Als PDF, PPTX herunterladen


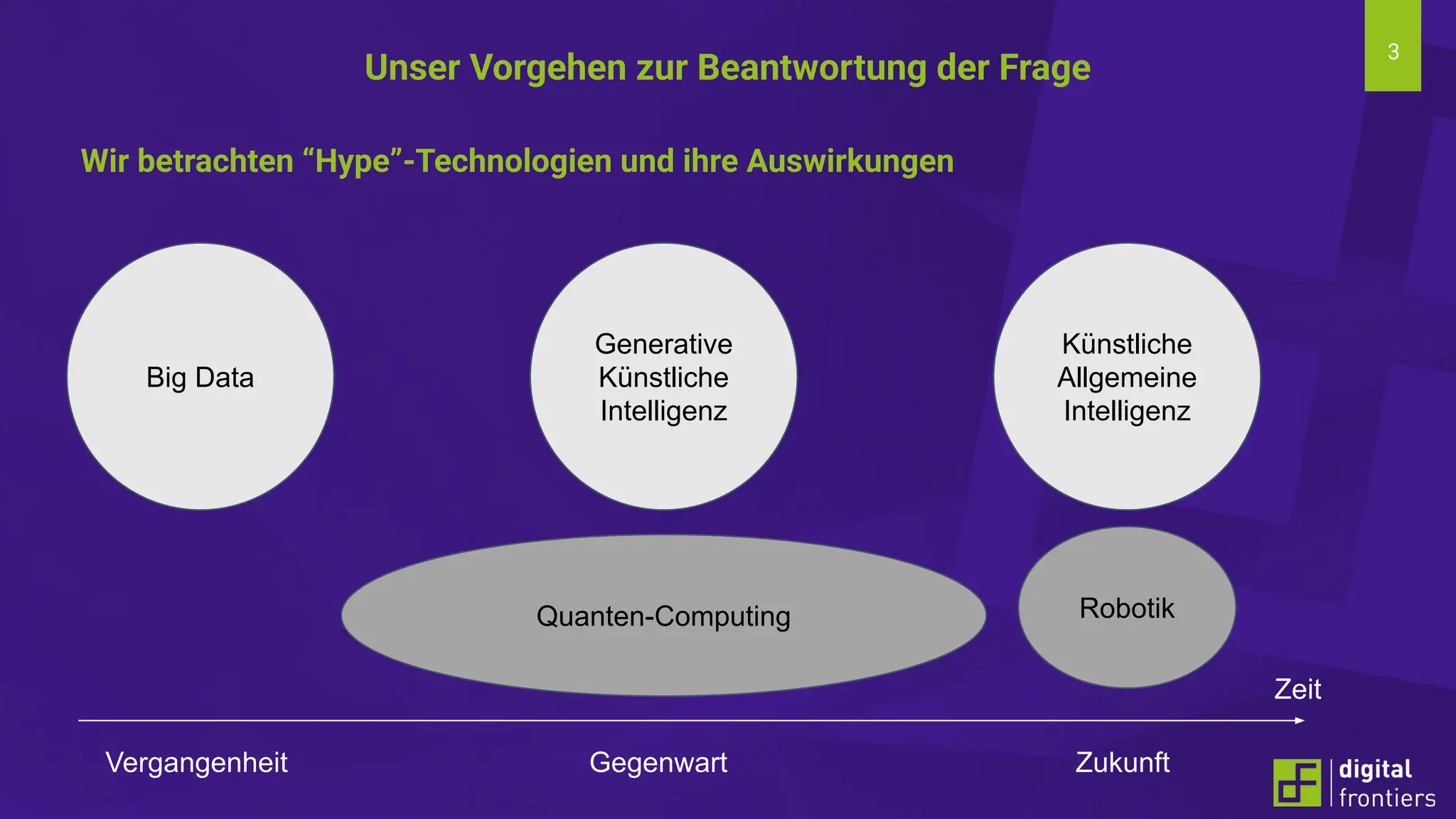
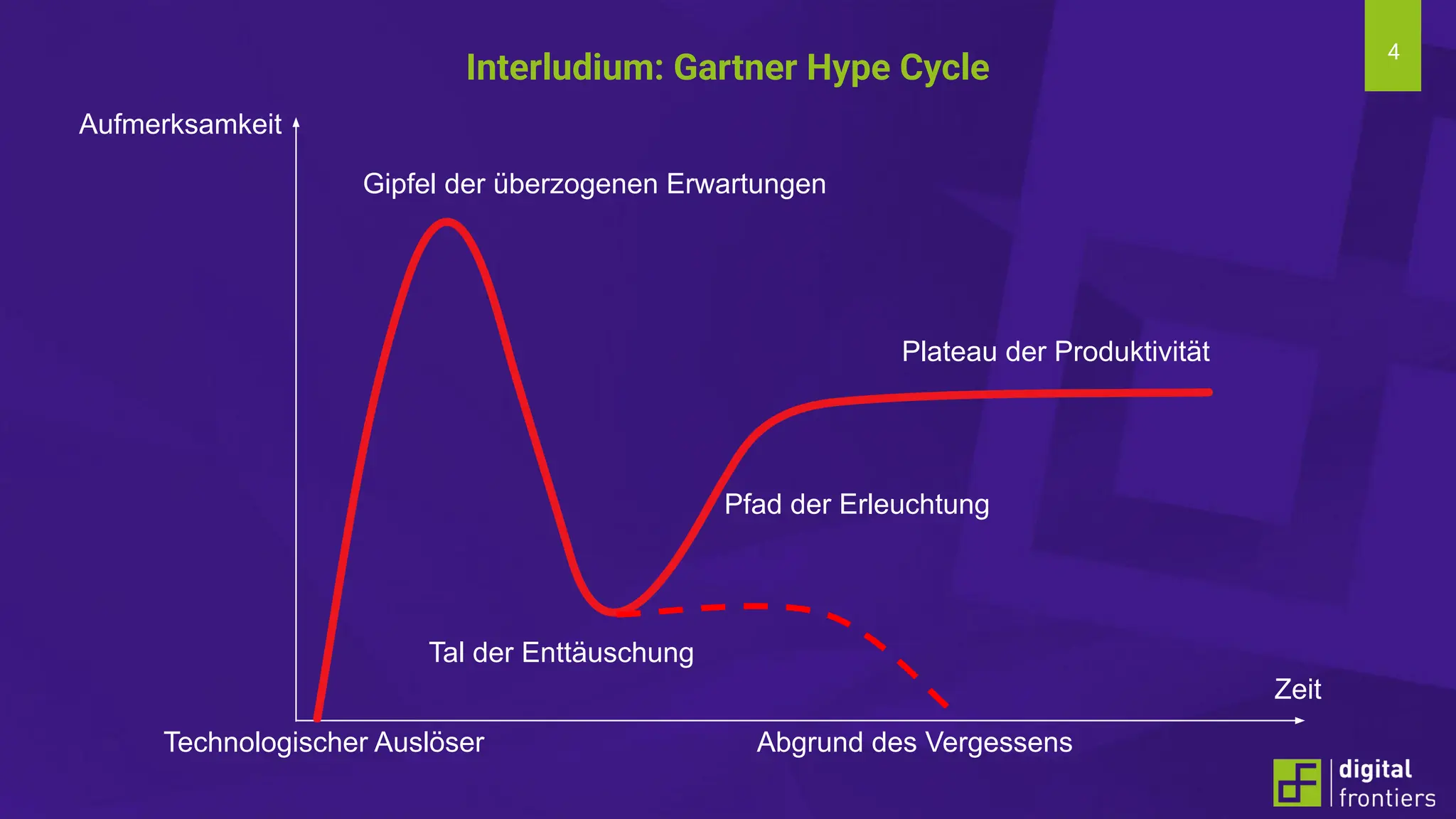


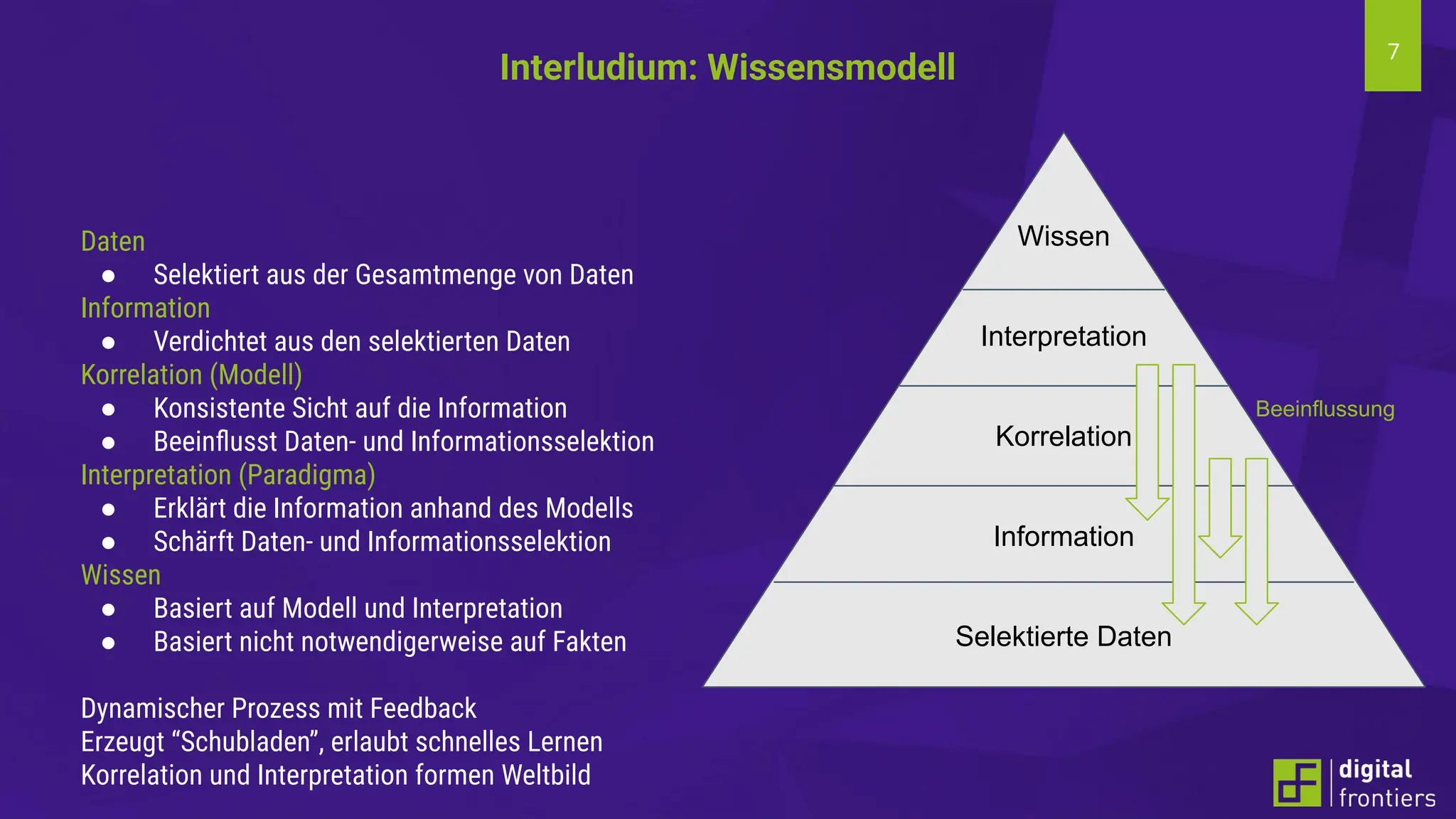
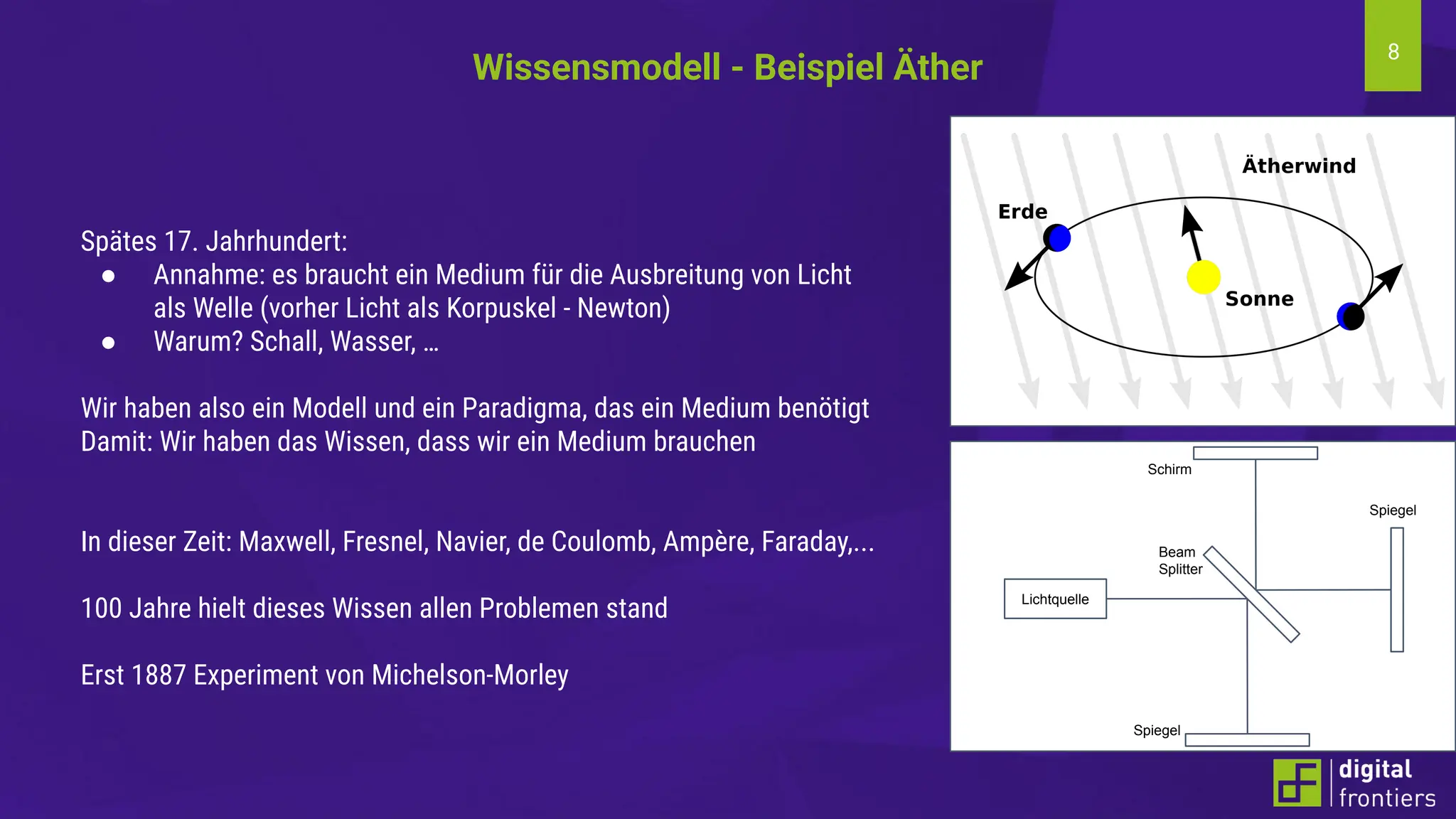

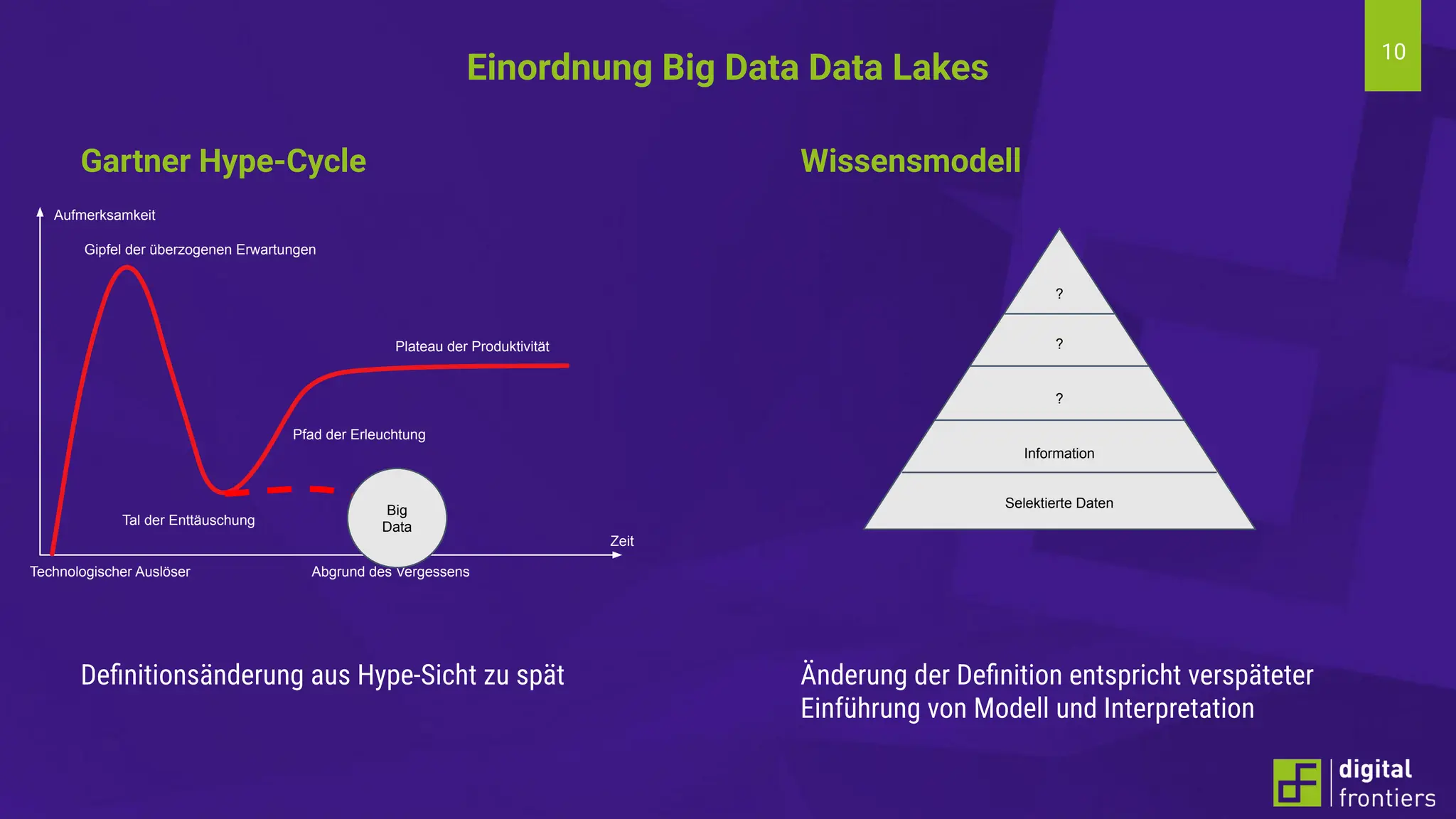




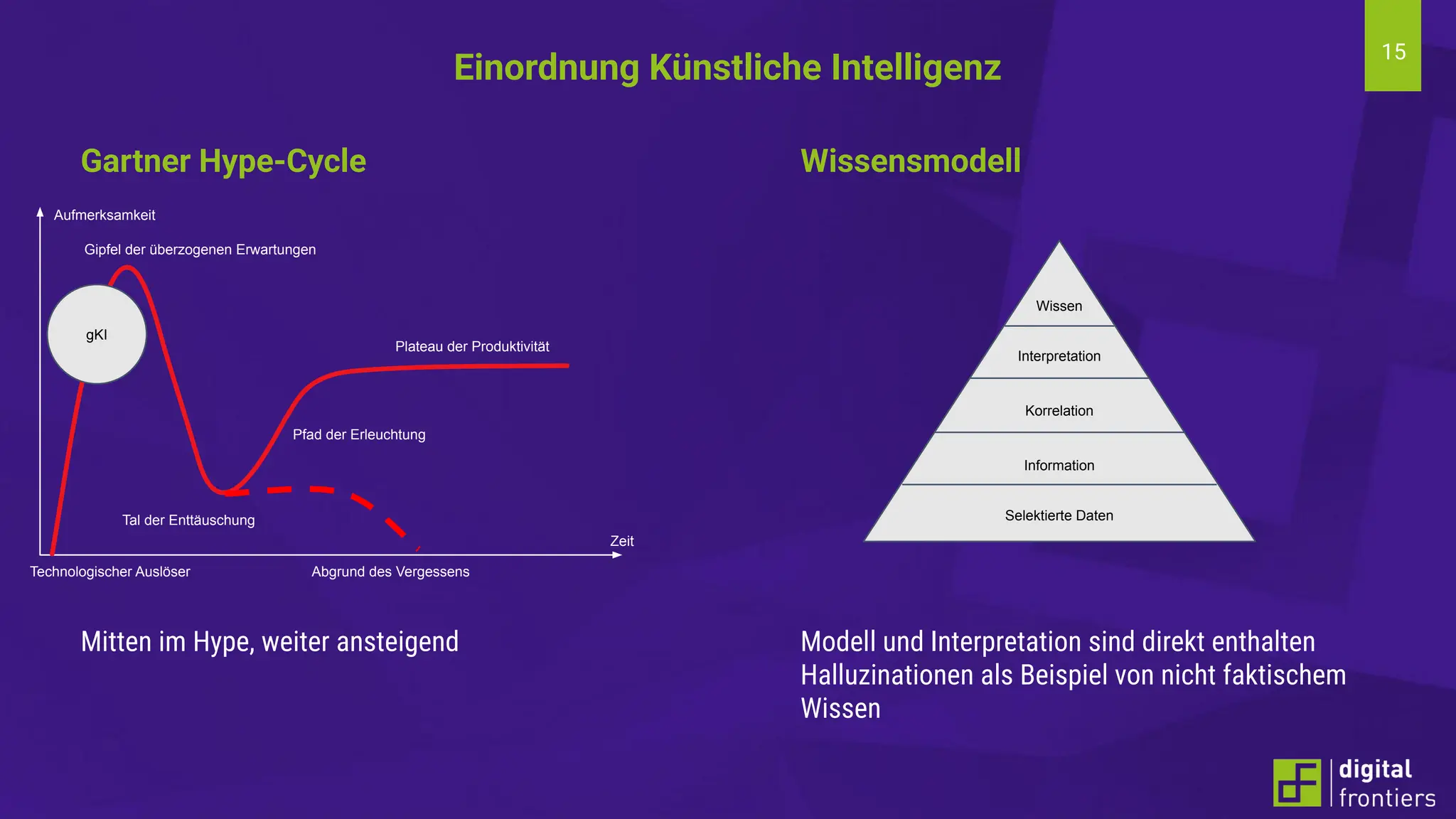









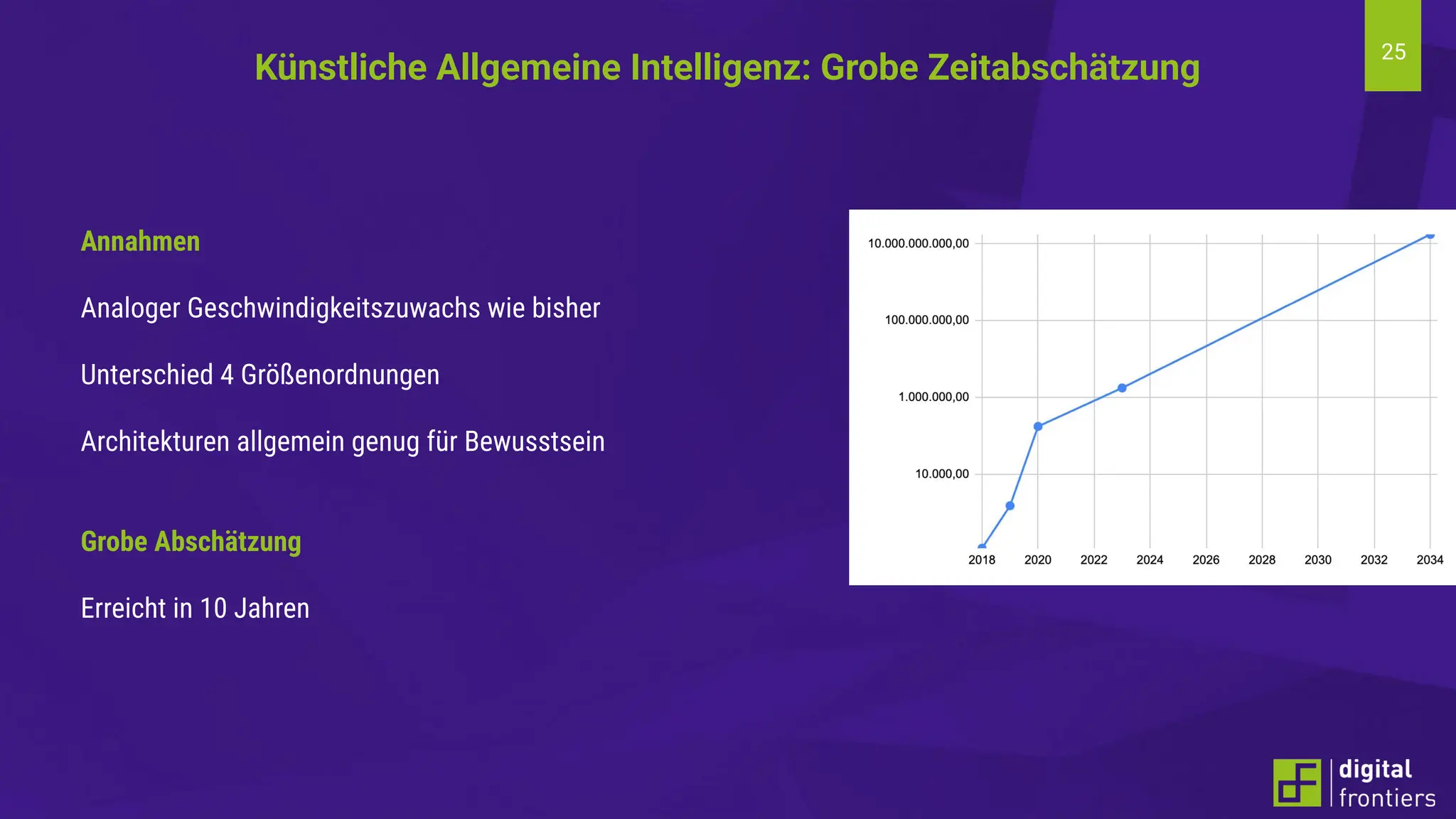




Am 21.06.2024 fand im Institut für Kunststofftechnik Darmstadt (ikd) der 16. Darmstädter Kunststofftag statt. Das Thema der diesjährigen Tagung lautet „Digitalisierung und Nachhaltigkeit“. Prof. Dr. Thomas Schröder konnte auch in diesem Jahr wieder namhafte Referenten aus der Industrie gewinnen. Erleben Sie innovative Beiträge zu den Themen Big Data, Data Literacy, AI, Machine Learning & Co auf dem Campus der Hochschule Darmstadt am Institut für Kunststofftechnik Darmstadt.




































