Implementación vSphere Metro Storage Cluster
•
0 gefällt mir•773 views

Implementación vSphere Metro Storage Cluster

Empfohlen
Empfohlen
Weitere ähnliche Inhalte
Was ist angesagt?
Was ist angesagt? (20)
Ähnlich wie Implementación vSphere Metro Storage Cluster
Ähnlich wie Implementación vSphere Metro Storage Cluster (20)
Mehr von RaGaZoMe
Mehr von RaGaZoMe (18)
Kürzlich hochgeladen
Kürzlich hochgeladen (15)
Implementación vSphere Metro Storage Cluster
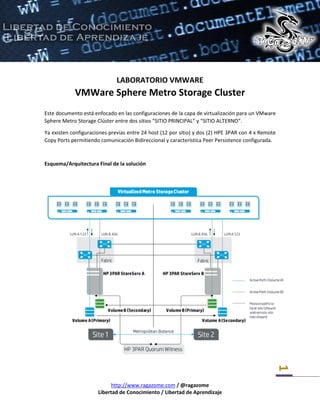
- 1. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 1 LABORATORIO VMWARE VMWare Sphere Metro Storage Cluster Este documento está enfocado en las configuraciones de la capa de virtualización para un VMware Sphere Metro Storage Clúster entre dos sitios “SITIO PRINCIPAL” y “SITIO ALTERNO”. Ya existen configuraciones previas entre 24 host (12 por sitio) y dos (2) HPE 3PAR con 4 x Remote Copy Ports permitiendo comunicación Bidireccional y característica Peer Persistence configurada. Esquema/Arquitectura Final de la solución
- 2. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 2
- 3. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 3 DETALLE DE ACTIVIDADES LAB Se debe crear un Clúster virtual en el vCenter el cual hará la tarea de “Stretch Clúster”, este deberá contener los host que pertenecerán al metro clúster, es decir, los host de ambos Datacenter. Previamente a esto, se configuro todo lo necesario alrededor de Networking LAN, WAN y SAN para que ambos Datacenter se visualicen y compartan tráfico. Para este laboratorio, también se utilizó como capa de almacenamiento 2 x HPE 3PAR X con sus respectivos puertos de RC configurados y adicional la característica de Peer Persistence sobre los CPG que están compartidos bidireccionalmente en las 3PAR.
- 4. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 4 Se activa DRS en el Stretch Clúster para Metro
- 5. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 5 Se activa HA y se procede a la configuración. La configuración para la pérdida permanente del dispositivo (PDL) es básica. En las condiciones de falla y la sección de respuesta VM, se puede configurar la respuesta después de la detección de una condición PDL. VMware recomienda configurar esto para Apagar y reiniciar máquinas virtuales. Cuando se detecta esta condición, una VM se reinicia instantáneamente en un host sano dentro del clúster de vSphere HA. Cuando se detecta una condición APD, se inicia un temporizador. Después de 140 segundos, la condición APD se declara oficialmente y el dispositivo se marca como tiempo de espera de APD. Cuando han pasado 140 segundos, vSphere HA comienza a contar. El tiempo de espera predeterminado de vSphere HA es de 3 minutos. Cuando hayan transcurrido los 3 minutos, vSphere HA reiniciará las máquinas virtuales impactadas, pero VMCP se puede configurar para que responda de manera diferente si así lo prefiere. VMware recomienda configurarlo para Apagar y reiniciar máquinas virtuales (conservador). Conservative se refiere a la probabilidad de que vSphere HA pueda reiniciar máquinas virtuales. Cuando se establece en conservativo, vSphere HA reinicia solo la VM que se ve afectada por la APD si detecta que un host en el clúster puede acceder al almacén de datos en el que reside la VM. En el caso de agresivo, vSphere HA intenta reiniciar la VM incluso si no detecta el estado de los otros hosts. Esto puede llevar a una situación en la que una máquina virtual no se reinicie porque no hay un host que tenga acceso al almacén de datos en el que se encuentra la máquina virtual. Entonces vamos a configurar.
- 6. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 6 Seguimos con la política de “Admission Control”, su política será configurarla al 50% tanto para la capacidad de memoria como para la CPU de reserva (Failover).
- 7. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 7 Se definen los DataStore Heartbeat que vienen presentados desde las 3PAR de ambos sitios sin replicación. En las 3PAR se recomienda crear CPG sin pertenecer a los CPG que están en RC, estos los utiliza VMware para funcionar como HeartBeat en el Stretch Clúster. 2 x 3PAR en cada DC. Como parámetros avanzados se emplearan como “das.isolationaddress” las direcciones IP de los HPE 3PAR en cada Datacenter.
- 8. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 8 En las últimas versiones se introdujo una configuración avanzada llamada “Disk.AutoremoveOnPDL”. Se implementa por defecto. Esta funcionalidad permite a vSphere eliminar dispositivos que están marcados como PDL y ayuda a evitar alcanzar, por ejemplo, el límite de 256 dispositivos para un host ESXi. Sin embargo, si el escenario PDL se resuelve y el dispositivo regresa, el sistema de almacenamiento del host ESXi debe volver a escanearse antes de que aparezca este dispositivo. VMware recomienda deshabilitar “Disk.AutoremoveOnPDL” en la configuración avanzada de cada uno de los hosts que pertenezcan a un Stretch Cluster para Metro configurándolo en 0.
- 9. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 9 Al final la configuración de HA se refleja de la siguiente manera: Reglas de Afinidad DRS En pocas palabras, esto ayuda a que la caracteristica DRS se active en las maquinas virtuales de un sitio y este se mueva en los host del mismo sitio, evitando asi, que una virtual machine se mueva entre sitios constantemente. VMware recomienda definir "sitios" manualmente al crear un grupo de hosts que pertenecen a un sitio y luego agregar máquinas virtuales a estos sitios en función de la afinidad del almacén de datos en el que se aprovisionan. Si la automatización del proceso no es una opción, se recomienda el uso de una convención de nomenclatura genérica para simplificar la creación de estos grupos. VMware recomienda que estos grupos se validen de forma periódica para garantizar que todas las máquinas virtuales pertenezcan al grupo con la afinidad correcta del sitio.
- 10. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 10 Primero se definen los Host Group de cada sitio:
- 11. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 11 Luego de definen los Virtual Machine Groups, que luego se asociaran a los host group correspondientes. En cada VM Group se agregar las virtual machine que pertenecen a cada sitio o Datacenter en nuestro caso igual como lo hicimos en el punto anterior con los host. Asi debería quedar la configuración.
- 12. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 12 Después de definir los Host y VM Groups, se configuran las reglas de afinidad, donde se relacionan las VM Group a un Host Group, y asi; determinar en que sitios y Host se pueden mover las VMs en su estado normal y buena salud en el Metro Storage Clúster.
- 13. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 13 Las reglas deberían visualizarse algo como lo sgte:
- 14. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 14 vSphere Storage DRS permite la agregación de almacenes de datos a una sola unidad de consumo desde una perspectiva administrativa y equilibra los discos VM cuando se superan los umbrales definidos. Asegura que haya suficientes recursos de disco disponibles para una carga de trabajo. VMware recomienda habilitar vSphere Storage DRS con la métrica de E/S deshabilitada. Para controlar si ocurren migraciones, VMware recomienda configurar vSphere Storage DRS en modo manual. Esto permite la validación humana por recomendación, así como las recomendaciones que se aplicarán durante las horas pico, al tiempo que se obtiene el beneficio operativo y la eficiencia de la funcionalidad de colocación inicial.
- 15. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 15
- 16. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 16
- 17. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 17
- 18. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 18 PRUEBAS Y ESCENARIOS DE FALLA VSPHERE METRO STORAGE CLUSTER 01 - Caída de un Host en uno de los sitios Este escenario muestra la caída de un host en un sitio y como debe reaccionar el entorno:
- 19. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 19 Resultado vSphere HA reinició exitosamente todas las máquinas virtuales de acuerdo con las reglas de afinidad VM-to-host. Explicación Si un host en un sitio falla, el nodo maestro de vSphere HA del clúster detecta el error porque ya no recibe los latidos de la red del host caido. Luego, el maestro comienza a monitorear los latidos del almacén de datos. Debido a que el host ha fallado por completo, no puede generar latidos del almacén de datos; estos también se detectan como faltantes por el nodo maestro de vSphere HA. Durante este tiempo, se lleva a cabo una tercera actividad de comprobación de disponibilidad de las direcciones de gestión de los hosts. Si todas estas comprobaciones devuelven resultados incorrectos, el maestro declara que el servidor faltante está muerto y trata de reiniciar todas las VM protegidas que se habían estado ejecutando en el host antes de que el maestro perdiera el contacto con el host. Las reglas de afinidad de vSphere VM a host definidas en un nivel de clúster son "reglas de debería." Las reglas de afinidad de vSphere HA VM-to-host deben respetarse para que todas las VM se reinicien dentro del sitio correcto (PRD). Sin embargo, si los elementos de host del grupo de VM a host carecen temporalmente de recursos, o si no están disponibles para reinicios por cualquier otro motivo, vSphere HA puede ignorar las reglas y reiniciar las VM restantes en cualquiera de los hosts restantes en el clúster, independientemente de la ubicación y las reglas. Si esto ocurre, vSphere DRS intenta corregir las reglas de afinidad violadas en la primera invocación y migra automáticamente las máquinas virtuales de acuerdo con sus reglas de afinidad para alinear la ubicación de VM. VMware recomienda invocar manualmente vSphere DRS después de que se haya identificado y resuelto la causa de la falla. Esto asegura que todas las máquinas virtuales se colocan en los hosts en la ubicación correcta para evitar la posible degradación del rendimiento debido a una mala colocación.
- 20. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 20 02 - Aislamiento de un solo host en el centro de datos En este escenario, se describe la respuesta al aislamiento de un único host en el centro de datos desde el resto de la red. Resultado Las VM permanecen en ejecución porque la respuesta de aislamiento está configurada “to leave powered on”. Explicación Cuando se aisla un host, el nodo maestro de vSphere HA detecta el aislamiento porque ya no recibe los latidos de la red del host. Luego, el maestro comienza a monitorear los latidos del almacén de datos. Debido a que el host está aislado, genera latidos del almacén de datos para el mecanismo de detección de vSphere HA secundario. La detección de latidos de host válidos permite que el nodo maestro de vSphere HA determine que el host se está ejecutando, pero está aislado de la red. Dependiendo de la respuesta de aislamiento configurada, el host afectado puede hacer “power off” o apagar las máquinas virtuales o puede dejarlas encendidas. La respuesta de aislamiento se activa 30 segundos después de que el host ha detectado que está aislada.
- 21. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 21 03 - Fallo de almacenamiento completo en el centro de datos En este escenario, se ha producido una falla completa en el sistema de almacenamiento en el centro de datos de PRD 3PAR. Resultado Las máquinas virtuales siguen funcionando sin ningún impacto. Explicación Cuando falla un sistema de almacenamiento completo en alguno de los centros de datos, El comando de toma de control debe iniciarse manualmente. Como se describió anteriormente, utilizamos una configuración MetroCluster de 3PAR para describir este comportamiento. Una vez que se ha iniciado el comando, la copia duplicada y de solo lectura de cada uno de los almacenes de datos fallidos se configura para que sea de lectura / escritura y se puede acceder de forma instantánea. Hemos descrito este proceso en un nivel extremadamente alto. Desde la perspectiva de la máquina virtual, esta conmutación por error es perfecta: los controladores de almacenamiento manejan esto, y ni vSphere ni el administrador de almacenamiento requieren ninguna acción. Ahora todas las E / S pasan a través de la conexión dentro del sitio al otro centro de datos porque las máquinas virtuales siguen funcionando en el centro de datos de PRD, mientras que sus almacenes de datos solo están accesibles en el centro de datos CRD. vSphere HA no detecta este tipo de falla. Aunque el latido del almacén de datos se puede perder brevemente, vSphere HA no realiza ninguna acción porque vSphere HA Master Agent busca el latido del almacén de datos solo cuando el latido de la red no se recibe durante 3 segundos. Porque el latido
- 22. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 22 de la red sigue estando disponible durante toda la falla de almacenamiento, vSphere HA no es necesario para iniciar reinicios de ninguna virtual machine. 04 - Permanent Device Loss*** En este escenario, se produce una condición de pérdida permanente del dispositivo (PDL) porque el almacén de datos PRD se ha desconectado para ESXi-01 y ESXi-02. Los escenarios PDL son poco comunes en configuraciones uniformes y es más probable que ocurran en una configuración vMSC no uniforme. Sin embargo, un escenario de PDL puede ocurrir, por ejemplo, cuando la configuración de un grupo de almacenamiento cambia como en el caso de este escenario descrito. Resultado VM vSphere HA reinicia las VM en de un host a otro. Explicación Cuando se produce la condición PDL, las máquinas virtuales que se ejecutan en el almacén de datos en los hosts ESXi-01 y ESXi-02 mueren instantáneamente. A continuación, vSphere HA reinicia en los hosts del clúster que tienen acceso al almacén de datos, ESXi-03 y ESXi-04 en este escenario. La PDL y la muerte del líder del grupo de VM se pueden observar siguiendo las entradas en el archivo vmkernel.log ubicado en / var / log / en los hosts ESXi.
- 23. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 23 05 - Fallo completo de cómputo en el centro de datos En este escenario, se ha producido un error completo en el centro de datos PRD. Resultado Todas las máquinas virtuales se reinician correctamente en el centro de datos CRD. Explicación El vSphere HA maestro estaba ubicado en el centro de datos de PRD en el momento de la falla completa de cómputo en esa ubicación. Después de que los hosts en el centro de datos CRD detectaron que no se habían recibido latidos de la red, se inició un proceso de elección. En aproximadamente 20 segundos, se elegiría un nuevo maestro de vSphere HA de los hosts restantes. Luego, el nuevo maestro determina qué hosts habían fallado y qué máquinas virtuales se habían visto afectadas por esta falla. Debido a que todos los hosts en el otro sitio habían fallado y todas las máquinas virtuales que residían en ellos se habían visto afectadas, vSphere HA inició el reinicio de todas estas máquinas virtuales. vSphere HA puede iniciar 32 reinicios simultáneos en un solo host, proporcionando una latencia baja de reinicio para la mayoría de los entornos. La única secuencia de orden de inicio proviene de las categorías alta, media y baja para vSphere HA. Esta política debe establecerse por VM. Se determinó que estas políticas se cumplieron; las máquinas virtuales de alta prioridad comenzaron primero, seguidas por las máquinas virtuales de prioridad media y de baja prioridad.
- 24. http://www.ragazome.com / @ragazome Libertad de Conocimiento / Libertad de Aprendizaje 24 06 - Pérdida del centro de datos En este escenario, se simula una falla completa del centro de datos PRD. Resultado Todas las máquinas virtuales se reiniciarán correctamente en el centro de datos CRD. Explicación En este escenario, los hosts en el centro de datos CRD perdieron contacto con el maestro de vSphere HA y eligieron un nuevo maestro de vSphere HA. Debido a que el sistema de almacenamiento había fallado, se tuvo que iniciar un comando de toma de control en el sitio superviviente. Una vez que se inició el comando de toma de control, el nuevo maestro vSphere HA accedió a los archivos por datastore que vSphere HA usa para registrar el conjunto de máquinas virtuales protegidas. El vSphere HA maestro intentó reiniciar las VM que no se ejecutaban en los hosts supervivientes en el centro de datos CRD. En nuestro caso, todas las máquinas virtuales se reiniciarían y estarían completamente accesibles y funcionales nuevamente en el sitio alterno (CRD). Recomiendo revisar y estudiar lo sgte: https://www.hpe.com/h20195/V2/GetPDF.aspx/4AA4-7734ENW.pdf