Als PDF, PPTX herunterladen



























![Insert/Update Data
cr> insert into locations values
('2013-09-12T21:43:59.000Z', 'Blagulon Kappa is the
planet to which the police are native.', 'Planet',
'Blagulon Kappa', 7)!
INSERT OK, 1 row affected (... sec)
cr> update locations set race['name'] = 'Human' where
name = 'Bartledan'!
UPDATE OK, 1 row affected (... sec)](https://image.slidesharecdn.com/dchh2013-131107185247-phpapp02/75/Warum-ne-Datenbank-wenn-wir-Elasticsearch-haben-39-2048.jpg)
![Queries
cr> select name, race['name'] from locations where race['name'] = 'Bartledannians'
+-----------+----------------+!
| name
| race['name']
|!
+-----------+----------------+!
| Bartledan | Bartledannians |!
+-----------+----------------+!
SELECT 1 row in set (... sec)!
!
cr> select count(*), kind from locations group by kind order by count(*) desc,
kind asc!
+----------+-------------+!
| COUNT(*) | kind
|!
+----------+-------------+!
| 5
| Planet
|!
| 4
| Star System |!
+----------+-------------+!
SELECT 3 rows in set (... sec)](https://image.slidesharecdn.com/dchh2013-131107185247-phpapp02/75/Warum-ne-Datenbank-wenn-wir-Elasticsearch-haben-40-2048.jpg)




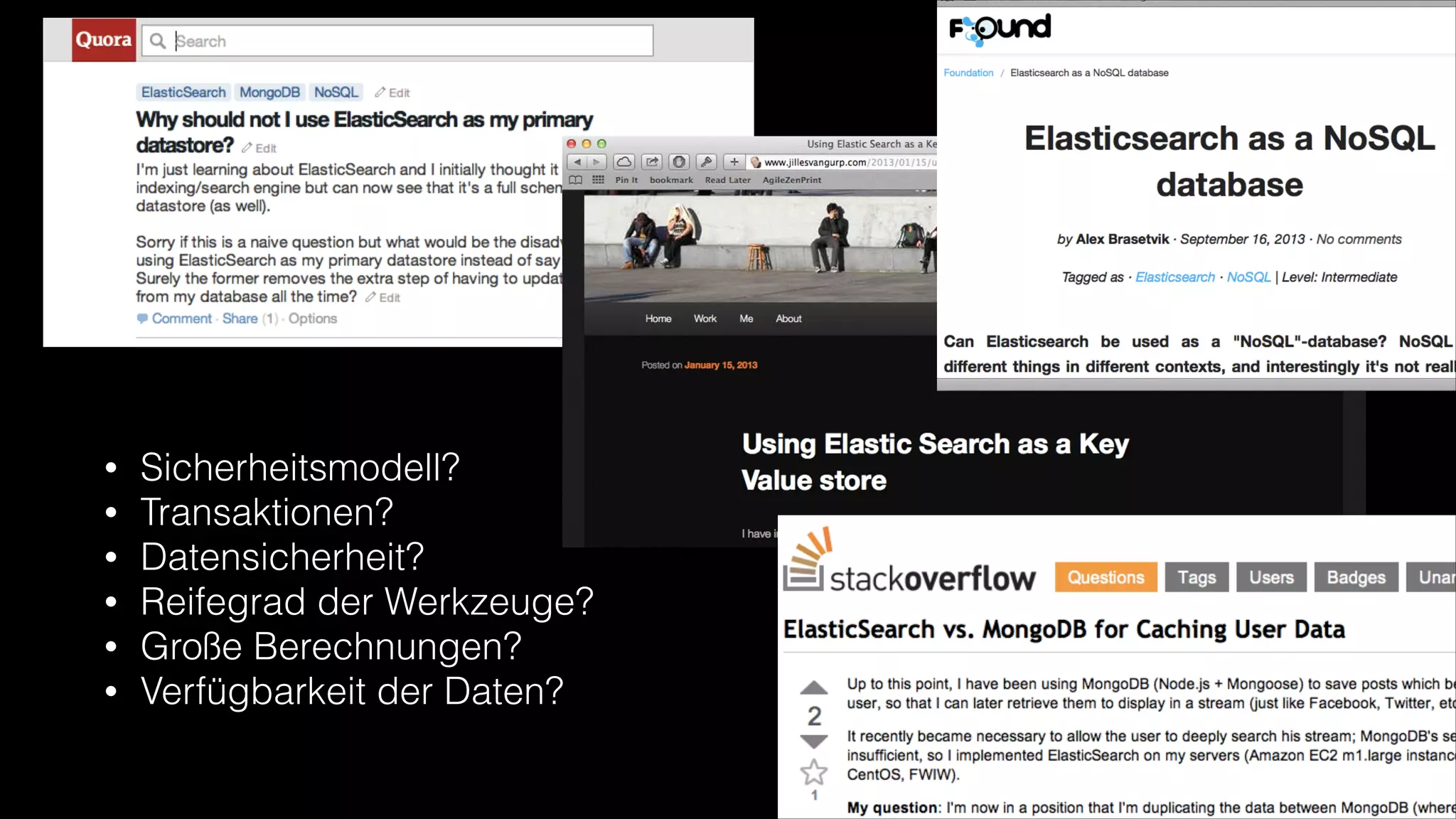
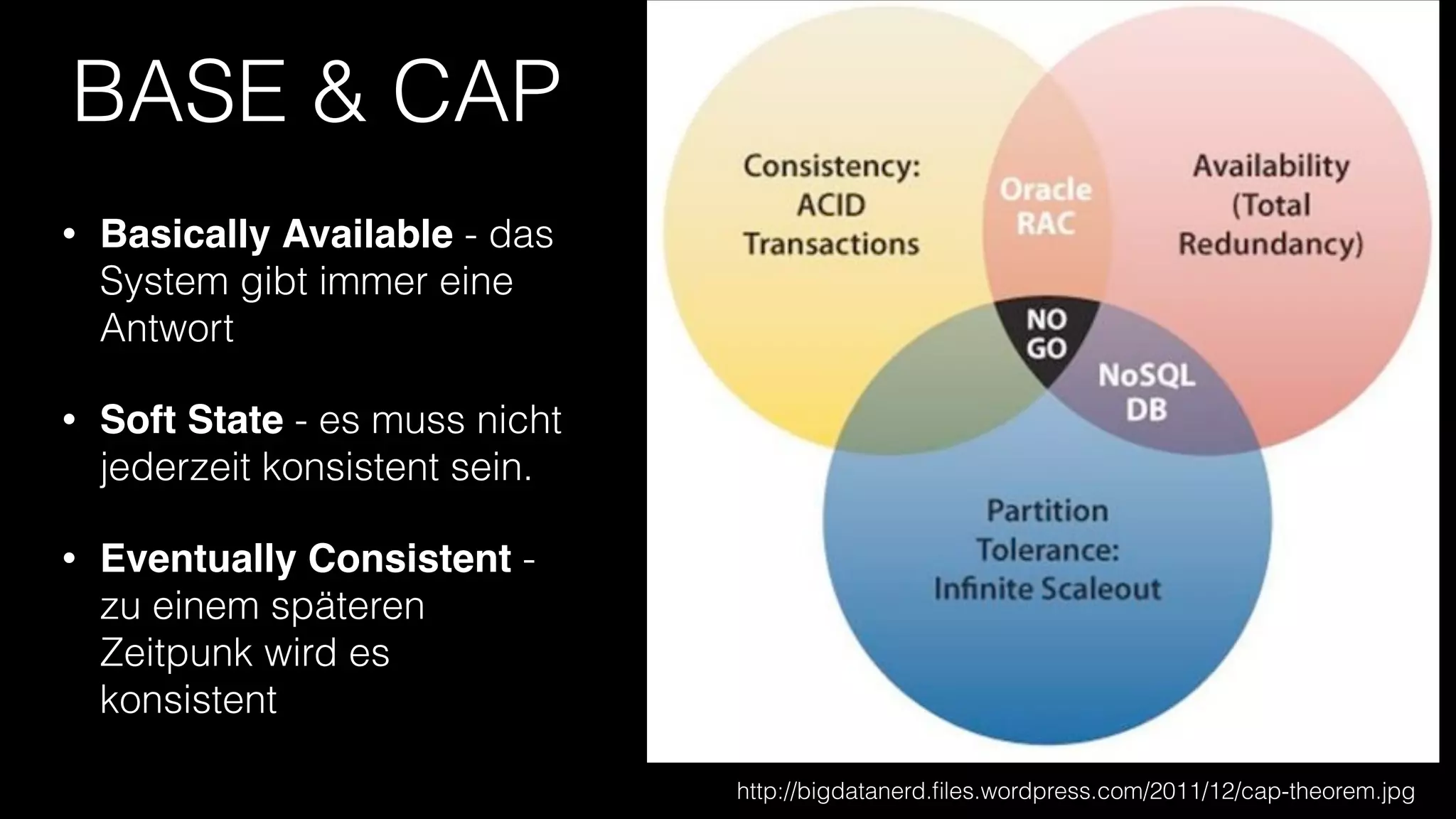
Das Dokument erörtert die Vorzüge von Elasticsearch im Vergleich zu traditionellen Datenbanken, hebt Möglichkeiten wie Echtzeitsuche, verteilte Architektur und Skalierbarkeit hervor. Es diskutiert zudem Herausforderungen wie Datenintegrität, Transaktionsmanagement und die Vor- und Nachteile von schemalosen NoSQL-Datenbanken. Abschließend werden Anwendungsbeispiele und technische Details zu einem spezifischen Implementierungsansatz vorgestellt.
























































