Downloaden Sie, um offline zu lesen





![7
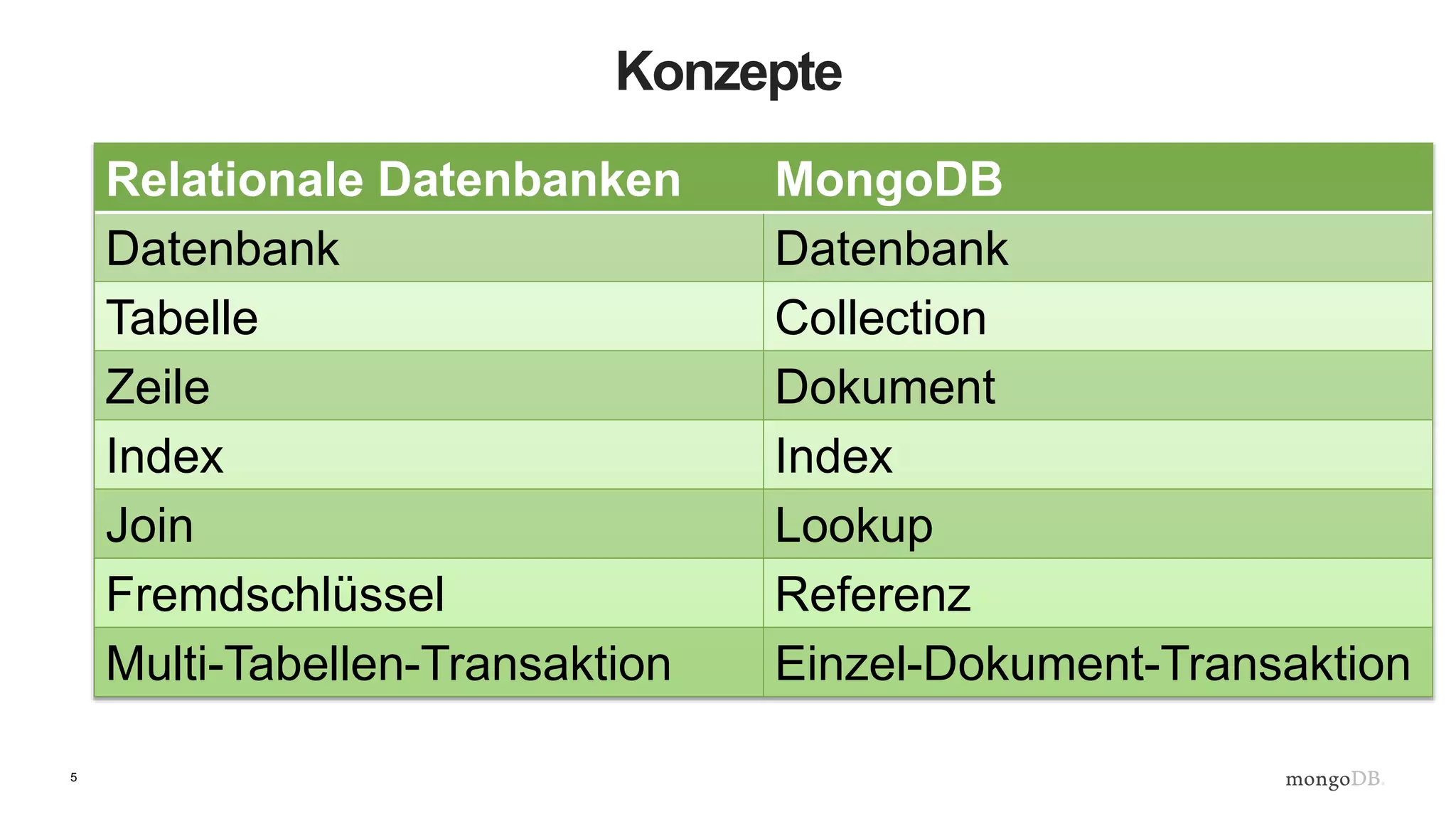
Ausführen von Mongod
JD10Gen:mongodb jdrumgoole$ ./bin/mongod --dbpath /data/b2b
2016-05-23T19:21:07.767+0100 I CONTROL [initandlisten] MongoDB starting : pid=49209 port=27017 dbpath=/data/b2b 64-
bit host=JD10Gen.local
2016-05-23T19:21:07.768+0100 I CONTROL [initandlisten] db version v3.2.6
2016-05-23T19:21:07.768+0100 I CONTROL [initandlisten] git version: 05552b562c7a0b3143a729aaa0838e558dc49b25
2016-05-23T19:21:07.768+0100 I CONTROL [initandlisten] allocator: system
2016-05-23T19:21:07.768+0100 I CONTROL [initandlisten] modules: none
2016-05-23T19:21:07.768+0100 I CONTROL [initandlisten] build environment:
2016-05-23T19:21:07.768+0100 I CONTROL [initandlisten] distarch: x86_64
2016-05-23T19:21:07.768+0100 I CONTROL [initandlisten] target_arch: x86_64
2016-05-23T19:21:07.768+0100 I CONTROL [initandlisten] options: { storage: { dbPath: "/data/b2b" } }
2016-05-23T19:21:07.769+0100 I - [initandlisten] Detected data files in /data/b2b created by the 'wiredTiger'
storage engine, so setting the active storage engine to 'wiredTiger'.
2016-05-23T19:21:07.769+0100 I STORAGE [initandlisten] wiredtiger_open config:
create,cache_size=4G,session_max=20000,eviction=(threads_max=4),config_base=false,statistics=(fast),log=(enabled=true
,archive=true,path=journal,compressor=snappy),file_manager=(close_idle_time=100000),checkpoint=(wait=60,log_size=2GB)
,statistics_log=(wait=0),
2016-05-23T19:21:08.837+0100 I CONTROL [initandlisten]
2016-05-23T19:21:08.838+0100 I CONTROL [initandlisten] ** WARNING: soft rlimits too low. Number of files is 256,
should be at least 1000
2016-05-23T19:21:08.840+0100 I NETWORK [HostnameCanonicalizationWorker] Starting hostname canonicalization worker
2016-05-23T19:21:08.840+0100 I FTDC [initandlisten] Initializing full-time diagnostic data capture with directory
'/data/b2b/diagnostic.data'
2016-05-23T19:21:08.841+0100 I NETWORK [initandlisten] waiting for connections on port 27017
2016-05-23T19:21:09.148+0100 I NETWORK [initandlisten] connection accepted from 127.0.0.1:59213 #1 (1 connection now
open)](https://image.slidesharecdn.com/b2b-webinar-2-yourfirstmongodbapplicationde1-160616110209/75/Back-to-Basics-Webinar-2-Ihre-erste-MongoDB-Anwendung-7-2048.jpg)
![8
Verbinden über Mongo Shell
$ ./bin/mongo
MongoDB shell version: 3.2.6
connecting to: test
Server has startup warnings:
2016-05-17T11:46:03.516+0100 I CONTROL [initandlisten]
2016-05-17T11:46:03.516+0100 I CONTROL [initandlisten] ** WARNING: soft rlimits too low. Number of
files is 256, should be at least 1000
>](https://image.slidesharecdn.com/b2b-webinar-2-yourfirstmongodbapplicationde1-160616110209/75/Back-to-Basics-Webinar-2-Ihre-erste-MongoDB-Anwendung-8-2048.jpg)



![14
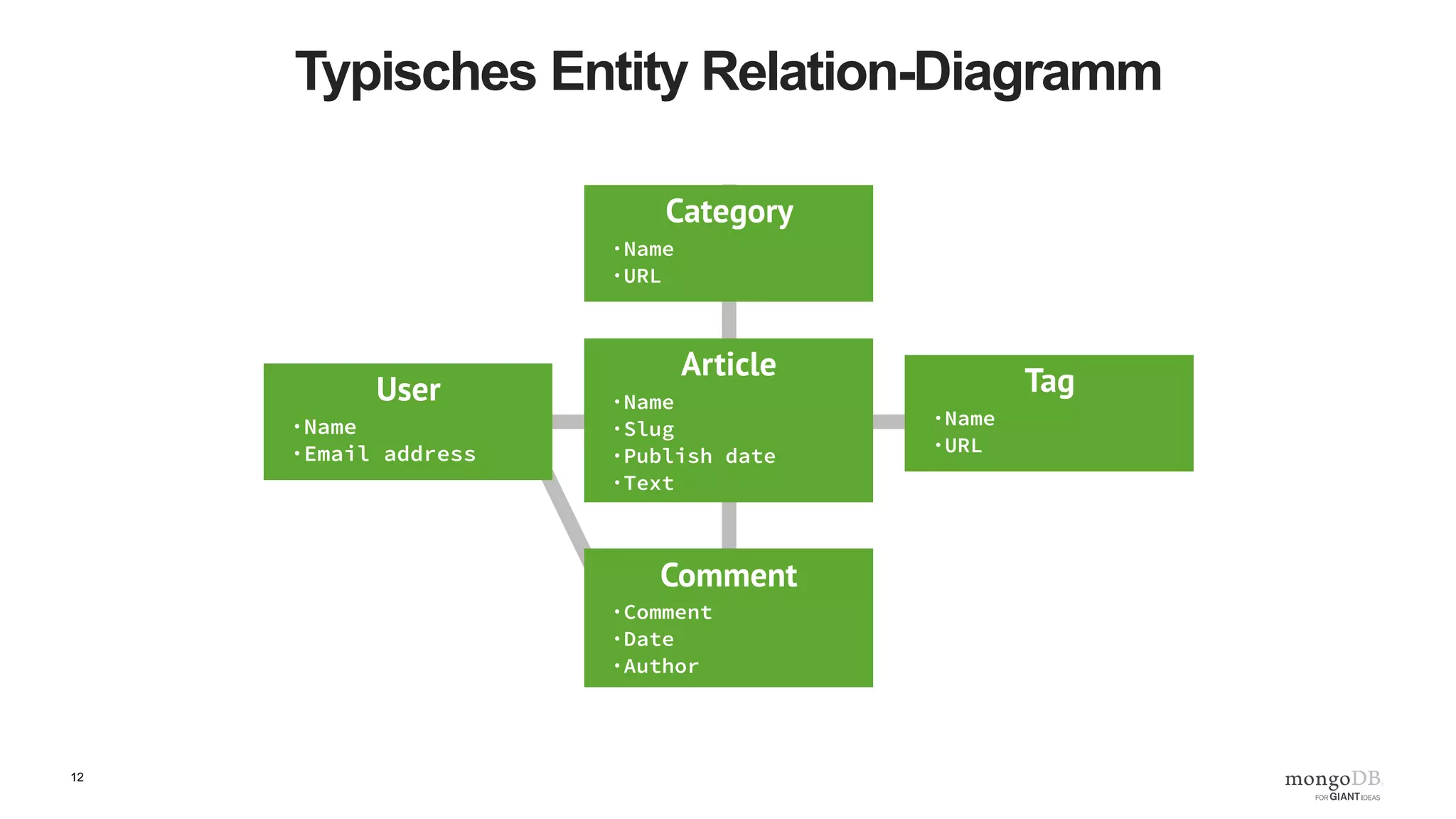
Noch einmal in Python
'''
Created on 16 June 2016
@author: benjamin.lorenz
'''
import pymongo
#
# client defaults to localhost and port 27017. eg MongoClient('localhost', 27017)
client = pymongo.MongoClient()
blogDatabase = client[ "blog" ]
usersCollection = blogDatabase[ "users" ]
usersCollection.insert_one( { "username" : “benjamin.lorenz",
"password" : "top secret",
"lang" : “DE" })
user = usersCollection.find_one()
print( user )](https://image.slidesharecdn.com/b2b-webinar-2-yourfirstmongodbapplicationde1-160616110209/75/Back-to-Basics-Webinar-2-Ihre-erste-MongoDB-Anwendung-14-2048.jpg)
![15
Kommen wir zu den Artikeln
…
articlesCollection = blogDatabase[ "articles" ]
author = “benjamin.lorenz"
article = { "title" : “Mein erstes Posting",
"body" : “Hier steht der eigentliche Inhalt. Ein längerer Text kann das sein.",
"author" : author,
"tags" : [ “benjamin", "general", “Germany", "admin" ]
}
#
# Lets check if our author exists
#
if usersCollection.find_one( { "username" : author }) :
articlesCollection.insert_one( article )
else:
raise ValueError( "Author %s does not exist" % author )](https://image.slidesharecdn.com/b2b-webinar-2-yourfirstmongodbapplicationde1-160616110209/75/Back-to-Basics-Webinar-2-Ihre-erste-MongoDB-Anwendung-15-2048.jpg)
![16
Ein neuer Artikeltyp
#
# Lets add a new type of article with a posting date and a section
#
author = “benjamin.lorenz"
title = “Ein englisches Posting in MongoDB"
newPost = { "title" : title,
"body" : "MongoDB is the worlds most popular NoSQL database. It is a document database",
"author" : author,
"tags" : [ “benjamin", "mongodb", “Frankfurt" ],
"section" : "technology",
"postDate" : datetime.datetime.now(),
}
#
# Lets check if our author exists
#
if usersCollection.find_one( { "username" : author }) :
articlesCollection.insert_one( newPost )](https://image.slidesharecdn.com/b2b-webinar-2-yourfirstmongodbapplicationde1-160616110209/75/Back-to-Basics-Webinar-2-Ihre-erste-MongoDB-Anwendung-16-2048.jpg)
![17
Viele Artikel erstellen, Teil 1
import pymongo
import string
import datetime
import random
def randomString( size, letters = string.letters ):
return "".join( [random.choice( letters ) for _ in xrange( size )] )
client = pymongo.MongoClient()
def makeArticle( count, author, timestamp ):
return { "_id" : count,
"title" : randomString( 20 ),
"body" : randomString( 80 ),
"author" : author,
"postdate" : timestamp }
def makeUser( username ):
return { "username" : username,
"password" : randomString( 10 ) ,
"karma" : random.randint( 0, 500 ),
"lang" : "EN" }](https://image.slidesharecdn.com/b2b-webinar-2-yourfirstmongodbapplicationde1-160616110209/75/Back-to-Basics-Webinar-2-Ihre-erste-MongoDB-Anwendung-17-2048.jpg)
![18
Viele Artikel erstellen, Teil 2
blogDatabase = client[ "blog" ]
usersCollection = blogDatabase[ "users" ]
articlesCollection = blogDatabase[ "articles" ]
bulkUsers = usersCollection.initialize_ordered_bulk_op()
bulkArticles = articlesCollection.initialize_ordered_bulk_op()
ts = datetime.datetime.now()
for i in range( 1000000 ) :
#username = randomString( 10, string.ascii_uppercase ) + "_" + str( i )
username = "USER_" + str( i )
bulkUsers.insert( makeUser( username ) )
ts = ts + datetime.timedelta( seconds = 1 )
bulkArticles.insert( makeArticle( i, username, ts ))
if ( i % 500 == 0 ) :
bulkUsers.execute()
bulkArticles.execute()
bulkUsers = usersCollection.initialize_ordered_bulk_op()
bulkArticles = articlesCollection.initialize_ordered_bulk_op()
bulkUsers.execute()
bulkArticles.execute()](https://image.slidesharecdn.com/b2b-webinar-2-yourfirstmongodbapplicationde1-160616110209/75/Back-to-Basics-Webinar-2-Ihre-erste-MongoDB-Anwendung-18-2048.jpg)



![22
Artikel anpassen für Kommentare, Teil 1
> db.articles.find( { "_id" : 19 } ).pretty()
{
"_id" : 19,
"body" :
"nTzOofOcnHKkJxpjKAyqTTnKZMFzzkWFeXtBRuEKsctuGBgWIrEBrYdvFIVHJWaXLUTVUXblOZZgUq
Wu",
"postdate" : ISODate("2016-05-23T12:02:46.830Z"),
"author" : "ASWTOMMABN_19",
"title" : "CPMaqHtAdRwLXhlUvsej"
}
> db.articles.update( { _id : 19 }, { $set : { comments : [] }} )
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })](https://image.slidesharecdn.com/b2b-webinar-2-yourfirstmongodbapplicationde1-160616110209/75/Back-to-Basics-Webinar-2-Ihre-erste-MongoDB-Anwendung-22-2048.jpg)
![23
Artikel anpassen für Kommentare, Teil 2
> db.articles.find( { _id :19 } ).pretty()
{
"_id" : 19,
"body" : "KmwFSIMQGcIsRcVJkoMcrIyatoKzeQiKvJkiVSrndXqrALVIYZxGpaMjucgXUV",
"postdate" : ISODate("2016-05-23T16:04:39.497Z"),
"author" : "USER_19",
"title" : "wTLreIEyPfovEkBhJZZe",
"comments" : [ ]
}
>](https://image.slidesharecdn.com/b2b-webinar-2-yourfirstmongodbapplicationde1-160616110209/75/Back-to-Basics-Webinar-2-Ihre-erste-MongoDB-Anwendung-23-2048.jpg)
![24
Artikel anpassen für Kommentare, Teil 3
> db.articles.update( { _id : 19 },
{ $push : { comments :
{ username : “benjamin.lorenz", comment : “Hallo, das ist cool! :-)" }
}} )
WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 })
> db.articles.find( { _id :19 } ).pretty()
{
"_id" : 19,
"body" : "KmwFSIMQGcIsRNTDBFPuclwcVJkoMcrIPwTiSZDYyatoKzeQiKvJkiVSrndXqrALVIYZxGpaMjucgXUV",
"postdate" : ISODate("2016-05-23T16:04:39.497Z"),
"author" : "USER_19",
"title" : "wTLreIEyPfovEkBhJZZe",
"comments" : [
{
"username" : “benjamin.lorenz",
"comment" : “Hallo, das ist cool! :-)"
}
]
}
>](https://image.slidesharecdn.com/b2b-webinar-2-yourfirstmongodbapplicationde1-160616110209/75/Back-to-Basics-Webinar-2-Ihre-erste-MongoDB-Anwendung-24-2048.jpg)


![27
Einen Anwender finden
> db.users.find( { "username" : "ABOXHWKBYS_199" } ).explain()
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "blog.users",
"indexFilterSet" : false,
"parsedQuery" : {
"username" : {
"$eq" : "ABOXHWKBYS_199"
}
},
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"username" : {
"$eq" : "ABOXHWKBYS_199"
}
},
"direction" : "forward"
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "JD10Gen.local",
"port" : 27017,
"version" : "3.2.6",
"gitVersion" : "05552b562c7a0b3143a729aaa0838e558dc49b25"
},
"ok" : 1
}](https://image.slidesharecdn.com/b2b-webinar-2-yourfirstmongodbapplicationde1-160616110209/75/Back-to-Basics-Webinar-2-Ihre-erste-MongoDB-Anwendung-27-2048.jpg)





![33
Ausführungsstufen
"executionStages" : {
"stage" : "FETCH",
"nReturned" : 1,
"executionTimeMillisEstimate" : 0,
"docsExamined" : 1,,
"inputStage" : {
"stage" : "IXSCAN",
"nReturned" : 1,
"executionTimeMillisEstimate" : 0,
"keyPattern" : {
"username" : 1
},
"indexName" : "username_1",
"isMultiKey" : false,
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 1,
"direction" : "forward",
"indexBounds" : {
"username" : [
"["USER_999999", "USER_999999"]"
]
},
"keysExamined" : 1,
"seenInvalidated" : 0
}
}
}](https://image.slidesharecdn.com/b2b-webinar-2-yourfirstmongodbapplicationde1-160616110209/75/Back-to-Basics-Webinar-2-Ihre-erste-MongoDB-Anwendung-33-2048.jpg)





Das Webinar behandelt die Grundlagen von MongoDB, von der Installation bis zur Erstellung einer einfachen Blogging-Anwendung. Es erklärt grundlegende Datenbankkonzepte und demonstriert die Verwendung von MongoDB, einschließlich der Erstellung, Abfrage und Aktualisierung von Daten. Der Kurs beinhaltet auch die Optimierung von Abfragen und das Arbeiten mit Benutzern und Artikeln in einer MongoDB-Datenbank.






















































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)











