenk]
Niederschlag = [0-2mm, 2-4mm, 4-100mm]
Stimmung = [ruhig, positiv, tatkr¨aftig, tr¨ube]
¨Uberschlags Rechnung:
GESAMT(K) = ANZAHL(WochenTag) ×
ANZAHL(KaufAbsicht) × ANZAHL(Niederschlag) ×
ANZAHL(Stimmung)
= 9 × 9 × 3 × 4
= 972 entspricht etwa 980 verschiedenen Kontexten in K.
20 / 29](https://image.slidesharecdn.com/seminarpraesentation-180108230941/85/Kontext-basierte-Personalisierungsansatze-20-320.jpg)






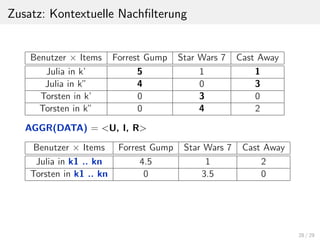
![Zusatz: Kontextuelle Nachfilterung
Auf der neuen Datenmenge AGGR(DATA) kann wie bei normalen
Empfehlungssystemen die Bewertungsfunktion Rank aufgestellt
und berechnet werden.
Nach der Berechnung wird eine Liste von TopN Items i erzeugt.
Anschließend werden mit Hilfe vordefinierter Regeln entweder
alle Kontext k’ relevanten Items h¨oher bewertet oder alle
Kontext relevanten Items aus der Liste herausgefiltert.
TopN[k’] = FILTER(TopN);
Die Menge TopN[k’] ist die Menge aller relevanten Items i f¨ur
einen Benutzer u’, der sich im aktuellen Kontext k’ befindet.
29 / 29](https://image.slidesharecdn.com/seminarpraesentation-180108230941/85/Kontext-basierte-Personalisierungsansatze-29-320.jpg)

Die Präsentation von Lucas Mußmächer am 4. Dezember 2013 behandelt kontextbasierte Personalisierungsansätze in Empfehlungssystemen. Der Kontext wird definiert, als die Bedingungen, die Kaufentscheidungen beeinflussen, und verschiedene Methoden zur Bestimmung und Einbeziehung des Kontexts in Empfehlungsberechnungen werden vorgestellt. Kontextbasierte Systeme zeigen höhere Genauigkeit und Einfluss auf das Kaufverhalten gegenüber traditionellen Systemen, erfordern jedoch aufgrund ihrer Komplexität mehr Rechenressourcen.



























