Herunterladen – 30 Tage kostenlos
Anmelden
Hochladen
Sprache (DE)
Support
Business
Mobil
Soziale Medien
Marketing
Technologie
Kunst & Fotos
Karriere
Design
Bildung
Präsentationen & Vorträge
Regierungs- und gemeinnützige Organisationen
Gesundheitswesen
Internet
Recht
Leadership & Management
Automobil
Ingenieurwesen
Software
Personalbeschaffung & Personalwesen
Einzelhandel
Vertrieb
Serviceleistungen
Wissenschaft
Kleinunternehmen & Unternehmertum
Lebensmittel
Umweltschutz
Wirtschaft & Finanzen
Daten & Analysen
Investorbeziehungen
Sport
Seele & Geist
News & Politik
Reisen
Weiterbildung und Persönlichkeitsentwicklung
Immobilien
Unterhaltung & Humor
Gesundheit & Medizin
Geräte & Hardware
Lifestyle
Sprache ändern
Sprache
English
Español
Português
Français
Deutsche
Abbrechen
Speichern
DE
Hochgeladen von
srimoorthi
280 aufrufe
63
Mehr lesen
0
Speichern
Teilen
Einbetten
Präsentation einbetten
Herunterladen
Downloaden Sie, um offline zu lesen
1
/ 6
2
/ 6
3
/ 6
4
/ 6
5
/ 6
6
/ 6
Weitere ähnliche Inhalte
PDF
56
von
srimoorthi
PDF
57
von
srimoorthi
PDF
69
von
srimoorthi
PDF
50
von
srimoorthi
PDF
84
von
srimoorthi
PDF
75
von
srimoorthi
PDF
72
von
srimoorthi
PDF
83
von
srimoorthi
56
von
srimoorthi
57
von
srimoorthi
69
von
srimoorthi
50
von
srimoorthi
84
von
srimoorthi
75
von
srimoorthi
72
von
srimoorthi
83
von
srimoorthi
Andere mochten auch
PDF
82
von
srimoorthi
PDF
55
von
srimoorthi
PDF
68
von
srimoorthi
PDF
73
von
srimoorthi
PDF
70
von
srimoorthi
PDF
61
von
srimoorthi
PDF
60
von
srimoorthi
PDF
62
von
srimoorthi
PDF
59
von
srimoorthi
82
von
srimoorthi
55
von
srimoorthi
68
von
srimoorthi
73
von
srimoorthi
70
von
srimoorthi
61
von
srimoorthi
60
von
srimoorthi
62
von
srimoorthi
59
von
srimoorthi
Mehr von srimoorthi
PDF
94
von
srimoorthi
PDF
87
von
srimoorthi
PDF
52
von
srimoorthi
PDF
53
von
srimoorthi
PDF
51
von
srimoorthi
PDF
49
von
srimoorthi
PDF
45
von
srimoorthi
PDF
44
von
srimoorthi
PDF
43
von
srimoorthi
PDF
42
von
srimoorthi
PDF
41
von
srimoorthi
PDF
39
von
srimoorthi
PDF
38
von
srimoorthi
94
von
srimoorthi
87
von
srimoorthi
52
von
srimoorthi
53
von
srimoorthi
51
von
srimoorthi
49
von
srimoorthi
45
von
srimoorthi
44
von
srimoorthi
43
von
srimoorthi
42
von
srimoorthi
41
von
srimoorthi
39
von
srimoorthi
38
von
srimoorthi
63
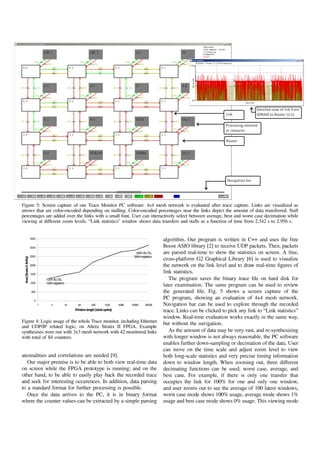
1.
978-1-4244-8971-8/10$26.00 c 2010
IEEE
Herunterladen