
Empfohlen
Empfohlen
Weitere ähnliche Inhalte
Andere mochten auch
Andere mochten auch (18)
Ähnlich wie Est3 tutorial3mejorado
Ähnlich wie Est3 tutorial3mejorado (20)
Kürzlich hochgeladen
Kürzlich hochgeladen (20)
Est3 tutorial3mejorado
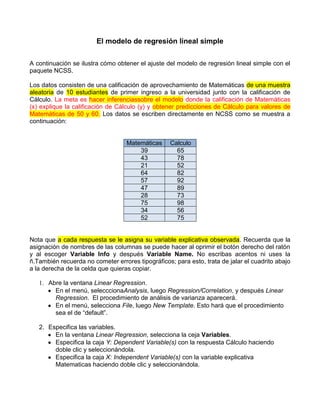
- 1. El modelo de regresión lineal simple A continuación se ilustra cómo obtener el ajuste del modelo de regresión lineal simple con el paquete NCSS. Los datos consisten de una calificación de aprovechamiento de Matemáticas de una muestra aleatoria de 10 estudiantes de primer ingreso a la universidad junto con la calificación de Cálculo. La meta es hacer inferenciassobre el modelo donde la calificación de Matemáticas (x) explique la calificación de Cálculo (y) y obtener predicciones de Cálculo para valores de Matemáticas de 50 y 60. Los datos se escriben directamente en NCSS como se muestra a continuación: Matemáticas Calculo 39 65 43 78 21 52 64 82 57 92 47 89 28 73 75 98 34 56 52 75 Nota que a cada respuesta se le asigna su variable explicativa observada. Recuerda que la asignación de nombres de las columnas se puede hacer al oprimir el botón derecho del ratón y al escoger Variable Info y después Variable Name. No escribas acentos ni uses la ñ.También recuerda no cometer errores tipográficos; para esto, trata de jalar el cuadrito abajo a la derecha de la celda que quieras copiar. 1. Abre la ventana Linear Regression. En el menú, selecccionaAnalysis, luego Regression/Correlation, y después Linear Regression. El procedimiento de análisis de varianza aparecerá. En el menú, selecciona File, luego New Template. Esto hará que el procedimiento sea el de “default”. 2. Especifica las variables. En la ventana Linear Regression, selecciona la ceja Variables. Especifica la caja Y: Dependent Variable(s) con la respuesta Cálculo haciendo doble clic y seleccionándola. Especifica la caja X: Independent Variable(s) con la variable explicativa Matematicas haciendo doble clic y seleccionándola.
- 2. 3. Especifica los artículos del reporte. Especifica las predicciones para valores de X en la caja de Predict Y at these X Values. Los valores se separan con un espacio. Para la ilustración teclea 50 60. Haz clic en la ceja Reportsy selecciona las cantidades que deseas que aparezcan en el análisis. Selecciona todos. 4. Corre el procedimiento. En el menú de Run, selecciona RunProcedure. Aquí obtendrás el siguiente resultado: Linear Regression Report Page/Date/Time 1 22/10/2010 10:32:31 a.m. Database Y = Calculo X = Matematicas Linear RegressionPlotSection Calculo vs Matematicas 100.0 87.5 Calculo 75.0 62.5 50.0 20.0 35.0 50.0 65.0 80.0 Matematicas Run Summary Section Parameter Value Parameter Value Dependent Variable Calculo Rows Processed 10 Independent Variable Matematicas Rows Used in Estimation 10 Frequency Variable None Rows with X Missing 0 Weight Variable None Rows with Freq Missing 0 Intercept 40.7842 Rows Prediction Only 0 Slope 0.7656 Sum of Frequencies 10 R-Squared 0.7052 Sum of Weights 10.0000 Correlation 0.8398 Coefficient of Variation 0.1145 Mean Square Error 75.75323 Square Root of MSE 8.703633
- 3. Linear Regression Report Page/Date/Time 2 22/10/2010 10:32:31 a.m. Y = Calculo X = Matematicas Summary Statement The equation of the straight line relating Calculo and Matematicas is estimated as:(ecuación de regresion) Calculo =(40.7842) + (0.7656)*(Matematicas)using the 10 observations in this dataset. The y-intercept (βo),the estimated value of Calculo when Matematicas is zero, is 40.7842with a standard error of8.5069. The slope (pendiente = β1), the estimated change in Calculo per unit change in Matematicas, is 0.7656 with a standard error of 0.1750. The value of R-Squared ( ), the proportion of the variation inCalculo that can be accounted for by variation in Matematicas, is 0.7052. The correlationbetween Calculo and Matematicas is 0.8398. A significance test that the slope is zero resulted in a t-value of 4.3750. The significancelevel of this t-test is 0.0024. Since(entonces) 0.0024 < 0.0500, the hypothesis that the slope is zero isrejected.(Ho esrechazada) The estimated slope(pendiente) is 0.7656. The lower limit of the 95% = 0.05 confidence interval for the slope is0.3620 and the upper limit is 1.1691 (.3620, 1.1691)= intervalo de confianza para la pendienteβ1. The estimated intercept is 40.7842. The lower limit ofthe 95% confidence interval for the intercept is 21.1673 and the upper limit is 60.4010 (21.1673, 60.4010).= interval de confianza para la ordenada βo Descriptive Statistics Section Parameter Dependent Independent Variable Calculo Matematicas Count 10 10 Mean 76.0000 46.0000 Standard Deviation 15.1144 16.5798 Minimum 52.0000 21.0000 Maximum 98.0000 75.0000
- 4. Linear Regression Report Page/Date/Time 3 22/10/2010 10:32:31 a.m. Database Y = Calculo X = Matematicas Regression Estimation SectionEstimación de la regression. Intercept Slope Parameter B(0) B(1) Regression Coefficients 40.7842 0.7656 Lower 95% Confidence Limit 21.1673 0.3620 Upper 95% Confidence Limit 60.4010 1.1691 Standard Error 8.5069 0.1750 Standardized Coefficient 0.0000 0.8398 T Value 4.7943 4.3750 Prob Level 0.0014 0.0024 Reject H0 (Alpha = 0.0500) Yes Yes (prueba de hipot.) Power (Alpha = 0.0500) 0.9863 0.9677 Regression of Y on X 40.7842 0.7656 Inverse Regression from X on Y 26.0655 1.0855 Orthogonal Regression of Y and X 34.7968 0.8957 Notes: The above report shows the least-squares estimates of the intercept and slope followed by the corresponding standard errors, confidence intervals, and hypothesis tests. Note that these results are based on several assumptions that should be validated before they are used. Estimated Model ( 40.784155214228) + ( .765561843168957) * (Matematicas)
- 5. Linear Regression Report Page/Date/Time 4 22/10/2010 10:32:31 a.m. Database Y = Calculo X = Matematicas BootstrapSection(La idea básica del bootstrap es tratar la muestra como si fuera la población, es una estimación para una población, por supuesto esto intuye a que tenemos una cantidad de datos o individuos más grande, por ello el uso de 50 y 60) ------------ Estimation Results ------------ | ------------ Bootstrap Confidence Limits ---------------- Parameter Estimate | Conf. Level Lower Upper Intercept Original Value 40.7842 | 0.9000 25.9293 54.0720 Bootstrap Mean 40.5099 | 0.9500 22.4576 56.5937 Bias (BM - OV) -0.2743 | 0.9900 15.6398 65.6676 Bias Corrected 41.0584 Standard Error 8.5692 Slope Original Value 0.7656 | 0.9000 0.4716 1.0306 Bootstrap Mean 0.7761 | 0.9500 0.3845 1.0980 Bias (BM - OV) 0.0105 | 0.9900 0.1654 1.2003 Bias Corrected 0.7551 Standard Error 0.1699 Correlation Original Value 0.8398 | 0.9000 0.7338 1.0000 Bootstrap Mean 0.8263 | 0.9500 0.7189 1.0000 Bias (BM - OV) -0.0135 | 0.9900 0.6959 1.0000 Bias Corrected 0.8533 Standard Error 0.0991 R-Squared Original Value 0.7052 | 0.9000 0.5160 1.0000 Bootstrap Mean 0.6925 | 0.9500 0.4875 1.0000 Bias (BM - OV) -0.0127 | 0.9900 0.4428 1.0000 Bias Corrected 0.7179 Standard Error 0.1496 Standard Error of Estimate Original Value 8.7036 | 0.9000 7.5912 12.0945 Bootstrap Mean 7.7916 | 0.9500 7.3206 12.7867 Bias (BM - OV) -0.9121 | 0.9900 6.7540 14.5573 Bias Corrected 9.6157 Standard Error 1.3796 Orthogonal Intercept Original Value 34.7968 | 0.9000 19.6108 52.2714 Bootstrap Mean 33.6771 | 0.9500 14.9337 59.1995 Bias (BM - OV) -1.1197 | 0.9900 9.5260 77.3036 Bias Corrected 35.9165 Standard Error 12.8285 Orthogonal Slope Original Value 0.8957 | 0.9000 0.4728 1.1779 Bootstrap Mean 0.9269 | 0.9500 0.3089 1.2517 Bias (BM - OV) 0.0312 | 0.9900 -0.0725 1.3568 Bias Corrected 0.8646 Standard Error 0.3270
- 6. Linear Regression Report Page/Date/Time 5 22/10/2010 10:32:31 a.m. Database Y = Calculo X = Matematicas Bootstrap Section ------------ Estimation Results ------------ | ------------ Bootstrap Confidence Limits ---------------- Parameter Estimate | Conf. Level Lower Upper Predicted Mean and Confidence Limits of Calculo when Matematicas = 50.0000 Original Value 79.0622 | 0.9000 74.2706 83.1174 Bootstrap Mean 79.3135 | 0.9500 73.1039 83.8730 Bias (BM - OV) 0.2512 | 0.9900 70.4090 85.4468 Bias Corrected 78.8110 Standard Error 2.7673 Predicted Mean and Confidence Limits of Calculo when Matematicas = 60.0000 Original Value 86.7179 | 0.9000 80.4961 91.1953 Bootstrap Mean 87.0742 | 0.9500 78.2697 92.1576 Bias (BM - OV) 0.3563 | 0.9900 73.7842 94.5974 Bias Corrected 86.3616 Standard Error 3.4398 Predicted Value and Prediction Limits of Calculo when Matematicas = 50.0000 Original Value 79.0622 | 0.9000 58.7435 97.2475 Bootstrap Mean 78.7827 | 0.9500 55.4098 100.4693 Bias (BM - OV) -0.2796 | 0.9900 47.9876 109.9048 Bias Corrected 79.3418 Standard Error 12.0660 Predicted Value and Prediction Limits of Calculo when Matematicas = 60.0000 Original Value 86.7179 | 0.9000 66.2959 105.5009 Bootstrap Mean 86.6635 | 0.9500 61.8813 108.2358 Bias (BM - OV) -0.0544 | 0.9900 55.0788 116.5996 Bias Corrected 86.7723 Standard Error 12.2026 Sampling Method = Observation, Confidence Limit Type = Reflection, Number of Samples = 3000. Notes: The main purpose of this report is to present the bootstrap confidence intervals of various parameters. All gross outliers should have been removed. The sample size should be at least(al menos) 50 and the sample should be 'representative' of the population it was drawn from.
- 7. Linear Regression Report Page/Date/Time 6 22/10/2010 10:32:31 a.m. Database Y = Calculo X = Matematicas Correlation and R-Squared Section Spearman Pearson Rank Correlation Correlation Parameter Coefficient R-Squared Coefficient Estimated Value 0.8398 0.7052 0.8788 Lower 95% Conf. Limit (r dist'n) 0.4233 Upper 95% Conf. Limit (r dist'n) 0.9540 Lower 95% Conf. Limit (Fisher's z) 0.4460 0.5578 Upper 95% Conf. Limit (Fisher's z) 0.9612 0.9711 Adjusted (Rbar) 0.6684 T-Value for H0: Rho = 0 4.3750 4.3750 5.2086 Prob Level for H0: Rho = 0 0.0024 0.0024 0.0008 Notes: The confidence interval for the Pearson correlation assumes that X and Y follow the bivariate normal distribution. This is a different assumption from linear regression which assumes that X is fixed and Y is normally distributed. Two confidence intervals are given. The first is based on the exact distribution of Pearson's correlation. The second is based on Fisher's z transformation which approximates the exact distribution using the normal distribution. Why are both provided? Because most books only mention Fisher's approximate method, it will often be needed to do homework. However, the exact methods should be used whenever possible. The confidence limits can be used to test hypotheses about the correlation. To test the hypothesis that rho is a specific value, say r0, check to see if r0 is between the confidence limits. If it is, the null hypothesis that rho = r0 is not rejected.If r0 is outside the limits, the null hypothesis is rejected. Spearman's Rank correlation is calculated by replacing the orginal data with their ranks. This correlation is used when some of the assumptions may be invalid.
- 8. Linear Regression Report Page/Date/Time 7 22/10/2010 10:32:31 a.m. Database Y = Calculo X = Matematicas Analysis of Variance Section (Tabla ANOVA) Sum of Mean Prob Power Source DF Squares Square F-Ratio Level (5%) Intercept 1 57760 57760 Slope 1 1449.974 1449.974 19.1408 0.0024 0.9677 Error 8 606.0259 75.75323 Adj. Total 9 2056 228.4444 Total 10 59816 s = Square Root(75.75323) = 8.703633 Notes: The above report shows the F-Ratio for testing whether the slope is zero, the degrees of freedom, and the mean square error. The mean square error, which estimates the variance of the residuals, isusedextensively in thecalculation of hypothesistests and confidenceintervals.(El error cuadrado medio estima la varianza de los residuals es usado extensamente en el calculo de prueba de hipótesis e intervalos de confianza) Summary Matrices X'X X'X X'Y X'X Inverse X'X Inverse Index 0 1 2 0 1 0 10 460 760 0.9552951 -1.859337E-02 1 460 23634 36854 -1.859337E-02 4.042037E-04 2 (Y'Y) 59816 Determinant 24740 4.042037E-05 Variance - CovarianceMatrix of RegressionCoefficients VC(b) VC(b) Index 0 1 0 72.36669 -1.408508 1 -1.408508 3.061974E-02
- 9. Linear RegressionReport Page/Date/Time 8 22/10/2010 10:32:31 a.m. Database Y = Calculo X = Matematicas Tests of Assumptions Section Is the Assumption Test Prob Reasonable at the 0.2000 Assumption/Test Value Level Level of Significance? Residuals follow Normal Distribution? Shapiro Wilk 0.9162 0.326279 Yes Anderson Darling 0.3987 0.365069 Yes D'AgostinoSkewness 0.5271 0.598118 Yes D'AgostinoKurtosis -1.3574 0.174648 No D'AgostinoOmnibus 2.1204 0.346381 Yes Constant Residual Variance? Modified Levene Test 0.0089 0.927267 Yes Relationship is a Straight Line (Linea recta)? Lack of Linear Fit(Falta de ajuste lineal)F(0, 0) Test0.0000 0.000000 No No Serial Correlation? Evaluate the Serial-Correlation report and the Durbin-Watson test if you have equal-spaced, time series data. Notes: A 'Yes' meansthereis not enoughevidencetomakethisassumptionseemunreasonable (un “yes” quiere decir que no hay suficiente evidencia para hacer que la suposición parezca razonable). This lack of evidence may be because the sample size is too small, the assumptions ofthe test itself are not met, ortheassumptionisvalid(esta falta de evidencia puede ser debido a que el tamaño de la muestra es muy pequeño, los supuestos de la prueba por si mismos, no se cumplen, o el supuesto es valido.. A 'No' meansthethattheassumptionis not reasonable (un "No " significa queelquelasuposición noesrazonable). However, since these testsare related to sample size, you should assess the role of sample size in the testsby also evaluating the appropriate plots and graphs. A large dataset (say N > 500) will often fail at least one of the normality tests because it is hard to find a large dataset that is perfectly normal. Normality and Constant Residual Variance: Possible remedies for the failure of these assumptions include using a transformation of Y such as the log or square root, correcting data-recording errors found by looking into outliers, adding additional independent variables, using robust regression, or using bootstrap methods. Straight-Line: Possible remedies for the failure of this assumption include using nonlinear regression or polynomial regression.
- 10. Linear Regression Report Page/Date/Time 9 22/10/2010 10:32:31 a.m. Database Y = Calculo X = Matematicas Serial Correlation of Residuals Section Serial Serial Serial Lag Correlation Lag Correlation Lag Correlation 1 0.3611 9 17 2 -0.2875 10 18 3 -0.4307 11 19 4 -0.3158 12 20 5 13 21 6 14 22 7 15 23 8 16 24 Notes: Each serial correlation is the Pearson correlation calculated between the original series of residuals and the residuals lagged the specified number of periods. This feature of residuals is only meaningfull for data obtained sorted in time order. One of the assumptions is that none of these serial correlations is significant. Starred correlations are those for which |Fisher's Z| > 1.645 which indicates whether the serial correlation is 'large.' If serial correlation is detected in time series data, the remedy is to account for it either by replacing Y with first differences or by fitting the serial pattern using a method such as that proposed by Cochrane and Orcutt. Durbin-Watson Test For Serial Correlation Did the Test Reject Parameter Value H0: Rho(1) = 0? Durbin-Watson Value 1.1737 Prob. Level: Positive Serial Correlation 0.1078 Yes Prob. Level: Negative Serial Correlation 0.9474 No Notes: The Durbin-Watson test was created to test for first-order serial correlation in regression data taken over time. If the rows of your dataset do not represent successive time periods, you should ignore this test. This report gives the probability of rejecting the null hypothesis of no first-order serial correlation. Possible remedies for serial correlation were given in the Notes to the Serial Correlation report, above.
- 11. Linear Regression Report Page/Date/Time 10 22/10/2010 10:32:31 a.m. Database Y = Calculo X = Matematicas PRESS Section From From PRESS Regular Parameter Residuals Residuals Sum of Squared Residuals 888.5684 606.0259 Sum of |Residuals| 84.87208 69.78011 R-Squared 0.5678 0.7052 Notes: A PRESS residual is found by estimating the regression equation without the observation, predicting the dependent variable, and subtracting the predicted value from the actual value. The PRESS values are calculated from these PRESS residuals. The Regular values are the corresponding calculations based on the regular residuals. The PRESS values are often used to compare models in a multiple-regression variable selection. They show how well the model predicts observations that were not used in the estimation. Predicted Values and Confidence Limits Section Predicted Standard Lower 95% Upper 95% Matematicas Calculo Error Confidence Confidence (X) (Yhat|X) of Yhat Limit of Y|X Limit of Y|X 50.0000 79.0622 2.8399 72.5133 85.6112 60.0000 86.7179 3.6847 78.2210 95.2147 The confidence interval estimates the mean of the Y values in a large sample of individuals with this value of X. The interval is only accurate if all of the linear regression assumptions are valid. Predicted Values and Prediction Limits Section Predicted Standard Lower 95% Upper 95% Matematicas Calculo Error Prediction Prediction (X) (Yhat|X) of Yhat Limit of Y|X Limit of Y|X 50.0000 79.0622 9.1552 57.9502 100.1743 60.0000 86.7179 9.4515 64.9228 108.5130 The prediction interval estimates the predicted value of Y for a single individual with this value of X. The interval is only accurate if all of the linear regression assumptions are valid.
- 12. Linear Regression Report Page/Date/Time 11 22/10/2010 10:32:31 a.m. Database Y = Calculo X = Matematicas Residual Plots Section Residuals of Calculo vs Matematicas |Residuals of Calculo| vs Matematicas 15.0 14.0 |Residuals of Calculo| Residuals of Calculo 7.5 10.5 0.0 7.0 -7.5 3.5 -15.0 0.0 20.0 35.0 50.0 65.0 80.0 20.0 35.0 50.0 65.0 80.0 Matematicas Matematicas RStudent of Calculo vs Matematicas Residuals Calculo vs Row 2.0 15.0 Residuals of Calculo 1.1 7.5 RStudent of Calculo 0.3 0.0 -0.6 -7.5 -1.5 -15.0 20.0 35.0 50.0 65.0 80.0 0.0 3.0 6.0 9.0 12.0 Matematicas Row Serial Correlation of Residuals Histogram of Residuals of Calculo 15.0 5.0 Residuals of Calculo 7.5 3.8 Count 0.0 2.5 -7.5 1.3 -15.0 0.0 -15.0 -7.5 0.0 7.5 15.0 -15.0 -7.5 0.0 7.5 15.0 Lagged Residuals of Calculo Residuals of Calculo
- 13. Linear Regression Report Page/Date/Time 12 22/10/2010 10:32:31 a.m. Database Y = Calculo X = Matematicas Normal Probability Plot of Residuals of Calculo 15.0 Residuals of Calculo 7.5 0.0 -7.5 -15.0 -2.0 -1.0 0.0 1.0 2.0 Expected Normals Original Data Section Predicted Matematicas Calculo Calculo Row (X) (Y) (Yhat|X) Residual 1 39.0000 65.0000 70.6411 -5.6411 2 43.0000 78.0000 73.7033 4.2967 3 21.0000 52.0000 56.8610 -4.8610 4 64.0000 82.0000 89.7801 -7.7801 5 57.0000 92.0000 84.4212 7.5788 6 47.0000 89.0000 76.7656 12.2344 7 28.0000 73.0000 62.2199 10.7801 8 75.0000 98.0000 98.2013 -0.2013 9 34.0000 56.0000 66.8133 -10.8133 10 52.0000 75.0000 80.5934 -5.5934 This report provides a data list that may be used to verify whether the correct variables were selected.
- 14. Linear Regression Report Page/Date/Time 13 22/10/2010 10:32:31 a.m. Database Y = Calculo X = Matematicas Predicted Values and Confidence Limits of Means Predicted Standard Lower 95% Upper 95% Matematicas Calculo Calculo Error Conf. Limit Conf. Limit Row (X) (Y) (Yhat|X) of Yhat of Y Mean|X of Y Mean|X 1 39.0000 65.0000 70.6411 3.0126 63.6940 77.5881 2 43.0000 78.0000 73.7033 2.8019 67.2420 80.1646 3 21.0000 52.0000 56.8610 5.1684 44.9425 68.7794 4 64.0000 82.0000 89.7801 4.1828 80.1345 99.4258 5 57.0000 92.0000 84.4212 3.3586 76.6762 92.1662 6 47.0000 89.0000 76.7656 2.7579 70.4059 83.1253 7 28.0000 73.0000 62.2199 4.1828 52.5742 71.8655 8 75.0000 98.0000 98.2013 5.7729 84.8889 111.5137 9 34.0000 56.0000 66.8133 3.4619 58.8302 74.7964 10 52.0000 75.0000 80.5934 2.9458 73.8004 87.3864 The confidence interval estimates the mean of the Y values in a large sample of individuals with this value of X. The interval is only accurate if all of the linear regression assumptions are valid. Predicted Values and Prediction Limits Predicted Standard Lower 95% Upper 95% Matematicas Calculo Calculo Error Prediction Prediction Row (X) (Y) (Yhat|X) of Yhat Limit of Y|X Limit of Y|X 1 39.0000 65.0000 70.6411 9.2103 49.4022 91.8800 2 43.0000 78.0000 73.7033 9.1435 52.6183 94.7883 3 21.0000 52.0000 56.8610 10.1225 33.5183 80.2036 4 64.0000 82.0000 89.7801 9.6566 67.5120 112.0482 5 57.0000 92.0000 84.4212 9.3292 62.9081 105.9343 6 47.0000 89.0000 76.7656 9.1301 55.7115 97.8197 7 28.0000 73.0000 62.2199 9.6566 39.9518 84.4880 8 75.0000 98.0000 98.2013 10.4441 74.1171 122.2855 9 34.0000 56.0000 66.8133 9.3668 45.2133 88.4132 10 52.0000 75.0000 80.5934 9.1886 59.4044 101.7824 The prediction interval estimates the predicted value of Y for a single individual with this value of X. The interval is only accurate if all of the linear regression assumptions are valid.Los intervalos de predicción estiman la predicción del valor de Y para un único valor de x (predicción puntual).
- 15. Linear Regression Report Page/Date/Time 14 22/10/2010 10:32:31 a.m. Database Y = Calculo X = Matematicas Working-Hotelling Simultaneous Confidence Band Predicted Standard Lower 95% Upper 95% Matematicas Calculo Calculo Error Conf. Band Conf. Band Row (X) (Y) (Yhat|X) of Yhat of Y Mean|X of Y Mean|X 1 39.0000 65.0000 70.6411 3.0126 43.7750 97.5072 2 43.0000 78.0000 73.7033 2.8019 48.7157 98.6909 3 21.0000 52.0000 56.8610 5.1684 10.7692 102.9527 4 64.0000 82.0000 89.7801 4.1828 52.4778 127.0824 5 57.0000 92.0000 84.4212 3.3586 54.4692 114.3731 6 47.0000 89.0000 76.7656 2.7579 52.1709 101.3602 7 28.0000 73.0000 62.2199 4.1828 24.9176 99.5222 8 75.0000 98.0000 98.2013 5.7729 46.7188 149.6838 9 34.0000 56.0000 66.8133 3.4619 35.9405 97.6860 10 52.0000 75.0000 80.5934 2.9458 54.3231 106.8637 This is a confidence band for the regression line for all possible values of X from -infinity to + infinity. The confidence coefficient is the proportion of time that this procedure yields a band the includes the true regression line when a large number of samples are taken using the same X values as in this sample. Residual Section Predicted Percent Matematicas Calculo Calculo Standardized Absolute Row (X) (Y) (Yhat|X) Residual Residual Error 1 39.0000 65.0000 70.6411 -5.6411 -0.6908 8.6786 2 43.0000 78.0000 73.7033 4.2967 0.5214 5.5086 3 21.0000 52.0000 56.8610 -4.8610 -0.6941 9.3480 4 64.0000 82.0000 89.7801 -7.7801 -1.0193 9.4879 5 57.0000 92.0000 84.4212 7.5788 0.9439 8.2378 6 47.0000 89.0000 76.7656 12.2344 1.4820 13.7466 7 28.0000 73.0000 62.2199 10.7801 1.4124 14.7673 8 75.0000 98.0000 98.2013 -0.2013 -0.0309 0.2054 9 34.0000 56.0000 66.8133 -10.8133 -1.3541 19.3094 10 52.0000 75.0000 80.5934 -5.5934 -0.6830 7.4578 The residual is the difference between the actual and the predicted Y values. The formula is Residual = Y - Yhat. The Percent Absolute Error is the 100 |Residual| / Y.
- 16. Linear Regression Report Page/Date/Time 15 22/10/2010 10:32:31 a.m. Database Y = Calculo X = Matematicas Residual Diagnostics Section Matematicas Hat Row (X) Residual RStudent Diagonal Cook's D MSEi 1 39.0000 -5.6411 -0.6664 0.1198 0.0325 81.4104 2 43.0000 4.2967 0.4963 0.1036 0.0157 83.6328 3 21.0000 -4.8610 -0.6698 0.3526 0.1312 81.3609 4 64.0000 -7.7801 -1.0222 0.2310 0.1560 75.3310 5 57.0000 7.5788 0.9366 0.1489 0.0779 76.9340 6 47.0000 12.2344 1.6277 0.1004 0.1226 62.8055 7 28.0000 10.7801 1.5249 0.2310 0.2995 64.9877 8 75.0000 -0.2013 *-0.0289 0.4399 0.0004 86.5648 9 34.0000 -10.8133 -1.4427 0.1582 0.1723 66.7321 10 52.0000 -5.5934 -0.6583 0.1146 0.0302 81.5275 Outliers are rows that are separated from the rest of the data. Influential rows are those whose omission results in a relatively large change in the results. This report lets you see both. An outlier may be defined as a row in which |RStudent| > 2. A moderately influential row is one with aCooksD> 0.5. A heavily influential row is one with a CooksD> 1. MSEi is the value of the Mean Square Error (the average of the sum of squared residuals) calculated with each row omitted. Leave One Row Out Section Row RStudent DFFITS Cook's D CovRatio DFBETAS(0) DFBETAS(1) 1 -0.6664 -0.2459 0.0325 1.3121 -0.1673 0.1000 2 0.4963 0.1687 0.0157 1.3598 0.0835 -0.0316 3 -0.6698 -0.4943 0.1312 * 1.7819 -0.4811 0.4184 4 -1.0222 -0.5602 0.1560 1.2859 0.2799 -0.4218 5 0.9366 0.3918 0.0779 1.2119 -0.1086 0.2245 6 1.6277 0.5438 0.1226 0.7641 0.1429 0.0345 7 1.5249 0.8357 0.2995 0.9570 0.7733 -0.6293 8 -0.0289 -0.0256 0.0004 * 2.3315 0.0174 -0.0225 9 -1.4427 -0.6255 0.1723 0.9219 -0.5199 0.3794 10 -0.6583 -0.2368 0.0302 1.3081 0.0083 -0.0844 Each column gives the impact on some aspect of the linear regression of omitting that row. RStudent represents the size of the residual. DFFITS represents the change in the fitted value of a row. Cook's D summarizes the change in the fitted values of all rows. CovRatio represents the amount of change in the determinant of the covariance matrix. DFBETAS(0) and DFBETAS(1) give the amount of change in the intercept and slope.
- 17. Linear Regression Report Page/Date/Time 16 22/10/2010 10:32:31 a.m. Database Y = Calculo X = Matematicas Outlier Detection Chart Matematicas Standardized Row (X) Residual Residual RStudent 1 39.0000 -5.6411 |||............ -0.6908 ||............. -0.6664 |.............. 2 43.0000 4.2967 ||............. 0.5214 ||............. 0.4963 |.............. 3 21.0000 -4.8610 |||............ -0.6941 ||............. -0.6698 |.............. 4 64.0000 -7.7801 |||||.......... -1.0193 ||||........... -1.0222 |.............. 5 57.0000 7.5788 ||||........... 0.9439 |||............ 0.9366 |.............. 6 47.0000 12.2344 |||||||........ 1.4820 ||||||......... 1.6277 |.............. 7 28.0000 10.7801 ||||||......... 1.4124 |||||.......... 1.5249 |.............. 8 75.0000 -0.2013 |.............. -0.0309 |.............. -0.0289 |.............. 9 34.0000 -10.8133 ||||||......... -1.3541 |||||.......... -1.4427 |.............. 10 52.0000 -5.5934 |||............ -0.6830 ||............. -0.6583 |.............. Outliers are rows that are separated from the rest of the data. Since outliers can have dramatic effects on the results, corrective action, such as elimination, must be carefully considered. Outlying rows should not be automatically be removed unless a good reason for their removal can be given. An outlier may be defined as a row in which |RStudent| > 2. Rows with this characteristic have been starred. Influence Detection Chart Matematicas Row (X) DFFITS Cook's D DFBETAS(1) 1 39.0000 -0.2459 |.............. 0.0325 |.............. 0.1000 |.............. 2 43.0000 0.1687 |.............. 0.0157 |.............. -0.0316 |.............. 3 21.0000 -0.4943 |.............. 0.1312 |.............. 0.4184 |.............. 4 64.0000 -0.5602 |.............. 0.1560 |.............. -0.4218 |.............. 5 57.0000 0.3918 |.............. 0.0779 |.............. 0.2245 |.............. 6 47.0000 0.5438 |.............. 0.1226 |.............. 0.0345 |.............. 7 28.0000 0.8357 |.............. 0.2995 ||............. -0.6293 |.............. 8 75.0000 -0.0256 |.............. 0.0004 |.............. -0.0225 |.............. 9 34.0000 -0.6255 |.............. 0.1723 |.............. 0.3794 |.............. 10 52.0000 -0.2368 |.............. 0.0302 |.............. -0.0844 |.............. Influential rows are those whose omission results in a relatively large change in the results. They are not necessarily harmful. However, they will distort the results if they are also outliers. The impact of influential rows should be studied very carefully. Their accuracy should be double-checked. DFFITS is the standardized change in Yhat when the row is omitted. A row is influential when DFFITS > 1 for small datasets (N < 30) or when DFFITS > 2*SQR(1/N) for medium to large datasets. Cook's D gives the influence of each row on the Yhats of all the rows. Cook suggests investigating all rows having a Cook's D > 0.5. Rows in which Cook's D > 1.0 are very influential. DFBETAS(1) is the standardized change in the slope when this row is omitted. DFBETAS(1) > 1 for small datasets (N < 30) and DFBETAS(1) > 2/SQR(N) for medium and large datasets are indicative of influential rows.
- 18. Linear Regression Report Page/Date/Time 17 22/10/2010 10:32:31 a.m. Database Y = Calculo X = Matematicas Outlier & Influence Chart Hat Matematicas RStudent Cooks D Diagonal Row (X) (Outlier) (Influence) (Leverage) 1 39.0000 -0.6664 |.............. 0.0325 |.............. 0.1198 |.............. 2 43.0000 0.4963 |.............. 0.0157 |.............. 0.1036 |.............. 3 21.0000 -0.6698 |.............. 0.1312 |.............. 0.3526 |||||||||||.... 4 64.0000 -1.0222 |.............. 0.1560 |.............. 0.2310 |||||.......... 5 57.0000 0.9366 |.............. 0.0779 |.............. 0.1489 ||............. 6 47.0000 1.6277 |.............. 0.1226 |.............. 0.1004 |.............. 7 28.0000 1.5249 |.............. 0.2995 ||............. 0.2310 |||||.......... 8 75.0000 -0.0289 |.............. 0.0004 |.............. 0.4399 ||||||||||||||| 9 34.0000 -1.4427 |.............. 0.1723 |.............. 0.1582 ||............. 10 52.0000 -0.6583 |.............. 0.0302 |.............. 0.1146 |.............. Outliers are rows that are separated from the rest of the data. Influential rows are those whose omission results in a relatively large change in the results. This report lets you see both. An outlier may be defined as a row in which |RStudent| > 2. A moderately influential row is one with aCooksD> 0.5. A heavily influential row is one with a CooksD> 1. Inverse Prediction of X Means Predicted Lower 95% Upper 95% Calculo Matematicas Matematicas Conf. Limit Conf. Limit Row (Y) (X) (Xhat|Y) X-Xhat|Y of X Mean|Y of X Mean|Y 1 65.0000 39.0000 31.6315 7.3685 11.7810 40.4270 2 78.0000 43.0000 48.6125 -5.6125 39.6772 59.5577 3 52.0000 21.0000 14.6505 6.3495 -22.2829 27.4640 4 82.0000 64.0000 53.8374 10.1626 45.5434 68.1613 5 92.0000 57.0000 66.8997 -9.8997 56.8331 93.0462 6 89.0000 47.0000 62.9810 -15.9810 53.7409 85.2860 7 73.0000 28.0000 42.0813 -14.0813 30.4075 50.7401 8 98.0000 75.0000 74.7371 0.2629 62.6604 108.9237 9 56.0000 34.0000 19.8754 14.1246 -11.5925 31.2433 10 75.0000 52.0000 44.6938 7.3062 34.3891 53.9934 This confidence interval estimates the mean of X in a large sample of individuals with this value of Y. This method of inverse prediction is also called 'calibration.'
- 19. Linear Regression Report Page/Date/Time 18 22/10/2010 10:32:31 a.m. Database Y = Calculo X = Matematicas Inverse Prediction of X Individuals Predicted Lower 95% Upper 95% Calculo Matematicas Matematicas Prediction Prediction Row (Y) (X) (Xhat|Y) X-Xhat|Y Limit of X|Y Limit of X|Y 1 65.0000 39.0000 31.6315 7.3685 -7.9089 60.1169 2 78.0000 43.0000 48.6125 -5.6125 17.2054 82.0295 3 52.0000 21.0000 14.6505 6.3495 -37.0380 42.2191 4 82.0000 64.0000 53.8374 10.1626 23.9947 89.7100 5 92.0000 57.0000 66.8997 -9.8997 39.1685 110.7108 6 89.0000 47.0000 62.9810 -15.9810 34.8652 104.1618 7 73.0000 28.0000 42.0813 -14.0813 8.0918 73.0559 8 98.0000 75.0000 74.7371 0.2629 47.2329 124.3511 9 56.0000 34.0000 19.8754 14.1246 -27.7306 47.3815 10 75.0000 52.0000 44.6938 7.3062 11.8213 76.5612 This prediction interval estimates the predicted value of X for a single individual with this value of Y. This method of inverse prediction is also called 'calibration.'