Netflix Play API: Why we built an evolutionary architecture
•Als PPTX, PDF herunterladen•
11 gefällt mir•6,835 views

For your next re-architecture, consider building a Evolutionary Architecture, with strong focus on Identity, Type1/Type2 Decisions and Fitness Functions. This talk goes through the journey of re-architecting one of the most critical services at Netflix.

Empfohlen
Empfohlen
Weitere ähnliche Inhalte
Was ist angesagt?
Was ist angesagt? (20)
Ähnlich wie Netflix Play API: Why we built an evolutionary architecture
Ähnlich wie Netflix Play API: Why we built an evolutionary architecture (20)
Kürzlich hochgeladen
Kürzlich hochgeladen (20)
Netflix Play API: Why we built an evolutionary architecture
- 3. Headline Suudhan Rangarajan (@suudhan) Senior Software Engineer Play API Why we built an Evolutionary Architecture
- 4. Previous Architecture Workflow Sign-up Content Discovery Playback API Service ← Services hosted in AWS →Devices Domain specific Microservices API Proxy Service
- 5. Signup Workflow ← Services hosted in AWS →Devices Signup API Sign-up Content Discovery Playback Domain specific Microservices API Proxy Service API Service
- 6. Content Discovery Workflow ← Services hosted in AWS →Devices Discovery API Sign-up Content Discovery Playback Domain specific Microservices API Proxy Service API Service
- 7. Playback Workflow ← Services hosted in AWS →Devices Playback API Sign-up Content Discovery Playback Domain specific Microservices API Proxy Service API Service
- 8. Previous Architecture ← Services hosted in AWS →Devices Signup API Discovery API Playback API Sign-up Content Discovery Playback Domain specific Microservices API Proxy Service API Service
- 11. Start with WHY: Ask why your service exists
- 12. Lead the Internet TV revolution to entertain billions of people across the world P Maximize user engagement of Netflix customer from signup to streaming P Enable acquisition, discovery, playback functionality 24/7
- 13. API Identity: Deliver Acquisition, Discovery and Playback functions with high availability
- 14. Single Responsibility Principle: Be wary of multiple-identities rolled up into a single service
- 15. One API Service Signup API Discovery API Playback API Signup API Discovery API Playback API API Service Per function Previous Architecture Current Architecture
- 16. Lead the Internet TV revolution to entertain billions of people across the world P Maximize user engagement of Netflix customer from signup to streaming P Enable non-member, discovery, playback functionality 24/7 P Deliver Playback Lifecycle 24/7
- 17. Decide best playback experience Track events to measure playback experience Authorize playback experience Playback API Devices API Proxy Service
- 19. Decide best playback experience Track events to measure playback experience Authorize playback experience Devices API Proxy Service High Coupling, Low Evolvability
- 20. Play API Identity: Orchestrate Playback Lifecycle with stable abstractions
- 21. Guiding Principle: We believe in a simple singular identity for our services. The identity relates to and complements the identities of the company, organization, team and its peer services
- 23. “Some decisions are consequential and irreversible or nearly irreversible – one-way doors – and these decisions must be made methodically, carefully, slowly, with great deliberation and consultation [...] We can call these Type 1 decisions…” Quote from Jeff Bezos
- 24. “...But most decisions aren’t like that – they are changeable, reversible – they’re two-way doors. If you’ve made a suboptimal Type 2 decision, you don’t have to live with the consequences for that long [...] Type 2 decisions can and should be made quickly by high judgment individuals or small groups.” Quote from Jeff Bezos
- 25. Three Type 1 Decisions to Consider Synchronous & Asynchronous Data ArchitectureShared libraries & Communication
- 26. Two types of Shared Libraries Play API Service Utilities cache Metrics Shared Libraries with common functions Client Libraries used for inter- service communications Client 1 Client 2 Client 3
- 27. Shared Libraries often introduce some form of coupling between Services, so we need to be intentional about appropriate coupling
- 28. “Thick” shared libraries with 100s of dependent libraries (e.g. utilities jar) Previous Architecture 1) Binary Coupling
- 29. Hundreds of shared libraries spanning services across network boundaries Previous Architecture Binary coupling => Distributed Monolith Utilities Utilities Utilities Service1 Service2 Service3
- 30. “The evils of too much coupling between services are far worse than the problems caused by code duplication” - Sam Newman (Building Microservices)
- 31. Play API Service Playback Decision Service Playback Decision Client Previous Architecture
- 32. Requests Per Second of API Service Increase in Latencies from the API Service Execution of Fallback via Play Decision Client Clients with heavy Fallbacks
- 33. Play API Service Playback Decision Service Playback Decision Client Previous Architecture 2) Operational Coupling
- 34. “Operational Coupling” might be an ok choice, if some services/teams are not yet ready to own and operate a highly available service.
- 35. Many of the client libraries had the potential to bring down the API Service Previous Architecture Operational Coupling impacts Availability Play API Service
- 36. Play API Service Playback Decisions Serviceclient Java Java Previous Architecture 3) Language Coupling
- 37. Play API Service client REST over HTTP 1.1 ● Unidirectional (Request/ Response type APIs) Previous Architecture Inter Service Communication Playback Decisions Service Jersey Framework
- 38. Requirements Operationally “thin” Clients No or limited shared libraries Auto-generated clients for Polyglot support Bi-Directional Communication
- 39. ● At Netflix, most use-cases were modelled as Request/Response ○ REST was a simple and easy way of communicating between services; so choice of REST was more incidental rather than intentional ● Most of the services were not following RESTful principles. ○ The URL didn’t represent a unique resource, instead the parameters passed in the call determined the response - effectively made them a RPC call ● So we were agnostic to REST vs RPC as long as it meets our requirements REST vs RPC
- 41. Previous Architecture Current Architecture Play API Service Playback Decisions Playback Authorize Playback Events Playback Decisions Playback Authorize Playback Events 1) Operationally Coupled Clients 2) High Binary Coupling 3) Only Java 4) Unidirectional communication Play API Service 1) Minimal Operational Coupling 2) Limited Binary Coupling 3) Beyond Java 4) Beyond Request/ Response gRPC/ HTTP2REST/ HTTP1
- 42. Consider “thin” auto-generated clients with bi-directional communication and minimize code reuse across service boundaries
- 43. Three Type 1 Decisions to Consider Synchronous vs Asynchronous Data ArchitectureShared libraries & Communication
- 44. PlayData getPlayData(string customerId, string titleId, string deviceId){ CustomerInfo custInfo = getCustomerInfo(customerId); DeviceInfo deviceInfo = getDeviceInfo(deviceId); PlayData playdata = decidePlayData(custInfo, deviceInfo, titleId); return playdata; }
- 45. Request Handler Thread pool Client Thread pool Typical Synchronous Architecture
- 46. Request Handler Thread pool Client Thread pool getPlayData getCustomerInfo decidePlayData Return One thread per request Typical Synchronous Architecture getDeviceInfo Customer Service Device Service Play Data Decision Service
- 47. Request Handler Thread pool Client Thread pool getPlayData getCustomerInfo decidePlayData Return One thread per request Typical Synchronous Architecture getDeviceInfo Customer Service Device Service Play Data Decision Service Blocking Request Handler Blocking Client I/O
- 48. Request Handler Thread pool Client Thread pool getPlayData getCustomerInfo decidePlayData Return One thread per request Typical Synchronous Architecture getDeviceInfo Blocking Request Handler Blocking Client I/O Works for Simple Request/Response Works for Limited Clients
- 49. Beyond Request/Response One Request - One Response Request Play-data for Title X Receive Play-data for Title X One Request - Stream Response Request Play-data for Titles X,Y,Z Receive Play-data for Title X Receive Play-data for Title Y Receive Play-data for Title Z Stream Request - One Response Request Play-data for Title X Request Play-data for Title Y Request Play-data for Title Z Receive Play-data for Titles X,Y,Z Stream Request - Stream Response Request Play-data for Title X Request Play-data for Title Y Receive Play-data for Title X Get Play-data for Title Z Receive Play-data for Title Y Receive Play-data for Title Z
- 50. Request/Response Event Loop Outgoing Event Loop per client Worker Threads Asynchronous Architecture
- 51. PlayData getPlayData(string customerId, string titleId, string deviceId){ Zip(getCustomerInfo(customerId), getDeviceInfo(deviceId), (custInfo, deviceInfo) -> return decidePlayData(custInfo, deviceInfo, titleId) ); }
- 52. Request/Response Event Loop Outgoing Event Loop per clientWorkflow spans many worker threads Asynchronous Architecture Customer Service Device Service PlayData Service getPlayData
- 53. Request/Response Event Loop Outgoing Event Loop per clientWorkflow spans many worker threads Asynchronous Architecture Customer Service Device Service PlayData Service getCustomerInfo
- 54. Request/Response Event Loop Outgoing Event Loop per clientWorkflow spans many worker threads Asynchronous Architecture Customer Service Device Service PlayData Service getDeviceInfo
- 55. Request/Response Event Loop Outgoing Event Loop per clientWorkflow spans many worker threads Asynchronous Architecture Customer Service Device Service PlayData Service decidePlayData
- 56. Request/Response Event Loop Outgoing Event Loop per clientWorkflow spans many worker threads Asynchronous Architecture Customer Service Device Service PlayData Service zip
- 57. ● All context is passed as messages from one processing unit to another. ● If we need to follow and reason about a request, we need to build tools to capture and reassemble the order of execution units ● None of the calls can block Workflow spans multiple threads
- 58. Request/Response Event Loop Outgoing Event Loop per client Worker Threads Asynchronous Architecture Asynchronous Request Handler Non-Blocking I/O
- 59. Synchrony Ask: Do you really have a need beyond Request/Response?
- 60. Network Event Loop Outgoing Event Loop per client Dedicated thread Synchronous Execution + Asynchronous I/O Blocking Request Handler Non-Blocking I/O Current Architecture getPlayData getCustomerInfo decidePlayData Return getDeviceInfo
- 61. If most of your APIs fit the Request/Response pattern, consider a synchronous request handler, with nonblocking I/O
- 62. Three Type 1 Decisions to Consider Synchrony Data ArchitectureShared libraries & Communication
- 63. Without an intentional Data Architecture, Data becomes its own monolith
- 64. 4 GB 1 GB 2 GB 400 MB 600 MB API Service ← Multiple Data sources loaded in memory → ←MemoryLoad→ Previous Architecture What a Data Monolith looks like
- 65. 4 GB 1 GB 2 GB 400 MB 600 MB API Service Very small percentage of data actually accessed Previous Architecture What a Data Monolith looks like
- 66. API Service Each Data Source models gets coupled across classes and libraries Previous Architecture What a Data Monolith looks like
- 67. API Service Unpredictable Performance Characteristics Data Update CPU Utilization Previous Architecture What a Data Monolith looks like
- 68. What a Data Monolith looks like API Service Potential to bring down the service Data Update Netflix was down Previous Architecture
- 69. "All problems in computer science can be solved by another level of indirection." David Wheeler (World’s first Comp Sci PhD)
- 70. Current Architecture Data Source Data Source Data Source Data Source Data Source Data Loader Data Service Play API Service Data Store Materialized View
- 71. Current Architecture Data Source Data Source Data Source Data Source Data Source Data Loader Data Service Uses only the data it needs Predictable Operational Characteristics Reduced Dependency chain Data Store Play API Service Materialized View
- 72. At the very least, ensure that data sources are accessed via a layer of abstraction, so that it leaves room for extension later
- 73. Three Type 1 Decisions to Consider Synchrony Data ArchitectureShared libraries & Communication
- 74. For Type 2 decisions, choose a path, experiment and iterate
- 75. Guiding Principle: Identify your Type 1 and Type 2 decisions; Spend 80% of your time debating and aligning on Type 1 Decisions
- 77. An Evolutionary Architecture supports guided and incremental change as first principle among multiple dimensions - ThoughtWorks
- 78. Choosing a microservices architecture allows to evolve across multiple dimensions
- 79. How evolvable are the Type 1 decisions Change Play API Current Architecture Previous Architecture Asynchronous? Polyglot services? Bidirectional APIs? Additional Data Sources? Known Unknowns
- 80. Potential Type 1 decisions in the future? Change Play API Current Architecture Previous Architecture Containers? Serverless? ? ? And we fully expect that there will be Unknown Unknowns
- 81. As we evolve, how to ensure we are not breaking our original goals?
- 82. Use Fitness Functions to guide change
- 83. High Availability Low Latency Simplicity Reliability High Throughput Observability Developer Productivity Continuous Integration Scalable Evolvability 1 2 3 4
- 84. Why Simplicity over Reliability? Increase in Operational Complexity Reliable Fallback when service is down
- 85. Why Scalability over Throughput? New instances were added Increase in Errors due to cache warming
- 86. Why Observability over Latency? Decrease in latency by using a fully async executor Cost of Async: Loss in Observability
- 87. Four 9s of availability Clients with less than “n” dependencies P99 latency under ZCPU to RPS ratio under Y Merge to Deploy in under X minutes 1 2 3
- 88. Guiding Principle: Define Fitness functions to act as your guide for architectural evolution
- 89. Previous Architecture Current Architecture Operational Coupling Binary Coupling Only Java Synchronous communication Data Monolith Operational Isolation No Binary Coupling Beyond Java Asynchronous communication Explicit Data Architecture Guided Fitness Functions Multiple Identities Singular Identities
- 91. Identity Type 1/2 Decisions Evolvability Build a Evolutionary Architecture
Hinweis der Redaktion
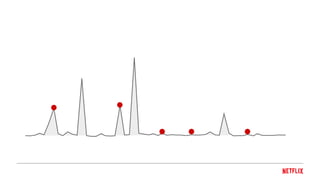
- Let’s begin by looking at a couple of graphs. This graph shows the times in which Netflix had some form of outage in the past one year. The peaks indicate how many customers were impacted and the breadth indicates how long the impact lasted. Out of these, all the red dots roughly indicate the times when our API service was directly or indirectly a contributing factor to the outage.
- Let's take a look at another graph. This graph shows the rate of increase in requests to our API Service. As you can see, it has inflection points when we launched major innovative features. How many of you have noticed that when you browse netflix content, a helpful video plays in the top billboard area? That was the Video Previews feature. So, when we launched Video Previews, we saw a significant shift in the rate of increase in our RPS. Now, I want you folks to imagine this. You own and operate the API service; it is an aggregator service which delivers all traffic to netflix; One one hand, the requests are growing exponentially, and on the other, the service’s availability numbers are not where we want it to be! Now you are tasked with the responsibility of re-architecting this service. Where do you begin?
- The goal of this talk is to provide you with a framework to think and reason about how to make such a big re-architectural change
- Before we dive into these principles, let’s look at our previous architecture workflow. We have a 1000s of device types which support the Netflix application. And millions of such devices interact with the host of services run and operated by various teams at Netflix. All requests first come to the API Proxy Service, whose function is to provide routing, monitoring, and protocol termination for all requests. Then we have the API Service which delivers all functionality necessary to run the Netflix application. Behind the API Service, we have 100s of microservices each with its domain specific responsibilities.
- For instance, let’s say we have a new customer interested in signing up for Netflix, she goes to a device of her choice, and when she launches the Netflix application, requests flow to API Service. The signup API delivers the sign-up workflow by coordinating with customer, billing, and signup services.
- Once she is logged in, she is greeted with rows and rows of Netflix Content, personalized to her taste. This functionality is delivered by a set of Discovery API, coordinating with Personalization, Content Metadata, and Discovery services.
- She then likes a title of interest, and she begins playback. This is facilitated by a set of Playback API backed its own set of Playback Domain Services.
- So, let’s keep this view of the architecture in mind. As we go through the talk, we will specifically call out the technical aspects of the API Service architecture; So that we can compare and reason about the previous architecture and current architecture choices.
- At the high level, we recommend thinking about three fundamental principles: Identity Type1/Type2 Decisions Evolvability
- Let’s start with Identity
- First and foremost, ask yourselves why your service exists. If you removed your service from your ecosystem, what would be the impact. Go a step further, and ask why your service exists with respect to why your company exists.
- Let me paint a picture for you folks: Why Netflix exists? Netflix’s goal is to lead the Internet TV revolution to entertain billions of people across the world. Within Netflix, we have the product engineering organization. Why does that exist? Netflix Product Engineering’s goal is to maximize user engagement of Netflix customer from signup to streaming. And then we go one level down. Within Product Engineering, we have the Services Engineering org. Services Engineering exists to “enable non-member, discovery, playback functionality”. -
- Within the Services Engineering Org, we have the API Service whose identity is to deliver Acquisition, Discovery and Playback functions with very high availability As we went through this process of hierarchically determining the role our each organization and its associated services, the first thing we debated was that does it still make sense for the API Service to support all API functions. With three major functions of Netflix rolled into one service, and each becoming complex over the years, we realized that we had unintentionally made the service complex.
- In essence, we didn’t really apply the single responsibility principle, and we let multiple identities getting rolled up into a single service.
- This helped us make our first decision in our re-architecture! Split the API Service into separate services dedicated for each major function. We believe this will enable us to lead each of the API Service to reach its potential in its corresponding functional area.
- So in our identity hierarchy, we have a specific Playback API Service, under Services Engineering, whose sole purpose is to deliver Playback lifecycle 24/7
- In order to deliver the playback functionality, Play API orchestrates amongst three sets of services we have a service which exists to decide the best playback experiences, we have a set of services which exists to authorize every playback, and set of services which exists to collect playback data for business intelligence.
- This picture captures the essence! :-)
- If you remove the Playback API service, it introduces coupling between the playback services and also exposes all the underlying playback services to the requests from devices.
- This helped us come up with a well-defined identity for our Play API Service. Its purpose is to orchestrate the Playback Lifecycle, while providing the necessary abstractions for the device and Playback Services. How do you know you got the identity right? Typically, rule of thumb is - you ask any two person in your organization, they should be able to mention the identity of your service. If not, you have still not gotten the identity right?
- The first guiding principle which you should use for your architecture is - define simple singular identities for your services. The identity relates to and complements the identities of the company, organization and its peer services.
- Next fundamental principle is Type 1 and Type 2 Decisions
- Jeff Bezos, in his annual shareholders letters calls out the type of decisions which sustains innovation at Amazon: “Some decisions are consequential and irreversible or nearly irreversible – one-way doors – and these decisions must be made methodically, carefully, slowly, with great deliberation and consultation. If you walk through and don’t like what you see on the other side, you can’t get back to where you were before. We can call these Type 1 decisions…”
- “... But most decisions aren’t like that – they are changeable, reversible – they’re two-way doors. If you’ve made a suboptimal Type 2 decision, you don’t have to live with the consequences for that long. You can reopen the door and go back through. Type 2 decisions can and should be made quickly by high judgment individuals or small groups.” This is a great wisdom which we can apply to architecture designs. Identifying what constitutes a Type 1 decision and committing to that decision upfront has serious implications on the success of your architecture.
- At Netflix, we believe the following questions are key Type 1 decisions which we need to get right at the very beginning: Shared libraries and Communication Synchronous vs Asynchronous Data Architecture
- When we talk about shared libraries, there are typically two types Shared libraries which hosts common functions. Examples: Utilities jar, Caches, Metrics etc We also have client libraries which are used for inter-service communication between services
- Shared libraries often introduce some form of coupling between services; so we need to be careful about what we think is approprite level of coupling
- Since all our microservices originated from a monolithic code base, we have high proliferation of shared libraries across our services. For instance, we have a streaming utilities jar. This jar runs on 80% of our microservices. To make the situation worse, this jar has 121 dependencies. Even if you use one small utility class within this library, you have exposed your service to all these 121 libraries
- When we have hundreds of common libraries all running in separate services across network boundaries, we have created a Distributed Monolith. Distributed Monolith is worse than a monolith because, it has all the ill-effects of a monolith, in addition to having to worry about operating them separately!
- Sam Newman captures this very well in his book “Building Microservices” - He says: “The evils of too much coupling between services are far worse than the problems caused by code duplication
- Another form of coupling comes with respect to client libraries. So Play API Service talks to Play Decision Decision via the Decisions client. Whenever the Play Decision Service becomes unavailable, a fallback is executed from within the Play API Service via the Play Decision Client
- The API Service couldn’t talk to the Playback Decision Service for 5 minutes, it resulted in a fallback getting executed via the Playback Decision Client sitting inside the API Service. As you can see here, during that time, latencies of API Service went through the roof. The service had increased memory pressure, really high CPU utilization and during that time, its availability went significantly down!
- So what has happened here is that while we have a domain based bounded context, which isolates business function from each service, the operational context is leaking over to the calling services.
- Operational Coupling is tolerable if some services/teams are not yet ready to own and operate a highly available service yet. In fact, the API service with high operational coupling, served Netflix well for over many years.
- And API Service being an aggregator of several microservices, consumed dozens of such shared libraries. The end result was very high Operational coupling with the potential to take down the API service itself
- There is one more disadvantage with high proliferation of shared libraries; it encourages services to remain in java. Netflix has historically been a java shop, but we are slowly exploring polyglot options. Say, a team feels that concurrency primitives in Go Language was better suited for their domain, they would have to write clients to all the services they need to communicate with - these clients have to be at feature parity with java and have to be continuous maintained. This was such a high friction point which prevented teams from even exploring such an option!
- Those are some of the issues to consider w.r.t Coupling. Next, lets look at Inter-service Communication - In our previous architecture, the services are written on top of Jersey framework and client communicates to the services via a REST interface. REST over HTTP 1.1 served us well for several years, this had limitations: Once the connection is established, clients always initiates the communication; so it was unidirectional Consequence was that it only could support Request/Response style APIs Choosing the right form of Network communication framework is a type 1 decision because it could take years to move to a different framework. So we looked at our future use-cases and we saw that some of our APIs would benefit from moving beyond Request/Response type patterns.
- Drawing from these experiences, we sat down and came up with four requirements Operationally “thin” clients Meaning, we want to the clients which is used for communicating to a service have almost no special logic, no heavy fallbacks, and minimal depedencies No or limited shared libraries We will pick and choose the shared libraries we want to inherit for the Play API service. Any libraries which had a huge dependency tree had to be broken down or given a dedicated service of its own Auto-generated Data contracts This means we define the service in an Interface Definition Language, and have tools to auto-generate the client for the required language(s) This disincentivizes teams to hand-write the clients, which in turn reduces the scope of leaky abstractions. Network protocols with support for bi-directional communication, so that we can look beyond request/response style APIs
- We didn’t have REST vs RPC as a requirement because, At Netflix, when most use-cases were modelled as Request/Response REST was a simple and easy way of communicating between services; so choice of REST was more incidental rather than intentional Most of the services were not following RESTful principles. In many cases, the URL didn’t represent a unique resource, instead the parameters passed in the call determined the response - effectively made them a RPC call We were agnostic to REST or RPC as a way to correspond between services as long as it meets our requirements
- Based on the requirements, we chose gRPC as our framework of choice. gRPC gave us ability to auto-genarate clients with polyglot support. It supports Netty + HTTP/2 for bi-directional communication; We did have to explicitly build support for ecosystem compatibility in-house.
- So with respect to Shared libraries and Communication, this is how the previous architecture compares to the current one.
- So for your next architecture, consider “thin” auto-generated clients with bi-directional communication. Also minimize code reuse across service boundaries to reduce coupling
- The next type 1 decision to consider is determining whether to build to synchronous or asynchronous architecture.
- To understand the choice between Asynchronous and Synchronous, lets consider a example. Say, we have a getPlayData API. It takes in three inputs, customerId, deviceId and a titleId. It then fetches CustomerInfo corresponding to the customerId, fetches the DeviceInfo corresponding to the deviceId, then passes the enriched information to another service to fetch and return the PlayData.
- A typical Synchronous Architecture looks like this: Service has a thread pool dedicated to handle all the incoming requests. Each request gets a dedicated thread for its execution. Separately, for each of the clients a service consumes, it allocates a dedicated thread-pool to manage all outgoing communication.
- So, when a request for PlayData arrives, it gets a dedicated execution thread. First it needs to make a call to the Customer Service. So it schedules an outbound request with the client thread pool dedicated for the customer service calls. And then blocks for a response. The client then communicates the request to the Customer Service, as soon as it receives the response from the Customer Service, it unblocks the execution thread. The same pattern continues for getDeviceInfo and for decidePlayData. Once the playdata can be assembled, the execution completes and the thread is given back to the request handler.
- So in this architecture, there is a blocking request handler; and a blocking client I/O. A thread is retained for the entire duration of the request processing and all outgoing requests block the execution flow.
- This works reasonably well for Request/Response APIs where latency is not a critical concern When service consumes limited number of clients
- I have been mentioning Request/Response APIs a few times now. Do we have use-cases which doesn’t fit the Request/Response model? For instance, let's take the example of a service where you can request for a play-data of title X. You can make a request for one title and receive the play-data for that title. This would be a Request/Response pattern You can make a request for titles X, Y, Z. The service could respond as and when the the response becomes available. This would be a request/stream pattern Or you could fire off requests for titles X, Y and Z separately, the service could collate all the requests, and send a single response back. This would be a stream/response pattern Finally, you could fire off requests as and when you are ready, the service could respond as and when it is ready. This would be a bi-directional stream/stream pattern If you think your use-case fits in any of the stream patterns, you might benefit from an asynchronous architecture.
- An asynchronous architecture could look like this: There is a event loop which manages incoming communication There are set of worker threads, typically a function(no of cores in the instance), which is used for executing different pieces of application logic And there are event loops per client type which manages the outgoing communication
- To get full benefit of the asynchronous architecture, we need to code up the getPlayData function call differently. We want to compose the execution into multiple execution units. So in this implementation, one execution unit handles retrieving CustomerInfo, another execution unit handles retrieving Device Info, and a third execution unit acts on both the customer info, and device info to fetch the play data. When the third execution unit completes the processing of the request completes.
- In this architecture, when a request comes in Request/Response event loop reads the data off the network, and when a request unit has arrived, it notifies a worker thread The worker thread then sets up a sequence of events to be executed and then immediately returns. As the events unfold, customerInfo is fetched, deviceInfo is fetched and when both are available, playdata is fetched. Once a response is ready, it notifies Network event loop and the data is written back to the network
- In this architecture, when a request comes in Request/Response event loop reads the data off the network, and when a request unit has arrived, it notifies a worker thread The worker thread then sets up a sequence of events to be executed and then immediately returns. As the events unfold, customerInfo is fetched, deviceInfo is fetched and when both are available, playdata is fetched. Once a response is ready, it notifies Network event loop and the data is written back to the network
- In this architecture, when a request comes in Request/Response event loop reads the data off the network, and when a request unit has arrived, it notifies a worker thread The worker thread then sets up a sequence of events to be executed and then immediately returns. As the events unfold, customerInfo is fetched, deviceInfo is fetched and when both are available, playdata is fetched. Once a response is ready, it notifies Network event loop and the data is written back to the network
- In this architecture, when a request comes in Request/Response event loop reads the data off the network, and when a request unit has arrived, it notifies a worker thread The worker thread then sets up a sequence of events to be executed and then immediately returns. As the events unfold, customerInfo is fetched, deviceInfo is fetched and when both are available, playdata is fetched. Once a response is ready, it notifies Network event loop and the data is written back to the network
- In this architecture, when a request comes in Request/Response event loop reads the data off the network, and when a request unit has arrived, it notifies a worker thread The worker thread then sets up a sequence of events to be executed and then immediately returns. As the events unfold, customerInfo is fetched, deviceInfo is fetched and when both are available, playdata is fetched. Once a response is ready, it notifies Network event loop and the data is written back to the network
- Workflow spans multiple threads, All context is passed as messages from one processing unit to another. If we need to follow and reason about a request, we need to build tools to assemble the workflow. None of the calls can block
- In this architecture, we have a asynchronous request handler and non-blocking I/O
- So the question to ask is - do you have a streaming use-case which can greatly enhance your service domain? If so, going all-in on asynchronous architecture might make sense.
- In the case of the Play API Service, we didn’t have an immediate use-case for streaming. However there are some business innovation ideas in the works which might benefit from such design. So we modelled a mix of synchronous-asynchronous architecture. Here, we decided to make the Network Client I/O (both incoming and outgoing) asynchronous. And we made the request processing happen in a dedicated thread per request. In the near future, our goal is to experiment with fully asynchronous for a focussed API, learn from that experiment and use that learning to determine if we want to go fully async or not.
- So if most of your APIs fit the request/response pattern, consider a synchronous request handler with an asynchronous I/O
- And the final type 1 decision to consider is the Data Architecture
- If you are splitting apart a monolith into services, or starting a new service from fresh, give data architecture the first class berth it deserves. Without an intentional Data Architecture, Data becomes its own monolith
- What a Data Monolith looks like. This is our previous Data architecture of the API Service API Service depends on Data from different sources for its business logic. It consumes these data sources as shared libraries. These libraries periodically refreshes the data and loads them into memory.
- The first observation we made was that only a small fraction of the loaded data was actually being used by the Application logic
- Each Data source models are freely used across classes and libraries ->which in turn introduced inappropriate coupling. Without an abstraction layer, If we had to replace a data source, it meant several weeks of refactoring.
- Whenever the data got refreshed, it resulted in unpredictable performance characteristic. There will be a surge in CPU utilization, increase in memory pressure, longer GC pauses; all inadvertently affected the throughput and latency of the service
- Our application logic is built and deployed as immutable units. However, data was getting updated dynamically in these boxes without any validation. It had the impact of bringing the service down All these observations told us that, since we were not intentional about the data architecture, we inadvertently built a data monolith.
- So when we started our re-architecture, we debated how to decouple the service from the data it consumes. We took a cue from the old adage of Computer Science design - “All problems in computer science can be solved by another level of indirection.”
- We mapped out all the data sources which API service depended upon. We created a separate Data Loader Service which would consume these data sources as-is and when there is a update, pick the data which we cared about, and saved it in our data store. Separately we wrote a simple data service which would take in a key for the data, lookup the store and serve it back to the Play API Service.
- This addressed each of the problems we discussed before No in-memory data update - Only the data which was being used by the service is stored In the absence of asynchronous data loads, performance characteristics of the service became a direct function of request load The number of shared libraries which the customer facing API service need to integrate with is significantly reduced
- If you think building such an indirection is an overkill for your use-case, at least consider building a anti-corruption abstraction layer per data source, so that you can evolve the architecture later as you see fit.
- We spent close to 80% of our design phase debating and aligning on these type1 decisions.
- For Type 2 decisions, choose a path, experiment and fix-forward. For instance, among the dozen APIs which Play API exposes, we built one API first, experimented with different types of integration testing, deployment pipelines, monitoring and used that learning for the next API.
- Guiding Principle: We believe in identifying and committing to Type 1 decisions of our architecture upfront
- Evolutionary Architecture is a term coined and evangelized by Neal Ford and Rebecca Parsons at ThoughtWorks. They define it as such: “An Evolutionary Architecture supports guided and incremental change as first principle among multiple dimensions”. There are three aspects which are emphasized here. First the architecture is designed for change, for evolution. Secondly, every change is guided. And third, we should be evolving across multiple dimensions
- By choosing a microservices architecture, we already allow for evolvability across multiple dimensions. For instance, Customer Service can change independently of the Device Service which can change independently of the Playback API Service.
- A merit of a good architecture is how easy and simple it is to extend, complement and replace its components over time. In short, evolvability. Within a scope of the Playback API service, lets analysis how evolvable we are. In terms of going all-in on Asynchronous, we feel we are in a much better place than our previous architecture; Same with choosing an alternate language choice, like Go over Java. We are also good with Additional Data Sources and building out a streaming API. These are our known unknowns. We don’t know if we are going to need it, but if we do we have a good handle on it.
- Containers & Serverless are something which we are starting to dabble with, but we don’t yet have a good handle on. As we explore these more deeply, there will definitely be some aspects of it which would fall under the category of “unknown unknowns”
- Most architectures, when well executed, do a good job for the first few months of their inception. As new business use-cases present itself, complexity seeps in - often at the cost of the principles, which guided the original architecture. This is why Evolutionary Architecture emphasizes guided change. So how do we make sure that any change we make doesn’t break its original guidelines; and if it indeed breaks, it becomes a conscious choice?
- This is where the role of fitness functions come into play. Every Architecture Design has core set of goals - usual suspects include Availability, Reliability, Resilience, Throughput, Low Latency. At Netflix, we also deeply care about Simplicity, Productivity, Observability, and Evolvability. These goals themselves are interesting, sure, but it doesn’t provide us enough. What we want is a relative importance of each goal with respect to one another.
- For example, this is what our Fitness Function looks like for Play API Architecture. Your fitness function would be totally different catered to your particular use-case.
- Allowing fallbacks typically increases reliability. A service is down, a fallback is executed to keep the system resiliant. But it adds additional complexity to the calling service in terms of operating the fallback scenario. If fallbacks involve calling other services or executing a CPU intensive logic, then it comes at the cost of simplicity. So in that case, we choose to be simple.
- One way to achieve high throughput, is to introduce some form of caching. In some cases, we have noticed having a in-memory cache gave us a hit rate of > 50%. While it makes us efficient. If we are in a situation where we need to horizontally scale our service, we often have to employ some cache warming strategies before we can let new instances take traffic. So if the choice is between throughput and scalability, we choose scalability
- If we make all our interactions asynchronous, we reduce or eliminate the time spent in waiting for a response, which in turn would bring down the latency. However, if we did that without building tools to understand the request flow, we lose observability. So between Observability and low latency, we choose observability
- While we use the goals fitness function to guide us when we are making a intentional change, we also wanted something to ensure that an unintentional change doesn’t break our architectural principles. So we have another set of fitness functions which keeps us in check. Some of these are pro-active checks - for instance in order to ensure that we consume clients with less than “n” dependencies, we have a unit test to verify any new dependency we take in. Latency and Availability are gating factors which we use to gate a push to production. Some are reactive. We monitor “merge to deploy” time periodically . Similarly CPU to RPS ratio is something which we keep a tab on, and if there were any degrations, we don’t necessarily use that as a gating factor for production push.
- Coming back to the graphs we saw at the very beginning: By Splitting our API Service into three separate Services with singular identities, each designed for evolvability and a goal of 4 9s of availability, we feel confident that we can significantly reduce the number of outages caused by the API Service. And on the other hand, as Netflix innovates, and as we add more and more features, we need to continue to make changes to our architecture. The Fitness functions which we have defined would keep us in check as we evolve and adapt our architecture.
- To summarize, consider building an Evolutionary Architecture for your next architecture. Here are three big ideas to take away from this talk: Build a strong domain focussed identity for your service; Iterate them to get it right and always keep the identity in picture for your future iterations Identify your Type1 and Type2 architectural decisions; and spend 80% of your time debating the Type1 choices Define fitness functions to guide your architectural evolution. Thank you for listening! I am eager to take questions now.